A General Framework for Structured Sparsity via Proximal Optimization
We study a generalized framework for structured sparsity. It extends the well-known methods of Lasso and Group Lasso by incorporating additional constraints on the variables as part of a convex optimization problem. This framework provides a straight…
Authors: Andreas Argyriou, Luca Baldassarre, Jean Morales
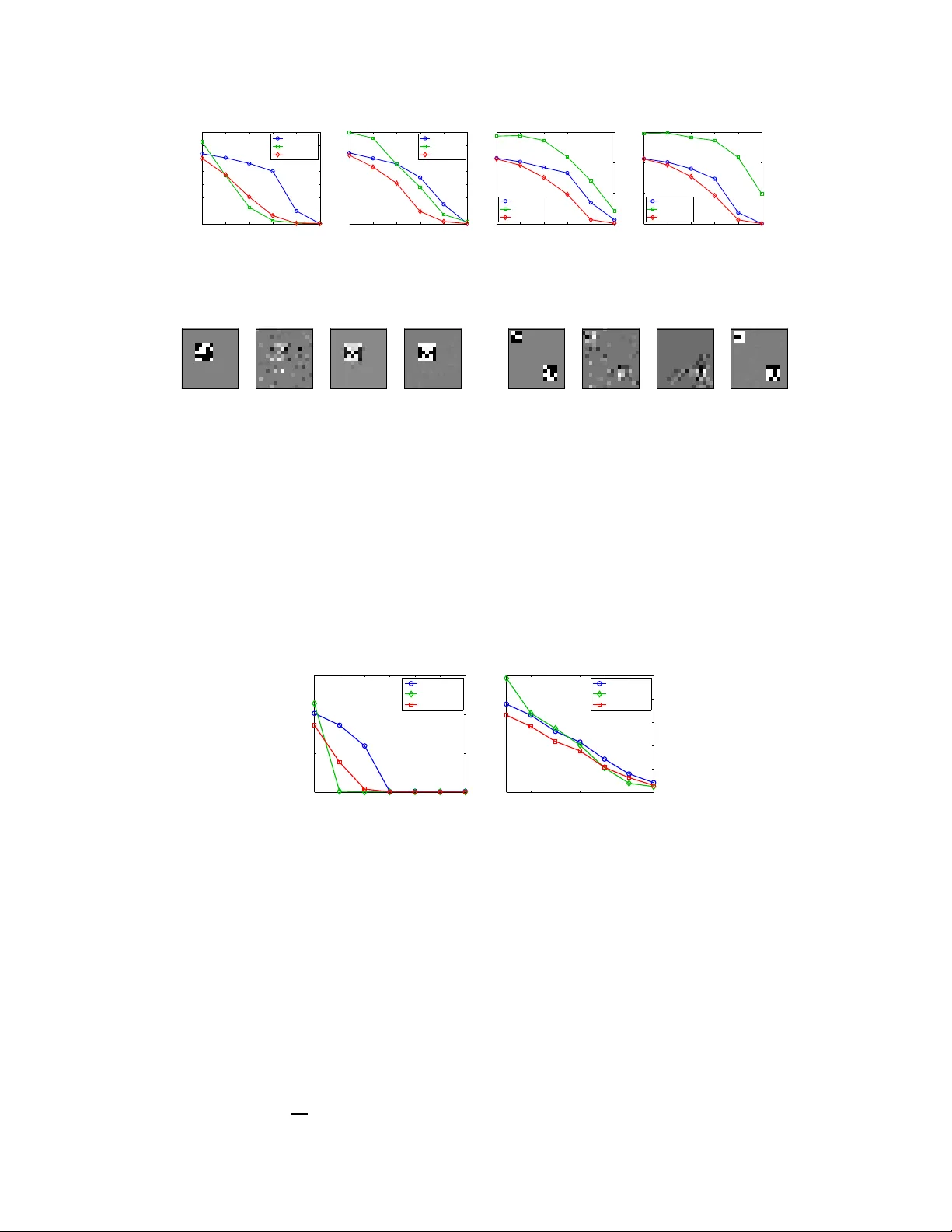
A General Framework f or Structured Sparsity via Pr oximal Optimizati on Andreas Ar gyriou T o yota T echnological Institute at Chicago Luca Baldassarre University College London Jean Morales University College London Massimiliano Pontil University College London Abstract W e study a generalized framework for structur ed sparsit y . It extends the we ll- known methods of Lasso and Group Lasso by incorp orating additional constraints on the v ariables as part of a conve x o ptimization problem. This framew ork pr o- vides a straightforward w ay of f av o uring prescribed spar sity patterns , such as orderin gs, con tiguou s region s and overlapping group s, amo ng other s. Existing optimization metho ds are lim ited to specific constra int sets an d tend to not scale well with sample size and dimensionality . W e propose a novel first or der pr oxima l method , which builds upon results on fixed poin ts and successi ve app roximation s. The algorithm can be applied to a general class of conic and nor m con straints sets and relies on a proxim ity operator subproblem which can be co mputed explicitly . Experime nts on different regression p roblems demonstrate the efficiency of the optimization algo rithm and its scalability with th e size of the problem . They also demonstra te state o f the art statistical perform ance, which improves over Lasso and StructOMP . 1 Intr oduction W e study th e problem of learn ing a sparse linear regression model. Th e goal is to estimate a parame- ter vector β ∗ ∈ R n from a vector of measurements y ∈ R m , obtained from t he model y = X β ∗ + ξ , where X is an m × n matrix , which may be fixed or ran domly chosen, and ξ ∈ R m is a vector resulting from th e presence o f noise. W e are interested in sparse estimation un der ad ditional con - ditions on th e sparsity patter n of β ∗ . In other words, not only we do expect that β ∗ is sparse b ut also that it e xhibits st ructur ed sparsity , namely certain configuration s of its nonzero comp onents are preferr ed to others. This problem arises in se veral applications, such as re gression, image denoising, backgr ound s ubtraction etc. – see [11, 9] for a discussion. In th is p aper, we build upon the structured spar sity fram ew ork recen tly prop osed by [ 12]. It is a regularization m ethod, f ormulated as a con vex, nonsmoo th op timization problem over a vector o f auxiliary parameters. This approa ch provides a constructive w ay to fa vour certain sp arsity p atterns of the regression vector β . Specifically , this formulation in volves a penalty fun ction given by the formu la Ω( β | Λ) = inf n 1 2 P n i =1 β 2 i λ i + λ i : λ ∈ Λ o . This function can be in terpreted as an ex- tension o f a well-known variational form for the ℓ 1 norm. The con vex constrain t set Λ p rovides a means to incorporate prior knowledge on the magnitu de of the componen ts of the re gression vector . As we explain in Sectio n 2, th e sparsity pa ttern of β is contained in th at of the auxiliary vector λ at the optimum. Hence, if the set Λ allows only for certain spar sity pattern s of λ , the same property will be “transferred ” to the regression vector β . In th is paper, we propose a tractable class of regular izers of the above f orm which extends th e ex- amples d escribed in [12]. Sp ecifically , we study in detail the cases in which the set Λ is de fined by 1 norm or conic constrain ts, combined with a linear map . As we sha ll see, these cases include formu- lations wh ich c an b e used for learning g raph sparsity a nd hierar chical spa rsity , in the termino logy of [9]. Th at is, t he sparsity pattern of the vector β ∗ may consist of a fe w contiguous regions in one o r more d imensions, o r may b e em bedded in a tree structure. These sparsity pro blems arise in several applications, ranging from f unctiona l magnetic reson ance imagin g [7, 22], to scene recognition in vision [8], to multi-task learning [1, 17] and to bioinfo rmatics [19 ] – to mention but a fe w . A main limitation of th e techn ique describ ed in [12] is that in many ca ses of interest th e penalty function can not be easily comp uted. This ma kes it difficult to solve the associated r egularization problem . For example [12] propo ses to use block coordin ate descent, an d this metho d is feasible only for a limited c hoice of th e set Λ . The main contribution of this paper is an efficient proxim al point meth od to solve regularized least squares with the p enalty fu nction Ω( β | Λ) in the g eneral case o f set Λ describe d above. Th e meth od co mbines a fast fixed point iterative scheme, which is inspired by recen t work by [13] with an accele rated first order meth od equiv a lent to FIST A [4]. W e present a n umerical stud y of the efficiency of the propo sed m ethod and a statistical co mparison of the propo sed penalty functio ns with the greedy method of [9] and the Lasso. Recently , there has been significant research interest on structur ed sparsity and the literature on this subject is growing fast, see fo r example [1, 9, 1 0, 11, 23] an d references therein for an in dicative list of papers. In th is work, we mainly focu s on con vex penalty m ethods and compare them to greedy m ethods [3, 9]. T he latter provide a n atural extension of techniques pr oposed in the sign al processing com munity and, as argu ed in [9], allow for a significant p erform ance improvement over more gener ic sparsity models such as the Lasso or the Group Lasso [23]. Th e former metho ds ha ve until recen tly focu sed mainly on extending the Gro up Lasso, by considering the possibility that the group s overlap acco rding to certain h ierarchical structure s [ 11, 24]. V ery recently , general choices of con vex pen alty functions hav e been propo sed [2, 12]. I n this paper we b uild upon [12], providing both new instances of the p enalty function and improved optimization algorithms. The paper is o rganized as follows. In Section 2, we set our notatio n, revie w the me thod of [ 12] and pre sent the new sets for inducing structu red sparsity . In Section 3, we present our tech nique for computing the proximity operator of the penalty func tion and the resulting accelerated proxim al method. In Section 4, we report numerical experiments with this method. 2 Framework and extensions In this section, we introd uce our notation, revie w the learning metho d which we extend in th is paper and present the new sets fo r inducing structured sparsity . W e let R + and R ++ be the n onnegative and positive real line, respectively . For e very β ∈ R n we define | β | ∈ R n + to be th e vector | β | = ( | β i | ) n i =1 . For ev ery p ≥ 1 , we define the ℓ p norm of β as k β k p = ( P n i =1 | β i | p ) 1 p . If C ⊆ R n , we denote by δ C : R n → R the indicator function of the set C , that is, δ C ( x ) = 0 if x ∈ C and δ C ( x ) = + ∞ other wise. W e now review the structu red spar sity app roach of [ 12]. Gi ven an m × n input data matrix X and an output vector y ∈ R m , obtained from the linear regression model y = X β ∗ + ξ d iscussed earlier , they consider the optimization problem inf 1 2 k X β − y k 2 2 + ρ Γ( β , λ ) : β ∈ R n , λ ∈ Λ (2.1) where ρ is a po siti ve parameter, Λ is a prescribed con vex subset of the positi ve orthant R n ++ and the function Γ : R n × R n ++ → R is given by the for mula Γ( β , λ ) = 1 2 n X i =1 β 2 i λ i + λ i . Note that the infimum over λ in general is not attain ed, howe ver the infimum over β is always attained. Since the auxiliary vector λ appears only in the second term and our goal is to esti mate β ∗ , we may also directly consider the regularization problem min 1 2 k X β − y k 2 2 + ρ Ω( β | Λ) : β ∈ R n , (2.2) 2 where the penalty functio n takes the form Ω( β | Λ ) = inf { Γ( β , λ ) : λ ∈ Λ } . This problem is still conv ex beca use the function Γ is jointly con vex [ 5]. Also , note that the fun ction Ω is independent of the signs of the compo nents of β . In o rder to gain some insight about the above m ethodo logy , we note that, for every λ ∈ R n ++ , the quadra tic function Γ( · , λ ) provid es an upp er bou nd to the