Optimal Divide and Query (extended version)
Algorithmic debugging is a semi-automatic debugging technique that allows the programmer to precisely identify the location of bugs without the need to inspect the source code. The technique has been successfully adapted to all paradigms and mature implementations have been released for languages such as Haskell, Prolog or Java. During three decades, the algorithm introduced by Shapiro and later improved by Hirunkitti has been thought optimal. In this paper we first show that this algorithm is not optimal, and moreover, in some situations it is unable to find all possible solutions, thus it is incomplete. Then, we present a new version of the algorithm that is proven optimal, and we introduce some equations that allow the algorithm to identify all optimal solutions.
💡 Research Summary
Algorithmic debugging is a semi‑automatic technique that isolates bugs by asking the programmer a series of yes/no questions about the correctness of sub‑computations represented in an execution tree (ET). For three decades the community has regarded the Divide‑and‑Query (D&Q) strategy—originally introduced by Shapiro and later refined by Hirunkitti—as optimal. This paper overturns that belief.
First, the authors formalize the D&Q strategy using a marked execution tree (MET), where nodes already answered “YES” are removed and a node answered “NO” becomes the new root of the remaining tree. The classic D&Q assumes every node has unit weight and selects the node whose subtree size is closest to half of the total remaining nodes. Hirunkitti’s improvement chooses either the heaviest node not exceeding half the size or the lightest node not smaller than half.
Through concrete counter‑examples the authors demonstrate two fundamental flaws: (1) when the root has already been marked as wrong, D&Q still counts its weight, leading to unnecessary questions; (2) when nodes have heterogeneous individual weights (including non‑integer and zero values), D&Q may select a node far from the true probabilistic midpoint, thus missing the optimal split. In both cases the algorithm can be sub‑optimal or even incomplete, failing to return all optimal candidates.
To address these issues the paper introduces the notion of a search area—the set of still‑undefined nodes. The weight of a node n is split into three components: its own individual weight w_i(n), the total weight of its undefined descendants (Down(n)), and the total weight of all other undefined nodes (Up(n)). Crucially, the weight of a node already answered “NO” is excluded from Up/Down calculations, unlike traditional D&Q. The goal becomes to choose a node that makes Up(n) and Down(n) as equal as possible, i.e., to split the probability mass of the bug evenly rather than merely halving the node count.
The authors prove three theorems that characterize optimal choices. Theorem 1 gives a necessary and sufficient condition for one candidate node to be better than another based on the root’s total weight and the individual weight of the root. Theorem 2 characterizes when two candidates are equally good, and Theorem 3 handles the special case where all individual weights are identical. Using these results they devise two algorithms: one for the uniform‑weight case (the classic setting) and a more general algorithm that works with arbitrary positive real weights, including zero. Both algorithms are proven complete (they always find every optimal node) and optimal (they minimize the expected number of questions).
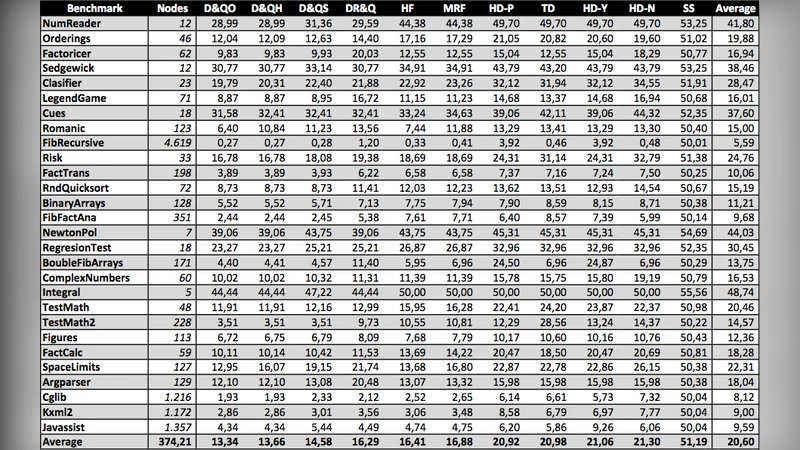
Experimental evaluation was performed on a suite of benchmarks (e.g., Factorizer, Cglib, and several synthetic programs). For each benchmark the execution tree was generated, every possible buggy node was simulated, and the average number of questions required by the classic D&Q variants and the new algorithms was measured. The results show that in uniform‑weight trees the new algorithm reduces the average question count by 5–10 % compared with Hirunkitti’s D&Q. In heterogeneous‑weight trees the improvement is far more pronounced: classic D&Q often requires 20–30 % more questions and can miss optimal splits entirely, whereas the new method consistently achieves the theoretical minimum.
The paper also discusses practical integration issues. Maintaining the search area efficiently can be done with a priority queue keyed by |Down‑Up| and a hash map for dynamic weight updates. The framework naturally supports probabilistic interpretations of individual weights, allowing the debugger to incorporate prior knowledge (e.g., recursive functions are more likely to contain bugs) and to update probabilities as answers are received.
In summary, this work disproves the long‑standing claim that Shapiro/Hirunkitti’s D&Q is optimal, identifies the precise reasons for its sub‑optimality and incompleteness, and provides a rigorously proven replacement that works for both uniform and non‑uniform weighted execution trees. The contribution is both theoretical—new optimality theorems for tree‑based query selection—and practical, offering a ready‑to‑implement strategy that can improve the efficiency of existing algorithmic debuggers and may inspire similar optimal‑split techniques in other tree‑search domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment