Automatic Multi-GPU Code Generation applied to Simulation of Electrical Machines
The electrical and electronic engineering has used parallel programming to solve its large scale complex problems for performance reasons. However, as parallel programming requires a non-trivial distribution of tasks and data, developers find it hard to implement their applications effectively. Thus, in order to reduce design complexity, we propose an approach to generate code for hybrid architectures (e.g. CPU + GPU) using OpenCL, an open standard for parallel programming of heterogeneous systems. This approach is based on Model Driven Engineering (MDE) and the MARTE profile, standard proposed by Object Management Group (OMG). The aim is to provide resources to non-specialists in parallel programming to implement their applications. Moreover, thanks to model reuse capacity, we can add/change functionalities or the target architecture. Consequently, this approach helps industries to achieve their time-to-market constraints and confirms by experimental tests, performance improvements using multi-GPU environments.
💡 Research Summary
The paper presents a model‑driven approach for automatically generating parallel code that runs on hybrid CPU‑GPU architectures, targeting scientific applications in electrical engineering. By leveraging Model‑Driven Engineering (MDE) together with the MARTE UML profile—an OMG standard for real‑time and embedded systems—the authors raise the level of abstraction from low‑level OpenCL programming to high‑level system models. The methodology consists of three main steps: (1) modeling the algorithm and its deployment on hardware using MARTE stereotypes and constraints; (2) transforming the high‑level model into an intermediate representation with the Gaspard2 framework; and (3) automatically emitting OpenCL kernels and host‑side C/C++ code that manage contexts, command queues, and data movement across one or several compute devices.
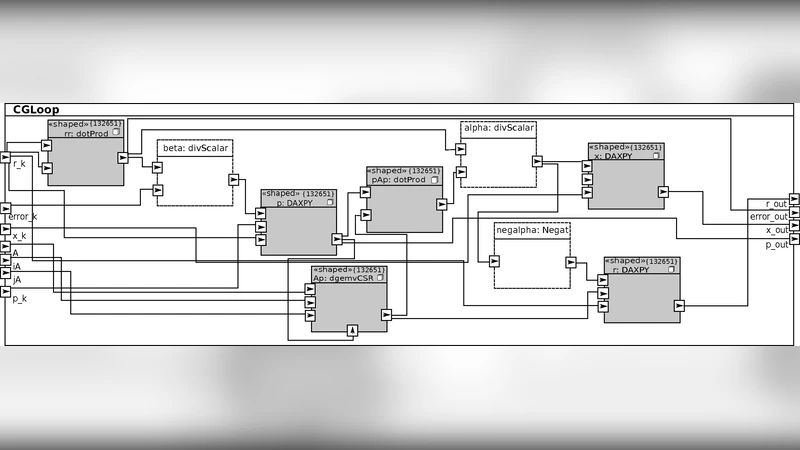
To validate the approach, the conjugate gradient (CG) method—a staple for solving large sparse symmetric positive‑definite systems arising from finite‑element models of electrical machines—is used as a case study. The sparse matrix (N = 132 651, NNZ = 3 442 951) is stored in CSR format, and the CG loop consists of a 132 651‑iteration structure with data‑dependent early termination. In the MARTE model, scalar operations are annotated to run on the CPU, while the repetitive sparse matrix‑vector multiplication (DGEMV) and vector updates are marked as GPU tasks. The transformation chain automatically partitions these tasks across multiple GPUs, generates the necessary kernel code, and inserts synchronization points based on the data dependencies expressed in the model.
Experimental evaluation was carried out on a workstation equipped with a 2.26 GHz Intel Core 2 Duo CPU and an NVIDIA S1070 unit containing four Tesla T10 GPUs. Four implementations were compared: (a) a sequential reference using MATLAB’s built‑in pcg function, and (b) three automatically generated OpenCL versions that run on 1, 2, and 4 GPUs respectively. The measured execution times (including kernel execution and data transfers within the CG loop) were 3.17 s for MATLAB, 0.659 s for the 1‑GPU version, 0.461 s for the 2‑GPU version, and 0.380 s for the 4‑GPU version. These correspond to speed‑ups of 4.81×, 6.87×, and 8.34× over the sequential baseline, and to sustained performance of 1.45, 2.07, and 2.50 GFLOPS respectively. While the scaling is not perfectly linear—owing to additional host‑to‑device and inter‑GPU data transfers—the results demonstrate that automatically generated code can achieve competitive performance on multi‑GPU platforms.
The authors argue that the primary benefit of their approach is a substantial reduction in development time for parallel scientific codes. Engineers without deep expertise in OpenCL can focus on high‑level algorithmic modeling, while the toolchain handles the intricacies of memory layout, kernel generation, and device scheduling. Moreover, because the MARTE model is hardware‑agnostic, the same model can be retargeted to different numbers or types of GPUs, or even to other heterogeneous resources such as FPGAs, simply by re‑running the transformation chain.
Limitations are acknowledged. Automatically generated kernels may still lag behind hand‑tuned implementations in edge cases where aggressive low‑level optimizations (e.g., warp‑level primitives, custom memory tiling) are required. Complex data dependencies that are not easily expressed in MARTE constraints may also demand manual intervention. The current prototype is tied to OpenCL; extending support to newer portability layers such as SYCL or Kokkos would broaden its applicability.
Future work outlined includes integrating hypergraph‑based partitioning to improve load balancing across GPUs, exploring automatic kernel fusion to reduce data movement, and expanding the framework to support cloud‑based heterogeneous clusters. By combining high‑level model reuse with automated multi‑GPU code generation, the paper demonstrates a viable path toward faster time‑to‑market for high‑performance scientific applications in the electrical‑machine domain.
Comments & Academic Discussion
Loading comments...
Leave a Comment