ℓ 1 norm, namely it h olds that Ω( β | Λ ) ≥ k β k 1 and the inequality is tight if and only if | β | ∈ Λ . Th is fact is an immediate consequence of the arithmetic-g eometric inequ ality . In particular, we see tha t if we choose Λ = R n ++ , the meth od (2.2) reduces to the Lasso 1 . The above o bservation suggests a heuristic interpretatio n of the method (2.2): among all vectors β which have a fixed value of the ℓ 1 norm, the penalty function Ω will encou rage those fo r which | β | ∈ Λ . Moreover, when | β | ∈ Λ the f unction Ω re duces to th e ℓ 1 norm an d, so, the solution of problem (2.2) is expected to be sparse. The penalty functio n th erefor e will encourag e certain desired sparsity patterns. The last po int can be better understood by look ing at problem (2.1). For e very solution ( ˆ β , ˆ λ ) , the sparsity pattern o f ˆ β is contained in th e sparsity pattern of ˆ λ , th at is, the indices associa ted with nonzer o com ponen ts of ˆ β a re a sub set of th ose of ˆ λ . Indee d, if ˆ λ i = 0 it must hold that ˆ β i = 0 as well, since th e ob jectiv e would di verge otherwise (be cause of the ratio β 2 i /λ i ). Th erefore , if the set Λ fa vours certain sparse solutions of ˆ λ , the sam e sparsity pattern will be reflected on ˆ β . Moreover , the regular ization term P i λ i fa vours sparse vectors λ . For example, a con straint o f the form λ 1 ≥ · · · ≥ λ n , fav ours consecutive zeros at th e end of λ and n onzero s e verywh ere else. This will lead to zer os at th e end of β as well. Th us, in many cases like this, it is e asy to incorpor ate a conv ex constraint on λ , whereas it may not be possible to do the same with β . In this paper we consider sets Λ of the form Λ = { λ ∈ R n ++ : Aλ ∈ S } where S is a conve x set and A is a k × n matrix . T wo main choices o f interest are when S is a conve x cone or the unit ball of a norm. W e shall refer to the corresp onding set Λ as conic constraint or norm constraint set, respectively . W e next discuss two specific examp les, which h ighligh t the flexibility of our approach and help us understand the sparsity patterns fa voured by each cho ice. W ithin the con ic co nstraint sets, we may choose S = R k ++ , so that Λ = { λ ∈ R n ++ : Aλ ≥ 0 } , which can be used to en courag e hierar chical sparsity . I n [1 2] they con sidered the set Λ = { λ ∈ R n ++ : λ 1 ≥ · · · ≥ λ n } and derived an explicit formu la of the co rrespon ding regu larizer Ω( β | Λ) . Note that f or a g eneric matrix A the pen alty functio n ca nnot be co mputed explicitly . In Sectio n 3, we show how to ov ercome this dif ficulty . W ithin the norm constraint sets, we may choose S to be the ℓ 1 -unit ball and A the ed ge ma p of a graph G with ed ge set E , so tha t Λ = n λ ∈ R n ++ : P ( i,j ) ∈ E | λ i − λ j | ≤ 1 o . T his set can be used to enco urage spa rsity patterns consisting of f ew conn ected regions/sub graph s of the gr aph G . For example if G is a 1D-g rid we have that Λ = { λ ∈ R n ++ : P n − 1 i =1 | λ i +1 − λ i | ≤ 1 } , so the correspo nding penalty wi ll fa vour v ectors β whose absolu te values are constan t. For a generic con vex set Λ , since the penalty function Ω is not easily compu table, one needs t o deal directly with prob lem (2. 1). T o this end, we recall here the definition of the proximity operator [14]. Definition 2 .1. Let ϕ be a real-valued conve x fu nction on R d . The pr oximity operator of ϕ is defined , for every t ∈ R d by prox ϕ ( t ) := arg min 1 2 k z − t k 2 2 + ϕ ( z ) : z ∈ R d . The proxim ity ope rator is well-defined, because the above minimum exists and is unique. 3 Optimization Method In this section, we discuss how to solve p roblem (2.1 ) usin g an ac celerated first-or der method that scales linearly with respect to the problem size, as we later show in the experiments. Th is method relies on th e com putation of the proximity op erator of the function Γ , restricted to R n × Λ . Since 1 More generally , method (2 .2) includes the Group Lasso method, see [12]. 3 the exact c omputatio n o f the proxim ity op erator is possible only in simp le special cases of sets Λ , we pr esent here an efficient fixed-poin t algorithm for com puting the p roximity op erator that can be applied to a wide variety of constraints. Finally , we discuss an accelerated proximal method that uses our algorithm. 3.1 Computation of the Proximity Operator According to Definition 2.1, the pro ximal operato r of Γ at ( α, µ ) ∈ R n × R n is th e solu tion o f th e problem min 1 2 k ( β , λ ) − ( α, µ ) k 2 2 + ρ Γ( β , λ ) : β ∈ R n , λ ∈ Λ . (3.1) For fixed λ , a direct com putation yields that the objecti ve fun ction in (3.1) attains its minimum at β i ( λ ) = α i λ i λ i + ρ . Using this equation we obtain the simplified problem min ( 1 2 k λ − µ k 2 + ρ 2 n X i =1 α 2 i λ i + ρ + λ i : λ ∈ Λ ) . (3.2) This pro blem can still be interp reted as a pro ximity map computa tion. W e d iscuss h ow to solve it under our general assumptio n Λ = { λ ∈ R n ++ : Aλ ∈ S } . Mor eover , we assume that the projection on the set S can be easily co mputed . T o this end , we de fine the ( n + k ) × n matrix B ⊤ = [ I , A ⊤ ] and the function ϕ ( s, t ) = ϕ 1 ( s ) + ϕ 2 ( t ) , ( s, t ) ∈ R n × R k , where ϕ 1 ( s ) = ρ 2 n X i =1 α 2 i s i + ρ + s i + δ R ++ ( s i ) , and ϕ 2 ( t ) = δ S ( t ) . Note tha t the solution of pr oblem (3.2) is the same as the proximity map o f th e linearly composite function ϕ ◦ B at µ , wh ich solves the pr oblem min 1 2 k λ − µ k 2 + ϕ ( B λ ) : λ ∈ R n . At first sight this p roblem seems d ifficult to solve. Howe ver, it turns out th at if the proximity map of the functio n ϕ h as a simple f orm, the following theorem adapted f rom [1 3, Theo rem 3.1] can be used to accomplish this task. For ease of notation we set d = n + k . Theorem 3.1. Let ϕ be a co n vex func tion on R d , B a d × n matrix, µ ∈ R n , c > 0 , and define the mapping H : R d → R d at v ∈ R d as H ( v ) = ( I − prox ϕ c )(( I − cB B ⊤ ) v + B µ ) . Then, for any fixed point ˆ v of H , it holds that prox ϕ ◦ B ( µ ) = µ − cB ⊤ ˆ v. The Picar d iterates { v s : s ∈ N } ⊆ R d , starting at v 0 ∈ R d , are defined by the recu rsiv e equation v s = H ( v s − 1 ) . Since the ope rator I − prox ϕ is n onexpansive 2 (see e.g . [6]), the map H is no nex- pansive if c ∈ h 0 , 2 || B || 2 i . Despite this, the Picard iterates are n ot g uaranteed to conv erge to a fixed point of H . Ho wever , a simple mod ification with an av eraging schem e can be used to co mpute th e fixed point. Theorem 3.2. [18] Let H : R d → R d be a non expansive ma pping which h as at least o ne fixed point and let H κ := κI + (1 − κ ) H . Then, for every κ ∈ (0 , 1) , the Picard iter ates of H κ conver ge to a fixed point of H . The required proximity opera tor of ϕ is direc tly gi ven , for e very ( s, t ) ∈ R n × R k , by prox ϕ ( s, t ) = prox ϕ 1 ( s ) , prox ϕ 2 ( t ) . 2 A mapping T : R d → R d is called nonex pansi ve if k T ( v ) − T ( v ′ ) k 2 ≤ k v − v ′ k 2 , for e very v, v ′ ∈ R d . 4 Both prox ϕ 1 and pr ox ϕ 2 can b e easily c omputed . The latter req uires comp uting the pr ojection on the set S . Th e for mer r equires, for each compon ent of the vector s ∈ R n , the solution of a cubic equation as stated in the next lemma. Lemma 3.1. F or every µ, α ∈ R and r, ρ > 0 , the function h : R + → R d efined at s as h ( s ) := ( s − µ ) 2 + r α 2 s + ρ + s has a u nique minimum o n its domain, which is attained a t ( x 0 − ρ ) + , wher e x 0 is the lar gest r eal r o ot of the polyno mial 2 x 3 + ( r − 2( µ + ρ )) x 2 − r α 2 . Proof. Setting the deriv ativ e of h equal to zero and making the change of variable x = s + ρ yield s the poly nomial stated in the lemma. Let x 0 be the largest root of this polyn omial. Since the function h is strictly con vex on its dom ain and g rows at infinity , its minimum can be attaine d only a t o ne point, which is x 0 − ρ , if x 0 > ρ , and zero otherwise. 3.2 Accelerated Proximal Method Theorem 3 .1 motiv ates a pr oximal num erical appro ach to solving p roblem (2.1) and, in turn, p roblem (2.2). Let E ( β ) = 1 2 k X β − y k 2 2 and assume an u pper boun d L of k X ⊤ X k is kno wn 3 . Proximal first- order methods – see [6, 4, 16, 21] and references therein – can be used for nonsmooth optimizatio n, where th e objective con sists o f a stro ngly smooth ter m, plus a nonsmoo th part, in our case E and Γ + δ Λ , respectively . The idea is to r eplace E with its linear approximation around a point w t specific to iteration t . This leads to the comp utation of a pr oximity oper ator, and specifically in o ur case to u t := ( β t , λ t ) ← argmin L 2 k ( β , λ ) − ( w t − 1 L ∇ E ( w t )) k 2 2 + ρ Γ( β , λ ) : β ∈ R n , λ ∈ Λ . Subsequen tly , the p oint w t is up dated, based on the curren t and p revious estimate s of the solu tion u t , u t − 1 , . . . and the proc ess repe ats. The simplest upd ate ru le is w t = u t . By contr ast, accelerated p r oxima l metho ds pr oposed by [16] use a carefully chosen w update with two levels of memor y , u t , u t − 1 . If th e pr oximity m ap can be exactly compu ted, su ch schem es exhibit a fast qua dratic decay in terms of the iteration cou nt, that is, th e distance of the objective fr om the min imal value is O 1 T 2 after T iterations. H owe ver, it is not kn own whether accelerated meth ods which compu te the p roximity op erator n umerically can achieve this rate. T he main advantages of accelerated metho ds are their low cost per iter ation and their scalability to large problem sizes. M oreover , in app lications where a th resholding oper ation is in volved – as in Lemma 3.1 – the zeros in the solution are exact. Algorithm 1 NEsterov PIcard-Opial algorithm (NEPIO) u 1 , w 1 ← arbitr ary feasible v alues for t=1,2,. . . do Compute a fixed point ˆ v ( t ) of H t by Picard-Opial u t +1 ← w t − 1 L ∇ E ( w t ) − c L B ⊤ ˆ v ( t ) w t +1 ← π t +1 u t +1 − ( π t +1 − 1) u t end for For our purp oses, we use a version of acceler ated meth ods influ enced by [21] (described in Algorithm 1 and called NEPIO ). A ccording to Nesterov [1 6], th e o ptimal up date is w t +1 ← u t +1 + θ t +1 1 θ t − 1 ( u t +1 − u t ) where the sequen ce θ t is defined by θ 1 = 1 and the recu rsion 1 − θ t +1 θ 2 t +1 = 1 θ 2 t . W e have adapted [21, Algo rithm 2] (eq uiv alent to FIST A [4]) b y comp uting the pr oximity operato r of ϕ L ◦ B using the Pi card-Op ial proce ss describ ed in Section 3.1. W e reph rased the algorithm using the sequence π t := 1 − θ t + √ 1 − θ t = 1 − θ t + θ t θ t − 1 for numerical stability . At each iteration, the map H t is defined by H t ( v ) := I − prox φ c I − c L B B ⊤ v − 1 L B ∇ E ( w t ) − Lw t ! . 3 For v ariants of such algorithms which adapti vely learn L , see the above references. 5 W e also apply an Opial averaging so that the update at stage s of the prox imity comp utation is v s +1 = κv s + (1 − κ ) H t ( v s ) . By Theor em 3.1, t he fixed poin t proc ess com bined with the assignment of u are equivalent to u t +1 ← prox ϕ L ◦ B w t − 1 L ∇ E ( w t ) . The reason fo r resorting to Picard-Op ial is th at exact computa tion of the proximity operator (3.2) is po ssible o nly in simple special cases for the set Λ . By contrast, our approa ch ca n be app lied to a wide variety of con straints. Mo reover , we are n ot aware of anothe r p roximal method fo r solving problem s (2. 1) o r (2 .2) and altern ativ es like interio r point me thods do not scale well with p roblem size. I n th e next sectio n, we will demo nstrate empirically th e scalab ility of Algor ithm 1, as well as the efficiency of both the proximity map computation and the overall metho d. 4 Numerical Simulations In this section , we present exp eriments with method (2.1). The go al of the experiments is to both study the com putational an d the statistical estimation properties of this method. One important aim of the e xperiments is to dem onstrate that the method is statistically competiti ve or super ior to state-o f-the-art metho ds while being compu tationally efficient. The me thods employed ar e the Lasso, StructOMP [9] and method (2.1) with the following choices for the constraint set Λ : Grid-C , Λ α = { λ : k Aλ k 1 ≤ α } , where A is the edge map of a 1D o r 2D grid and α > 0 , a nd T r ee-C , Λ = { λ : Aλ ≥ 0 } , where A is the edge map of a tree graph . W e solved the optimizatio n proble m (2.1) either with th e to olbox CVX 4 or with the prox imal metho d presented in Section 3. Whe n using the prox imal m ethod, we chose the p arameter from Opial’ s Theorem κ = 0 . 2 and we stopped the iteration s when the relative decrease in the objective value is less th an 10 − 8 . For the c omputatio n of the proxim ity operato r , we stopped the iterations of th e Picard-Opial me thod when the relative difference between two c onsecutive iterates is smaller than 10 − 2 . W e studied the ef fect of varying this to lerance in the next experiments. W e u sed the squ are loss and compu ted the Lipsch itz constant L u sing singular value decomposition. 0 5,000 10,000 15,000 20,000 1600 0 50 100 150 200 Number of variables Mean CPU Time [min] Grid−C CVX NEPIO (Picard−Opial tol = 10 −2 ) 0 5,000 10,000 15,000 20,000 1600 0 50 100 150 Number of variables Mean CPU Time [min] Tree−C CVX NEPIO (Picard−Opial tol = 10 −2 ) Alternating Algorithm 10^−2 10^−3 10^−4 10^−5 10^−6 10^−7 10^−8 0 0.02 0.04 0.06 0.08 0.1 Difference with CVX value Relative difference % Picard−Opial tolerance Grid−C Tree−C Figure 1: (Left and C entre) Computatio n time vs pr oblem size for Gr id-C and T ree- C. (Right) Difference with t he solution obtain ed via CVX vs Picard -Opial tolerance. 4.1 Efficiency experiments First, we in vestigated the comp utational pro perties of the prox imal metho d. Ou r aim in these exper- iments w as to sho w that our algorithm has a time complexity that scales linearly with t he number of variables, while the sparsity and relative number of training examples is kept co nstant. W e c onsid- ered both the Grid and the T ree constraints and compared our algorithm t o the toolbox CVX, which is an interior-point meth od so lver . As is c ommon ly known, interior-point m ethods are very fast, but do not scale well with the pro blem size. In the case of the Tree constrain t, we also compared with a modified version of the alternating algorithm of [12]. For each p roblem size, we repeated the experiments 10 times and we repor t the a verage computation time in Figure 1- (Left and Centr e) for Grid-C an d T r ee-C, respectively . T his result ind icates that our meth od is suitable for large scale experiments. W e also studied the impor tance of the Picard-Opial tolerance fo r c on verging to a good solution. In Figure 1- Right , we repo rt the av erage relativ e d istance to the solution obta ined via CVX for different 4 http://cvxr.c om/cvx/ 6 22 25 30 35 40 45 50 75 100 0 0.2 0.4 0.6 0.8 1 1.2 1.4 Sample size Model error Lasso StructOMP Grid−C 22 25 30 35 40 45 50 75 100 0 0.2 0.4 0.6 0.8 1 1.2 1.4 Sample size Model error Lasso StructOMP Grid−C 22 25 30 35 40 45 50 75 100 0 0.5 1 1.5 Sample size Model error Lasso StructOMP Grid−C 22 25 30 35 40 45 50 75 100 0 0.5 1 1.5 Sample size Model error Lasso StructOMP Grid−C Figure 2: 1 D co ntiguou s regions: comparison between different methods for one (left), two (cen tre- left), three (centre- right) and four (right) regions. 50 100 150 200 −2 −1 0 1 2 50 100 150 200 −2 −1 0 1 2 50 100 150 200 −2 −1 0 1 2 50 100 150 200 −2 −1 0 1 2 Figure 3 : T wo 1 D co ntiguou s r egions: regression vector estimated b y different m odels: β ∗ (left), Lasso (centre-left) , StructOMP (centr e-right), Grid-C (right). values of the Picar d-Opial toleran ce. W e consid ered a p roblem with 1 00 v ariables and repe ated the experiment 10 times with d ifferent samp ling of training examp les, con sidering both the Grid and the Tree constra int. It is clear that d ecreasing th e tolerance did not brin g any advantage in terms o f conv erging to a b etter solution, while it r emarkab ly increased the co mputation al overhead, passing from an a verage of 5 s for a toleran ce of 10 − 2 to 40 s for 10 − 8 in the case of the Grid constraint. Finally , we considere d the 2D Grid- C case and observed that the num ber of Picard-Opial iteration s needed to reach a toleran ce of 10 − 2 , scales well with the nu mber of variables n . For example when n varies between 200 an d 6400 , the average num ber of iterations v a ried between 20 and 40 . 4.2 Statistical experiments One dimensional contig uous regions. I n this experiment, we chose a mod el vector β ∗ ∈ R 200 with 20 n onzero elements, whose values are random ± 1 . W e considered sparsity p atterns form ing one, two, three or fou r non-overlappin g contiguo us regions, which have lengths of 20 , 10 , 7 or 5 , respectively . W e g enerated a noiseless outp ut from a matrix X whose elemen ts have a standar d Gaussian distrib ution. The esti mates ˆ β for se veral models are then com pared with the o riginal. Figure 2 shows the mod el error k ˆ β − β ∗ k 2 k β ∗ k 2 as the sample size ch anges from 22 (barely ab ove the sparsity) up to 100 (h alf the dimension ality). This is the average ov er 50 run s, each with a different β ∗ and X . W e observe that Grid-C o utperfo rms bo th La sso and StructOMP , whose per forman ce deteriorates as the number of regions is increased . For one particular run with a sample size which is twice the model sparsity , Figure 3 shows the original vector and the estimates for different metho ds. T wo dimensional contig uous regions. W e repeated the experiment in the case tha t the sparsity pattern of β ∗ ∈ R 20 × 20 consists of 2 D rectangular regions. W e co nsidered either a single 5 × 5 region, two re gions ( 4 × 4 an d 3 × 3 ) , three 3 × 3 regions and four 3 × 2 r egions. Figure 4 shows the model err or versu s th e sample size in th is case. Figure 5 shows th e original imag e and the images estimated by different methods for a sample s ize which is twice the m odel sparsity . No te that Grid-C is superior to both the Lasso and StructOM P an d that StructOMP is outperfo rmed by L asso w hen the n umber of regions is mo re than two. This behavior is consistently c onfirmed by experim ents in higher dimension s, not shown here for bre vity . Background subtraction. W e rep licated the experiment from [9, Sec. 7.3 ] with our m ethod. Briefly , the un derlying mod el β ∗ correspo nds to the pixels of the foregro und of a CCTV image. W e measured the outpu t as a r andom projection plus Gaussian no ise. Figure 6- Left shows that, while the Grid-C outperf orms the Lasso, it is not as good as StructOMP . W e speculate that this result is due to the non unifor mity of the values of the image, which makes it harder for Grid- C to estimate the model. 7 25 40 55 70 85 100 0 0.2 0.4 0.6 0.8 1 1.2 1.4 Sample size Model error Lasso StructOMP Grid−C 25 40 55 70 85 100 0 0.2 0.4 0.6 0.8 1 1.2 1.4 Sample size Model error Lasso StructOMP Grid−C 25 40 55 70 85 100 0 0.5 1 1.5 Sample size Model error Lasso StructOMP Grid−C 25 40 55 70 85 100 0 0.5 1 1.5 Sample size Model error Lasso StructOMP Grid−C Figure 4: 2 D co ntiguou s regions: comparison between different methods for one (left), two (cen tre- left), three (centre- right) and four (right) regions. Figure 5: 2 D -contig uous regions: model vector an d v ectors estimated by the Lasso, StructOMP and Grid-C (left to right), for one region (first group) and tw o regions (second group). Image Compressi ve Sensing. In this expe riment, we compa red the perfo rmance o f T r ee-C on an instance o f 2D image compressi ve sensing, following the e xperimen tal protoc ol of [9]. Natural images can be well represented with a wa velet basis and their wav elet coefficients, b esides bein g sparse, are also struc tured as a hie rarchical tree. W e computed the Haar-wa velet coe fficients of a widely u sed came raman image. W e m easured the output as a rand om pro jection plus Gaussian noise. StructOMP a nd Tree-C, bo th exploiting the tree stru cture, were used to recover the wa velet coefficients from the measuremen ts and compared to the Lasso. The in verse wav elet transfor m w as used to reconstruct the images with the estimated coefficients. The recovery perfor mances o f the methods are reported in Figure 6- Right , which highligh ts the good performance of Tree-C. 88 132 176 220 264 308 352 0 0.5 1 1.5 Sample size Model error Lasso StructOMP Fused−C 394 473 551 630 709 788 866 0 0.05 0.1 0.15 0.2 0.25 Sample size Model error Lasso StructOMP Tree−C Figure 6: Model error for the backgro und subtrac tion (left) and cameraman (right) experiments. 5 Conclusion W e proposed new families o f pe nalties and pr esented a new algor ithm and results on the class of structured sparsity pen alty function s proposed by [12]. These penalties ca n be used, am ong else, to learn regression vectors whose spar sity patter n is fo rmed b y few contig uous regions. W e presented a proximal meth od for solving this class of p enalty fu nctions and derived an efficient fixed-po int method for com puting the prox imity ope rator of our p enalty . W e reported enco uragin g e xperime n- tal results, which highlig ht the advantages o f the proposed p enalty functio n over a state-of- the-art greedy meth od [9]. At the same time, our n umerical simulation s indicate that the proxim al method is com putationally efficient, scaling linearly with the problem size. An important problem which we wish to ad dress in the future is to study the convergence rate o f th e meth od and deter mine whe ther the optimal rate O ( 1 T 2 ) can be attained. Finally , it would b e importa nt to d eriv e sparse o racle in- equalities for the estimators studied here. 8 Refer ences [1] Argyriou, A., Ev geniou , T ., and Pontil, M. Con vex multi-task f eature learning. Machine Learning , 73(3) :243–2 72, 2 008. [2] Bach, F . Structured sparsity-induc ing norm s throu gh submodular functions. In Adva nces in Neural Information Pr oc essing Systems 23 , pp. 118–1 26. 201 0. [3] Baraniuk, R.G., Cevher , V ., Duarte, M.F ., and Hegde, C. M odel-based com pressiv e sensing. Information Theory , IEEE T ransactions on , 56(4):1 982–2 001, 20 10. [4] Beck, A. and T ebo ulle, M. A f ast iterativ e shrinkage- thresholdin g algorithm for linear inverse problem s. SIA M J ournal of Imaging Sciences , 2(1):183 –202 , 200 9. [5] Boyd, S. and V and enberghe, L. Conve x Optimizatio n . Cambridge University Press, 2004. [6] Combettes, P .L. and W ajs, V .R. Signal recovery by proximal forward-b ackward splitting. Mul- tiscale Modeling and Simulation , 4(4 ):1168 –120 0, 2006 . [7] A. Gramfo rt and M. K ow alski. Improving M/EEG source lo calization with an inter-condition sparse prior, preprin t, 2009 . [8] H. Harzallah, F . Jurie, an d C. Schmid . Combining ef ficient object localizatio n and imag e classification. 2009 . In IEEE International Symposium on Biomedical Imaging , 2009. [9] Huang, J., Zhan g, T ., and M etaxas, D. L earning with structu red sp arsity. In Pr oc eedings of the 26th Annual Internation al Conference on Machine Learning , pp. 417– 424. A CM, 2009. [10] Jacob, L., Obozinski, G., and V ert, J.-P . Group lasso with overlap and graph lasso. In Interna - tional Confer en ce on Machine Learning (ICML 26) , 2009. [11] Jenatton, R., Audiber t, J.-Y ., and Bach, F . Structured variable selection with sparsity-indu cing norms. arXiv:0904.3 523 v2 , 2009. [12] Micchelli, C.A., Mo rales, J.M., and Pontil, M . A family of p enalty functio ns for structured sparsity . In Advance s i n Neural Information Pr ocessing Systems 23 , pp. 161 2–162 3. 2010. [13] Micchelli, C.A., Shen, L., an d Xu, Y . Proximity algorithm s for image mo dels: denoising. In verse Pr o blems , 27(4), 2011. [14] Moreau , J.J. Fonctions conv exes duales et points pr oximau s dans un espac e Hilbertien. Acad. Sci. P aris S ´ er . A Math. , 25 5:289 7–289 9, 1962 . [15] Mosci, S., Rosasco, L., Santoro, M., V erri, A., and V illa, S. Solving Structured Sparsity Regularization with Proximal Methods. Proc. of ECML, pages 418–433 , 20 10. [16] Nesterov , Y . Gradient methods for minimizing composite objective function . CORE, 2007. [17] G. Obozinski, B. T aska r , and M.I. Jordan. Join t cov ariate selection an d joint subspace selection for multiple classification problems. Statistics and Computin g , 20(2):1–22 , 2010. [18] Opial, Z . W eak con vergence of the seq uence of su ccessi ve appro ximation s for non expansive operator s. Bulletin America n Mathematical Society , 73:591– 597, 1967 . [19] F . Rapaport, E. Barillot, and J.P . V e rt. Classification of arrayCGH data usin g fu sed SVM. Bioinformatics , 24(13 ):i375– i382, 2008. [20] Rockafellar, R. T . Conve x Analysis . Princeton University Press, 1970 . [21] Tseng, P . On accelera ted pro ximal grad ient metho ds for conve x-concave optimization. 2008 . Preprint. [22] Z. Xiang , Y . Xi, U. Hasson , a nd P . Ramad ge. Boosting with spatial regularization. In Y . Bengio, D. Schuurm ans, J. Lafferty , C. K. I . W illiams, and A. Cu lotta, editors, Advan ces in Neural Information Pr ocessing Systems 22 , pages 2107–21 15. 2009. [23] Y uan, M. and Lin , Y . M odel selection and e stimation in regression with grouped variables. Journal of the Royal Sta tistical Society , Series B , 68(1):49 –67, 2006 . [24] Zhao, P ., Rocha, G., an d Y u, B. Gr ouped an d hierar chical model selection throu gh compo site absolute penalties. Anna ls of Statistics , 37(6A):3468 –349 7, 2009 . 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment