Quantum learning: optimal classification of qubit states
Pattern recognition is a central topic in Learning Theory with numerous applications such as voice and text recognition, image analysis, computer diagnosis. The statistical set-up in classification is the following: we are given an i.i.d. training se…
Authors: *논문 본문에 저자 정보가 명시되어 있지 않음.* (가능하면 원문에서 확인 필요)
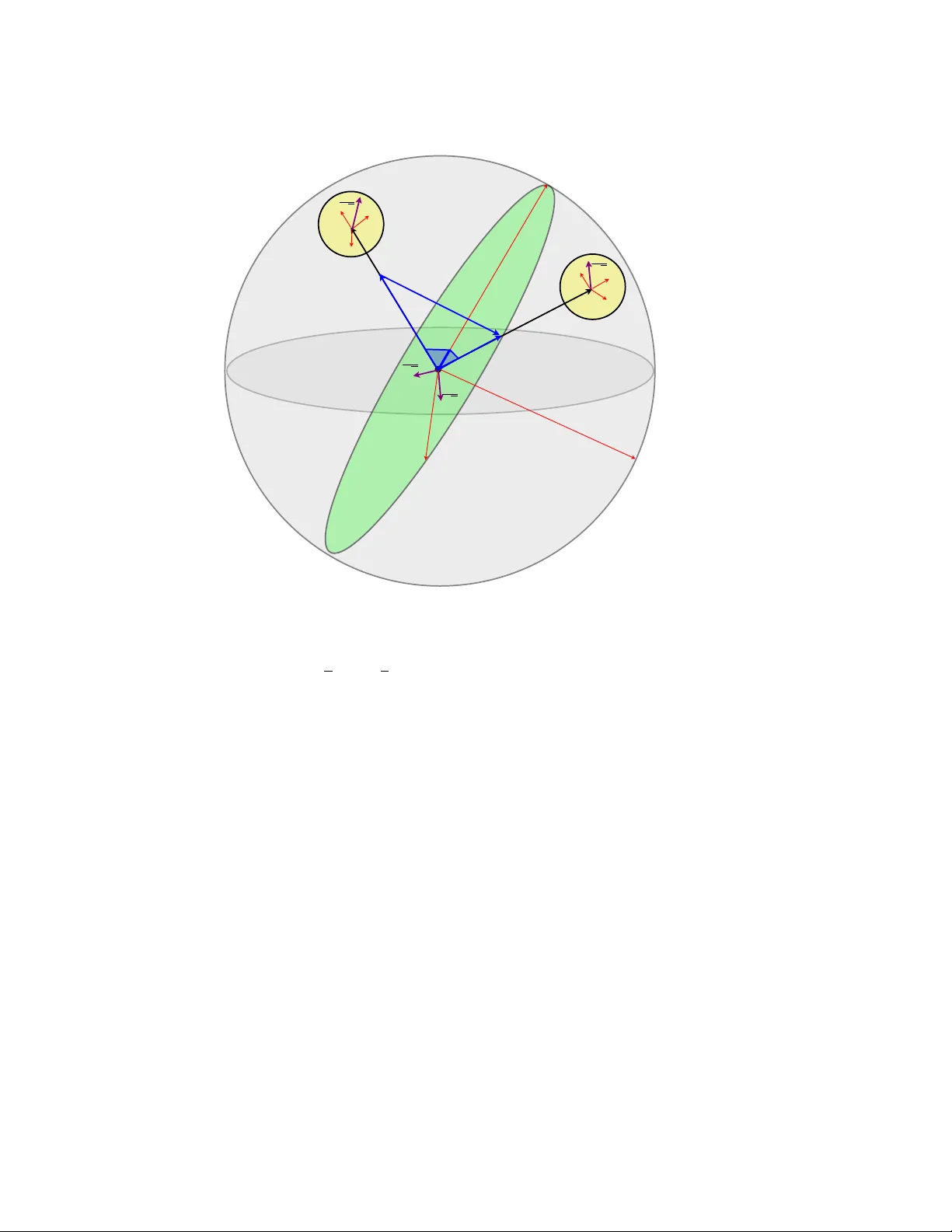
Quantum learning: optimal c lassification of qubit states M ˘ ad ˘ alin Gut ¸ ˘ a 1 and W ojciech K otłowski 2 1 School of Mathematical Sciences, Univ ersity of Nottingham, Univ ersity Park, NG7 2RD Nottingham, United Kingdom 2 CWI, Science Park 123, 1098 XG Amsterdam E-mail: madalin.guta@nottingham.ac.uk Abstract. Pattern recognition is a central topic in Learning Theory with numerous applications such as voice and te xt recognition, image analysis, computer diagnosis. The statistical set-up in classification is the following: we are giv en an i.i.d. training set ( X 1 , Y 1 ) , . . . ( X n , Y n ) where X i represents a feature and Y i ∈ { 0 , 1 } is a label attached to that feature. The underlying joint distribution of ( X, Y ) is unkno wn, but we can learn about it from the training set and we aim at devising low error classifiers f : X → Y used to predict the label of new incoming features. Here we solve a quantum analogue of this problem, namely the classification of two arbitrary unknown qubit states. Gi ven a number of ‘training’ copies from each of the states, we would like to ‘learn’ about them by performing a measurement on the training set. The outcome is then used to design mesurements for the classification of future systems with unknown labels. W e find the asymptotically optimal classification strategy and show that typically , it performs strictly better than a plug-in strategy based on state estimation. The figure of merit is the e xcess risk which is the dif ference between the probability of error and the probability of error of the optimal measurement when the states are known, that is the Helstrom measurement. W e show that the excess risk has rate n − 1 and compute the exact constant of the rate. Contents 1 Introduction 2 2 Classical and quantum learning 4 2.1 Classical Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 2.2 Quantum Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 2.3 Local minimax formulation of optimality . . . . . . . . . . . . . . . . . . . 8 3 Local asymptotic normality 10 3.1 Local asymptotic normality in classical statistics . . . . . . . . . . . . . . . . 10 3.2 Local asymptotic normality in quantum statistics . . . . . . . . . . . . . . . 12 4 Local formulation of the classification pr oblem 14 4.1 The loss function . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 4.2 The training set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 5 Optimal classifier 18 5.1 Plug-in classifier based on optimal state estimation . . . . . . . . . . . . . . 20 5.2 The case of unknown priors . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 6 Conclusions 22 1. Intr oduction Statistical learning theory [1, 2, 3, 4] is a broad research field stretching over statistics and computer science, whose general goal is to de vise algorithms which have the ability to learn from data. One of the central learning problems is ho w to recognise patterns [5], with practical applications in speech and text recognition, image analysis, computer-aided diagnosis, data mining. The paradigm of Quantum Information theory is that quantum systems carry a new type of information with potentially rev olutionary applications such as faster computation and secure communication [6]. Motiv ated by these theoretical challenges, Quantum Engineering is de veloping ne w tools to control and accurately measure indi vidual quantum systems [7]. In the process of engineering exotic quantum states, statistical v alidation has become a standard experimental procedure [8, 9] and Quantum Statistical Inference has passed from its purely theoretical status in the 70’ s [10, 11] to a more practically oriented theory at the interface between the classical and quantum worlds [12, 13, 14, 15]. In this paper we put forward a ne w type of quantum statistical problem inspired by learning theory , namely quantum state classification . Similar ideas have already appeared in the Quantum learning: optimal classification of qubit states 3 physics [16, 17, 18, 19] and learning [20, 21, 22] literature b ut here we emphasise the close connection with learning and we aim at going beyond the special models based on group symmetry and pure states. Ho wev er , we limit ourselves to a two dimensional state which could be regarded as a toy model from the viewpoint of learning theory , but hope that more interesting applications will follow . Before explaining what quantum classification is, let us briefly mention the classical set-up we aim at generalising. In supervised learning the goal is to learn to predict an output y ∈ Y , giv en the input (object) x ∈ X , where input and output are assumed to be correlated and hav e an unknown joint distribution P ov er X × Y . T o do this, we are first provided with a set of n previously observed inputs with known output variables (called tr aining examples ), i.e. independent random pairs ( X i , Y i ) , i = 1 , . . . , n drawn from P . Using the training set, we construct a function h n : X → Y to predict the output for future, yet unseen objects. When Y = { 0 , 1 } , i.e. the output is a binary v ariable, this is called binary classification and is the typical set-up in pattern recognition. The input space is usually considered to be a subset of p -dimensional space R p , so that the object x can be described by p measurement values often called featur es . This description is very general as it allows e.g. to handle categorical (non-numerical) values (encoded as integer numbers), images (e.g. measured brightness of each pixel corresponds to a separate feature), time series (features corresponds to the v alues of the signal at giv en times), etc. In this paper , we consider the classification problem in which the objects to be classified are quantum states. Simply , we hav e a quantum system prepared in either of two unknown quantum states and we want to know which one it is. As in the classical case, this only makes sense if we are also provided with training examples from both states, with their respectiv e labels, from which we can learn about the two alternati ves. How could such a scenario occur? Suppose we send one bit of information through a noisy quantum channel which is not known. T o decode the information (the input in this case) we need to be able to classify the output states corresponding to the two inputs. Alternati vely , the binary variable may be related to a coupling of the channel which we want to detect. Needless to say , quantum systems are intrinsically statistical and can be ‘learned’ only by repeated preparation, so that the problem is really the quantum extension of the classical classification problem. On the other hand this is related to the problem of state discrimination which in the case of two hypotheses, has an explicit solution known as the Helstrom measurement [11]. The point is that when the states are unkno wn, the Helstrom measurements is itself unkno wn and has to be learned from the training set. An intuiti ve solution w ould be a plug-in procedure: first estimate the two states, and then apply the Helstrom measurement corresponding to the estimates on any new to-be-classified state. This indeed gi ves a reasonable classification strategy , but as we will see, this is not the best one. The optimal strategy in the asymptotic frame work is to directly estimate the Helstrom measurement without intermediate states estimation. The optimality is defined by the natural figure of merit called excess risk , which is the difference between the expected error probability and the error probability of the Helstrom measurement. W e sho w that the excess risk con verges to zero with the size of the training set as n − 1 and the ratio between the optimal and state estimation plug-in risk is a constant factor . Our analysis is v alid for arbitrary mixed states and is performed in a pointwise , local minimax (rather than Bayesian) setting which captures the behaviour of the risk around any pair of states. The ke y theoretical tool is the recently de veloped theory of local asymptotic normality (LAN) for quantum states [23, 24, 25, 26] which is an extension of the classical concept in mathematical statistics introduced by Le Cam [27]. Roughly , LAN says that the Quantum learning: optimal classification of qubit states 4 collectiv e state ρ ⊗ n θ of n i.i.d. quantum systems can be approximated by a simple Gaussian state of some classical v ariables and quantum oscillators. This was used to deriv e optimal state estimation strategies for arbitrary mixed states of arbitrary finite dimension, and also in finding quantum teleportation benchmarks for multiple qubit states [28]. In this paper , LAN is used to identify the (asymptotically) optimal measurement on the training set as linear measur ement on two harmonic oscillators. Similarly to the case of state estimation such collecti ve measurements perform strictly better than the local ones [29, 30]. Moreover , optimal learning collective measurement is dif ferent from the optimal measurement for state estimation, showing once again that generically , dif ferent quantum decision problems cannot be solved optimally simultaneously . Related work. Sasaki and Carlini [16] defined a quantum matching machine which aims at pairing a giv en ‘feature’ state with the closest out of a set of ‘template’ states. The problem is formulated in a Bayesian framew ork with uniform priors over the feature and template pure states which are considered to be unkno wn. Ber gou and Hillery [17] introduced a discrimination machine, which corresponds to our set-up in the special case when the training set is of size n = 1 . The papers [18, 19] deal with the problem of quantum state identification as defined in this paper . The special case of Bayesian risk with uniform priors o ver pure states was solved in [18], with the small difference that the learning and classification steps are done in a single measurement over n + 1 systems. Howe ver , as in the case of state estimation [31], the proof relies on the special symmetry of the prior and does not co ver mixed states. Finally , the concept of quantum classification was already proposed in a series of papers [20, 21, 22]. Howe ver , the authors mostly focused on problem formulation, reduction between dif ferent problem classes and general issues regarding learnability . Other related papers which fall outside the scope of our in vestigation are [32, 33]. This paper is organised as follows. Section 2 gives a short overvie w of the classical classification set-up and introduces its quantum analogue. Section 3 discusses the LAN theory with emphasis on the qubit case. In section 4 we reformulate the classification problem in the asymptotic (local) framework, as an estimation problem with quadratic loss for the training set. The main result is Theorem 5.1 of Section 5 which gives the mimimax excess risk for the case of known priors. The case of unknown priors is treated Section 5.2. The optimal classifier is compared to the plug-in procedure based on optimal state estimation in Section 5.1. The geometry of the problem is captured by the Bloch ball illustrated in Figure 4. W e conclude the paper with discussions. 2. Classical and quantum lear ning 2.1. Classical Learning Let ( X, Y ) be a pair of random variables with joint distribution P over the measure space ( X × { 0 , 1 } , Σ) . In the classical setting X is usually a subset of R p and Y is a binary variable. In a first stage we are giv en a training set of n i.i.d. pairs { ( X 1 , Y 1 ) , . . . , ( X n , Y n ) } with distribution P , from which we would like to ‘learn’ about P . In the second stage we are presented with a ne w sample X and we are asked to guess its unseen label Y . For this we construct a (random) classifier ˆ h n : X → { 0 , 1 } which depends on the data ( X 1 , Y 1 ) , . . . , ( X n , Y n ) . Its ov erall accuracy is measured in terms Quantum learning: optimal classification of qubit states 5 of the expected err or rate according the data distribution P , P e ( ˆ h n ) = P ( ˆ h n ( X ) 6 = Y ) = E [1 ˆ h n ( X ) 6 = Y ] , where 1 C is the indicator function equal to 1 if C is true, and 0 otherwise. Howe ver the error rate itself does not give a good indication on the performance of the learning method. Indeed, even an ‘oracle’ who knows P exactly has typically a non-zero error: in this case the optimal ˆ h is the Bayes classifier which chooses the label that is more probable with respect to conditional distribution P ( y | x ) h ∗ ( X ) = 0 if η ( X ) ≤ 1 / 2 1 if η ( X ) > 1 / 2 (1) where η ( x ) := P ( Y = 1 | x ) . The Bayes risk is P e ( h ∗ ) = E [ E [1 ˆ h ∗ ( X ) 6 = Y | X ]] = 1 2 (1 − E [ | 1 − 2 η ( X ) | ]) . An alternativ e view of the Bayes classifier which fits more naturally in the quantum set-up is the following. W e are giv en data X whose probability distribution is either P 0 ( X ) := P ( X | Y = 0) or P 1 ( X ) := P ( X | Y = 1) and we would like to test between the two hypotheses. W e are in a Bayesian set-up where the hypotheses are chosen randomly with prior distributions π i = P ( Y = i ) . The optimal solution of this problem is the well known likelihood ratio test: we choose the hypothesis with higher likelihood h ∗ ( X ) = 0 if π 0 P 0 ( X ) > π 1 P 1 ( X ) 1 if π 0 P 0 ( X ) ≤ π 1 P 1 ( X ) which can be easily verified to be identical to the pre viously defined Bayes classifier . The Bayes risk can be written as P ∗ e = 1 2 (1 − k π 0 p 0 − π 1 p 1 k 1 ) , (2) where p i are the densities of P ( X | Y = i ) with respect to some common reference measure. Returning to the classfication set-up where P is unknown, we see that a more informativ e performance measure for ˆ h n is the excess risk : R ( ˆ h n ) = P e ( ˆ h n ) − P e ( h ∗ ) ≥ 0 (3) which measures ho w much worse the procedure ˆ h n performs compared to the performance of the oracle classifier . In statistical learning theory one is primarily interested in consistent classifiers, for which the excess risk conv erges to 0 as n → ∞ , and then in finding classifiers with fast con ver gence rates [2, 3]. But how to compare dif ferent learning procedures? One can always design algorithms which work well for certain distributions and badly for others. Here we take the statistical approach and consider that all prior information about the data is encoded in the statistical model { P θ : θ ∈ Θ } i.e. the data comes from a distribution which depends on some unkno wn parameter θ belonging to a parameter space Θ . The later may be a subset of R k (parametric) or a large class of distrib utions with certain ‘smoothness’ properties (non-parametric). One can then define the maximum risk of ˆ h n R max ( ˆ h n ) := sup θ ∈ Θ R θ ( ˆ h n ) Quantum learning: optimal classification of qubit states 6 where R θ denotes the excess risk when the underlying distribution is P θ . A procedure ˜ h n is called minimax if its maximum risk is smaller than that of any other procedure R max ( ˜ h n ) = inf ˆ h n R max ( ˆ h n ) = inf ˆ h n sup θ ∈ Θ R θ ( ˆ h n ) . (4) Alternativ ely one can take a Bayesian approach and optimise the av erage risk with respect to a giv en prior over Θ . Example 2.1. Let ( X , Y ) ∈ { 0 , 1 } 2 with unknown parameter s η (0) , η (1) and P ( X = 0) , satisfying η (0) < 1 / 2 and η (1) > 1 / 2 . Then the Bayes classifier is h ∗ (0) = 0 and h ∗ (1) = 1 . On the other hand, fr om the training sample one can estimate η ( i ) and obtain the concentration r esult P [ ˆ η n (0) < 1 / 2 and ˆ η n (1) > 1 / 2] = 1 − O (exp( − cn )) . Thus the plug-in estimator ˆ h n obtained by replacing η by ˆ η n in (1) is equal to h ∗ with high pr obability and the excess risk is exponentially small. The crucial feature leading to e xponentially small risk w as the fact that the regression function η ( X ) is bounded away from the critical value 1 / 2 . This situation is rather special but shows that the beha viour of the excess risk depends on the properties of η around the v alue 1 / 2 . Let us look at another simple example with a dif ferent behaviour . Example 2.2. Let ( X , Y ) ∈ R × { 0 , 1 } with P ( X | Y = 0) = N ( a, 1) , P ( X | Y = 1) = N ( b, 1) for some unknown means a < b , and P ( Y = 0) = 1 / 2 . F r om F igur e 2.1 we can see that p 0 ( x ) ≤ p 1 ( x ) if and only if x ≥ ( a + b ) / 2 so that the Bayes classifier is h ∗ ( x ) = 0 if x < ( a + b ) / 2 1 if x ≥ ( a + b ) / 2 The Bayes risk is equal to the orang e area under the two curves. Again a natural classifier is obtained by estimating the midpoint ( a + b ) / 2 and plugging into the above formula. The additional err or is the area of the gr een triangle. Since ( ˆ a + ˆ b ) / 2 − ( a + b ) / 2 ≈ 1 / √ n one can deduce that R ( ˆ h n ) = O ( n − 1 ) , and it can be shown that this rate of con ver gence is optimal [34]. From this example we see that the rate is determined by the behaviour of the regression function η around 1 / 2 , namely in this case P ( | η ( x ) − 1 / 2 | ≤ t ) = O ( t ) , t ≥ 0 which is called the mar gin condition . Roughly speaking, in a parametric model satisfying the margin condition, the excess risk goes to zero as O n − 1 . In non-parametric models (which are the main focus of learning theory), arbitrarily slow rates are possible depending on the complexity of the model and the beha viour of the regression function [34]. According to V apnik [3], one of the principles of statistical learning is: “when solving a problem of interest, do not solve a more general problem as an intermediate step. ” This is interpreted as saying that learning procedures which estimate first the statistical model (or Quantum learning: optimal classification of qubit states 7 0.2 x 0.15 0.1 8 0.05 0 6 4 2 0 a + b 2 ˆ a + ˆ b 2 π 0 p 0 ( x ) π 1 p 1 ( x ) Figure 1. Likelihood functions for two normal distributions with means a, b . The Bayes risk is the area of the orange triangle. The excess risk is the area of the green triangle regression function) and then plug this estimate into the Bayes classifier , are less ef ficient than methods which aim at constructing ˆ h ( x ) directly . Recently it has been shown [34] that this is not necessarily the case if some type of margin condition is assumed, and that plug-in estimators ˆ h P L U G - I N ( x ) = 1 ˆ η ( x ) ≥ 1 / 2 . (5) can perform close to, or at ‘fast n − 1 rates’. In this paper we show that at least in what concerns the constant in front of the rate, dir ect quantum learning performs better than plug in methods based on optimal state estimation . This is a purely quantum phenomenon which stems from the incompatibility between the optimal measurements for estimation and learning. 2.2. Quantum Learning W e no w consider the quantum counterpart of the learning problem, the classification of quantum states. In this case, X is replaced by a Hilbert space of dimension d . T o find the counterpart of P we write P ( dx, y ) = P ( dx | y ) P ( y ) and replace the conditional distributions P ( dx | y = 0) and P ( dx | y = 1) by density matrices ρ and σ , while P ( y ) describes prior probabilities over the states, usually denoted by π y := P ( Y = y ) . There is no direct counterpart of the object x , since the quantum state is identified with its description in terms of a density matrix; howe ver , one can think of x as a set of values obtained by measuring the state ρ . The training set consists of n i.i.d. pairs { ( τ 1 , Y 1 ) , . . . , ( τ n , Y n ) } , where τ i = ρ if Y i = 0 and τ i = σ if Y i = 1 . Thus we are randomly gi ven copies of ρ and σ together with their labels, but we do not know what ρ and σ are. After a permutation the joint state of the training set can be concisely written as ρ ⊗ n 0 ⊗ σ ⊗ n 1 , where n y is the number of copies for which Y j = y . The experimenter is allo wed to make any physical operations on the training set (such as unitary ev olution or measurements) and outputs a binary-valued measurement C 2 with PO VM elements c M n := ( b P n , 1 − b P n ) . This (random) PO VM plays the role of the classical classifier ˆ h n : gi ven a ne w copy of the quantum state whose label is unknown, we apply the measurement Quantum learning: optimal classification of qubit states 8 T able 1. Comparison of classical and quantum learning. element classical learning quantum learning distribution P ( ρ, σ ) with priors ( π 0 , π 1 ) training example ( x, y ) ( ρ, 0) or ( σ , 1) training set { ( x 1 , y 1 ) , . . . , ( x n , y n ) } ρ ⊗ n 0 ⊗ σ ⊗ n 1 function classifier ˆ h measurement b P optimal function h ∗ ( x ) = 1 η ( x ) ≥ 1 / 2 P ∗ = [ π 0 ρ − π 1 σ 1 ] + minimum risk 1 2 (1 − E [ | 1 − 2 η ( X ) | ]) 1 2 (1 − T r[ | π 1 σ − π 0 ρ | ]) risk P ( ˆ h ( X ) 6 = Y ) − P ∗ e E T r h ( π 1 σ − π 0 ρ )( b P − P ∗ ) i c M n to guess whether the state is ρ or σ . The accuracy is measured in terms of the expected misclassification error: P e ( c M n ) = E h π 0 T r[ ρ ( 1 − b P n )] + π 1 T r[ σ b P n ] i where the expectation is taken o ver the outcomes b P n . The Bayes classifier M ∗ is nothing but the Helstrom measurement [11] which optimally discriminates between known states ρ, σ with priors π 0 , π 1 . In this case M ∗ = ( P ∗ , 1 − P ∗ ) where P ∗ is the projection onto the subspace of positiv e eigen values of the operator π 0 ρ − π 1 σ , i.e. P ∗ = [ π 0 ρ − π 1 σ ] + . Note that if both eigen v alues are of the same sign, the optimal procedure is to choose the state with higher π i without making any measurement at all. The Helstr om risk can be expressed as: P ∗ e = 1 2 (1 − T r[ | π 1 σ − π 0 ρ | ]) . which is the quantum extension of (2). As before, the performance of an arbitrary classifier c M n is measured by the excess risk: R ( c M n ) = P e ( c M n ) − P ∗ e = E T r h ( π 1 σ − π 0 ρ )( b P n − P ∗ ) i , (6) which is expected to v anish asymptotically with n . In T able 1 we summarise the analogous concepts in the classical and the quantum learning set-up. Besides these obvious correspondences we would like to point out some interesting differences. Based on the coin toss example 2.1 one may expect that the classification of two qubit states should exhibit similar exponentially fast rates. In fact as we will show in this paper , the rate is n − 1 as in example 2.2 where the data is not discrete but continuous and the regression function is not bounded away from 1 / 2 . A possible explanation is the fact that in the quantum case the ‘data’ to be labelled is a quantum system and the distribution of the outcome depends on the measurement. A helpful way to think about it is illustrated in Figure 2.2. The unknown label is the input of a black box which outputs the data X with conditional distribution P ( X | Y ) . In the quantum case the box has an additional input, the measurement choice which appears as a parameter in the conditional distribution and is controlled by the experimenter . The game is to learn from the training set the optimal v alue of this parameter , for which the identification of the label Y is most facile. This set-up resembles that of active learning [35] where the training data X i are activ ely chosen rather than collected randomly . 2.3. Local minimax formulation of optimality W e no w gi ve the precise formulation of what we mean by asymptotic optimality of a learning strategy { c M n : n ∈ N } . As in the classical case we construct a model which contains all Quantum learning: optimal classification of qubit states 9 Y P X Classifier Y ^ ^ P ( X | Y , ˆ P ) Figure 2. Quantum learning seen as classical learning with data distribution depending on on additional parameter controlled by the experimenter unknown parameters of the problem: the two states ρ, σ and the prior π 0 . W e denote these parameters collectively by θ which belongs to a parameter space Θ ⊂ R k . When some prior information is av ailable about the model, it can be included by restricting to a sub-model of the general one. As in the classical case we denote by R θ ( c M n ) , the risk of c M n at θ , and we can define the maximum risk as in (4). Ho wever , assuming for the moment that that the optimal rate of classification is n − 1 , we use a more refined performance measure which is the local version of the maximum risk R max around a fixed parameter θ 0 R ( l ) max ( c M n ; θ 0 ) := sup k θ − θ 0 k≤ n − 1 / 2+ nR θ ( c M n ) (7) where > 0 is a small number . Note that in the abov e definition the usual risk was multiplied by the in verse of its rate n so that we can expect R ( l ) max to hav e a non-trivial limit when n → ∞ . The reason for choosing the local maximum risk is that it reflects better the dif ficulty of the problem in dif ferent regions of the parameter space while the maximum risk captures the worst possible behavior over the whole parameter space. W e can think of the local ball k θ − θ 0 k ≤ n − 1 / 2+ as the intrinsic parameter space when the training set consists of n samples. Indeed a simple estimator θ 0 on a small proportion ˜ n = n 1 − of the sample locates the true parameter in such a ball with high probability (see Lemma 2.1 in [24]). Definition 2.1. The local minimax risk at θ 0 is defined as R ( l ) minmax ( θ 0 ) := lim sup n →∞ inf c M n R ( l ) max ( c M n ; θ 0 ) . A sequence of classifiers { ˜ M n : n ∈ N } is called locally asymptotic minimax if lim sup n →∞ R ( l ) max ( ˜ M n ; θ 0 ) = R ( l ) minmax ( θ 0 ) . W e identify tw o general learning strategies. The first one consists in estimating the states ρ, σ and prior π 0 (optimally) to get ˆ ρ, ˆ σ, ˆ π 0 and then constructing the classifier (measurement) as: b P P L U G - I N = [ ˆ π 0 ˆ ρ − ˆ π 1 ˆ σ ] + . (8) The second strategy aims at estimating the Helstrom projection P ∗ directly from the training set without passing through state estimation. As we will see, it turns out that in general the latter performs better than the former . In section 3 we revie w the concept of local asymptotic normality which means that locally , the training set can be ef ficiently approximated by a simple Gaussian model consisting of displaced thermal equlibrium states and classical Gaussian random v ariables. In section 4 we Quantum learning: optimal classification of qubit states 10 show how to reduce the local classification risk for qubits to an expectation of a quadratic form in the local parameters. This will simplify the problem of finding the optimal measurement of the training set, to that of finding the optimal measurement of a Gaussian state for a quadratic loss function [10]. 3. Local asymptotic normality In a series of papers [23, 24, 25] Gut ¸ ˘ a and Kahn and Gut ¸ ˘ a and Jencov a [26] de veloped a new approach to state estimation based on the extension of the classical statistical concept of local asymptotic normality [27]. Using this tool one can cast the problem of (asymptotically) optimal state estimation into a much simpler one of estimating the mean of a Gaussian state with known v ariance. Local asymptotic normality provides a conv enient description of quantum statistical models in volving i.i.d. quantum states which can also be applied to the present learning problem. In this section we will giv e a brief introduction to this subject in as much as it is necessary for this paper and we refer to [25] for proofs and a more in depth analysis. 3.1. Local asymptotic normality in classical statistics A typical statistical problem is the estimation of some unknown parameter θ from a sample X 1 , . . . , X n ∈ X of independent, identically distributed random variables drawn from a distribution P θ ov er a measure space ( X , Σ) . If θ belongs to an open subset of R k for some finite dimension k and if the map θ → P θ is sufficiently smooth, then widely used estimators ˆ θ n ( X 1 , . . . , X n ) such as the maximum likelihood are asymptotically optimal in the sense that they con ver ge to θ at a rate n − 1 / 2 and the error has an asymptotically normal distribution √ n ( ˆ θ n − θ ) L − → N (0 , I − 1 ( θ )) , (9) where the right side is the lower bound set by the Cram ´ er-Rao inequality for unbiased estimators. T o give a simple example, if X i ∈ { 0 , 1 } is the result of a coin toss with P [ X i = 1] = θ and P [ X i = 0] = 1 − θ then the sufficient statistic ˆ θ n = 1 n n X i =1 X i satisfies (9) by the Central Limit Theorem (CL T). Naturally , the first inquiries into quantum statistics concentrated on generalising the Cram ´ er- Rao inequality to unbiased measurements, and on finding asymptotically optimal estimators which achiev e the quantum version of the Fisher information matrix [11, 10, 36]. Ho wev er it was found that due to the additional uncertainty introduced by the non-commutati ve nature of quantum mechanics the situation is essentially dif ferent from the classical case. A summary of these finding is (i) the multi-dimensional version of the Cram ´ er-Rao bound is in general not achie vable; (ii) the optimal measurement depends on the loss function, i.e. the quadratic form ( ˆ θ − θ ) t G ( ˆ θ − θ ) and different weight matrices G lead in general to incompatible measurements. Quantum learning: optimal classification of qubit states 11 As we will see, these issues can be ov ercome by adopting a more modern perspective to asymptotic statistics provided by the technique of local asymptotic normality [27, 37]. Instead of analysing particular estimation problems, the idea is to consider the structure of the statistical model underlying the data and to approximate it by a simpler model for which the statistical problems are easy to solv e. In order to obtain a non-tri vial limit model it mak es sense to rescale the parameters according to their uncertainty , so we assume that θ is localised in a region of size n − 1 / 2 and we can write θ = θ 0 + h/ √ n with θ 0 known and h ∈ R k the local parameter to be estimated. Such an assumption does not restrict the generality of the problem since one can use an adapti ve two-steps procedure where a rough estimate θ 0 is obtained in the first step using a small part of the sample, and the rest is used for the accurate estimation of the local parameter h . Local asymptotic normality means that the sequence of (local) statistical models P n := n P n θ 0 + h/ √ n : k h k < C o , n ∈ N (10) depending ‘smoothly’ on h , con verges to the Gaussian shift model G := N ( h, I − 1 ( θ 0 )) : k h k < C (11) where we observe a single Gaussian variable with mean h and fix ed and known variance. The con vergence has a precise mathematical definition in terms of the Le Cam distance between two statistical models which quantifies the extent to which each model can be ‘simulated’ by randomising data from the other . Definition 3.1. A positive linear map T : L 1 ( X , A , P ) → L 1 ( Y , B , Q ) is called a stochastic oper ator (or randomisation) if k T ( p ) k 1 = k p k 1 for every p ∈ L 1 + ( X ) . For simplicity we consider only dominated models for which all distributions have densities with respect to some fixed reference distribution. In this case a randomisation is the classical analogue of a quantum channel. Definition 3.2. Let P := { P θ : θ ∈ Θ } and Q := { Q θ : θ ∈ Θ } be two dominated statistical models with distributions having pr obability densities p θ := d P θ /d P and q θ := d Q θ /d Q . The deficiencies δ ( P , Q ) and δ ( Q , P ) ar e defined as δ ( P , Q ) := inf T sup θ ∈ Θ k T ( p θ ) − q θ k 1 δ ( Q , P ) := inf S sup θ ∈ Θ k S ( q θ ) − p θ k 1 wher e the infimum is taken over all randomisations T , S . The Le Cam distance between P and Q is ∆( P , Q ) := max( δ ( Q , P ) , δ ( P , Q )) . W ith this definitions the local asymptotic normality for i.i.d. parametric models can be formulated as Theorem 3.3. The sequence of local models (10) con verg es in the Le Cam distance to the Gaussian shift model (11) lim n →∞ ∆( P n , G ) = 0 . This statement can be extended to slowly increasing local neighbourhoods k h k ≤ n with precise con vergence rate for the Le Cam distance. Quantum learning: optimal classification of qubit states 12 3.2. Local asymptotic normality in quantum statistics W e will now describe the quantum version of local asymptotic normality for the simplest case of a family of spin states. The general result v alid for arbitrary finite dimensional systems can be found in [25]. W e are giv en n spins independent identically prepared in the state ρ ~ r = 1 2 ( 1 + ~ r~ σ ) where ~ r is the unknown Bloch vector of the state and ~ σ = ( σ x , σ y , σ z ) are the P auli matrices in M ( C 2 ) . Follo wing the methodology of the previous section, we concentrate on the structure of the statistical model itself rather than optimal state estimation. The latter , and other statistical problems can be solved easily once the con vergence to a Gaussian model is established. By measuring a small proportion n 1 − n of the systems we can devise an initial rough estimator ρ 0 := ρ ~ r 0 so that with high probability the state is in a ball of size n − 1 / 2+ around ρ 0 [23]. W e label the states in this ball by the local parameter ~ u ρ ~ u/ √ n = 1 2 1 + ( ~ r 0 + ~ u/ √ n ) ~ σ and define the local statistical model by Q n := { ρ n ~ u : k ~ u k ≤ n } , ρ n ~ u := ρ ⊗ n ~ u/ √ n . (12) By choosing a coordinate system ( ~ a 1 , ~ a 2 , ~ a 3 ) with ~ a 3 along ~ r 0 and writing ~ u = u 1 ~ a 1 + u 2 ~ a 2 + u 3 ~ a 3 we observe that ρ ~ u/ √ n is essentially obtained by perturbing the eigen v alues of ρ 0 by u 3 / 2 √ n and rotating it with a ‘small’ unitary U := exp( i ( − u 2 ~ a 1 + u 1 ~ a 2 ) ~ σ / 2 r 0 √ n ) , r 0 := k ~ r 0 k . The splitting into ‘classical’ and ‘quantum’ parameters u 3 and ( u 1 , u 2 ) can be intuiti vely explained through the ‘big Bloch sphere’ picture commonly used to describe spin coherent [38] and spin squeezed states [39]. Let L j := n X i =1 ~ a j · ~ σ ( i ) , j = 1 , 2 , 3 be the collecti ve spin components along the directions ~ a j . By the Central Limit Theorem, the distributions of L i with respect to ρ ⊗ n 0 con verge as 1 √ n ( L 3 − nr 0 ) D − → N (0 , 1 − r 2 0 ) , 1 √ n L 1 , 2 D − → N (0 , 1) , so that the joint spins state can be pictured as a vector of length nr 0 whose tip has a Gaussian blob of size √ n representing the uncertainty in the collectiv e variables (see Figure 3.2). Furthermore, by a law of lar ge numbers heuristic we estimate the commutators 1 √ n L 1 , 1 √ n L 2 = 2 i 1 n L 3 ≈ 2 ir 0 1 , 1 √ n L 1 , 2 , 1 √ n L 3 ≈ 0 . Quantum learning: optimal classification of qubit states 13 • z x √ n y nr 0 ! n (1 − r 2 0 ) Figure 3. Big ball picture of the collectiv e state of identical mixed spins. The total spin is represented as a vector of length nr 0 with a 3D uncertainty blob of size √ n in the x, y directions and q n (1 − r 2 0 ) in the z direction. This suggests that L 1 / √ 2 r 0 n and L 2 / √ 2 r 0 n con verge to the canonical coordinates Q and P of a quantum harmonic oscillator in a thermal equilibrium state Φ := (1 − p ) ∞ X k =0 p k | k ih k | , p = 1 − r 0 1 + r 0 , where {| k i : k ≥ 0 } represents the Fock basis. Moreov er the (rescaled) component 1 √ n ( L 3 − nr 0 ) con verges to a classical Gaussian variable X ∼ N := N (0 , 1 − r 2 0 ) which is independent of the quantum state. Note that the Gaussian limit state has both quantum and classical components and should be identified with the state Φ ⊗ N on the von Neumann algebra B ( ` 2 ( N )) ⊗ L ∞ ( R ) . What is the Gaussian state when the spins are in the ‘perturbed’ state ρ n ~ u ? By applying the same argument we obtain that the v ariables Q, P, X pick up expectations which (in the first order in n − 1 / 2 ) are proportional to the local parameters ( u 1 , u 2 , u 3 ) while the varia nces remain unchanged. More precisely the oscillator is in a displaced thermal equilibrium state Φ ~ u := D ( ~ u )Φ D ( ~ u ) ∗ , where D ( ~ u ) is the displacement operator D ( ~ u ) := exp i ( − u 2 Q + u 1 P ) / √ 2 r 0 , and the classical bit has distribution N ~ u := N ( u 3 , 1 − r 2 0 ) . Definition 3.4. The quantum Gaussian shift model G is defined by the family of quantum- classical states G := { Φ ~ u ⊗ N ~ u : ~ u ∈ R 3 } (13) on B ( ` 2 ( N )) ⊗ L ∞ ( R ) . Having defined the sequence of local models Q n and the Gaussian shift model, we need to define the quantum counterparts of randomisations and con ver gence of models. The natural Quantum learning: optimal classification of qubit states 14 analogue of a classical randomisation is a quantum channel, i.e. completely positi ve, trace preserving map C : T 1 ( H ) → T 1 ( K ) where T 1 ( H ) represents the trace class operators on H . Ho wever , as we saw above, a sequence of quantum statistical models may con verge to a quantum-classical one. The mathematical frame work covering randomisations of both classical and quantum statistical models is that of von Neuman algebras and channel s between their preduals. In finite dimensions this simply means that we deal with channels between block diagonal matrix algebras. W e can now define the Le Cam distance between two quantum models in the same way as in definition 3.2 with classical randomisation replaced by quantum ones and the k · k 1 representing the norm on the predual, which is the trace norm in the case of density matrices. Theorem 3.5. Let Q n be the sequence of statistical models (12) for n i.i.d. local spin states. and let G n be the restriction of the Gaussian shift model (13) to the range of parameters k ~ u k ≤ n . Then lim n →∞ ∆( Q n , G n ) = 0 , i.e. ther e exist sequences of c hannels T n and S n such that lim n →∞ sup k u k≤ n k Φ ~ u ⊗ N ~ u − T n ( ρ n ~ u ) k 1 = 0 , lim n →∞ sup k u k≤ n k ρ n ~ u − S n (Φ ~ u ⊗ N ~ u ) k 1 = 0 . (14) T o conclude this section we would like to make a few comments on the significance of the abov e result. The first point is that although it was intuitiv ely illustrated using the Central Limit Theorem, the concept of local asymptotic normality provides a stronger characterisation of the ‘Gaussian approximation’. Indeed the con vergence in Theorem 3.5 is strong (in L 1 ) rather than weak (in distribution), it is uniform o ver a range of local parameters rather than at a single point, and has an operational meaning based on quantum channels. Secondly , one can exploit these features to devise asymptotically optimal measurement strategies for state estimation and prove that the Hole vo bound [10] is asymptotically attainable [40]. Thirdly , the result can be applied to other quantum statistical problems inv olving i.i.d. qubit states such as cloning, teleportation benchmarks, quantum learning, and can serve as a mathematical framew ork for analysing quantum state transfer protocols. 4. Local f ormulation of the classification problem In this section we reformulate the problem of quantum state classification in the ‘local’ set-up. This allo ws us to replace, on the one hand the excess error probability by a quadratic form in local parameters, and on the other hand the training set consisting of i.i.d. spins by a simpler Gaussian shift model. Throughout the section we restrict to the case where the priors π 0 , π 1 are kno wn. In Section 5.2 we sho w that the results for known priors can easily be extended to unknown ones by simply estimating them from the counts of ρ and σ states in the training sample. Quantum learning: optimal classification of qubit states 15 4.1. The loss function Recall that the classification problem is to discriminate between two unknown states ρ and σ by learning from a training set of n labelled systems prepared randomly in one of the states with probabilities π 0 and π 1 . For this we measure the training set and produce an outcome which is itself a measurement c M n := ( b P n , 1 − b P n ) on C 2 . The accuracy of the procedure is measured by the excess risk (6): R ( c M n ) = E T r h ( π 1 σ − π 0 ρ )( b P n − P ∗ ) i , (15) with P ∗ = [ π 0 ρ − π 1 σ ] + . Since any binary measurement is a mixture of projective PO VM’ s [41], we can assume without loss of generality that b P n is a projection and pull back the randomness into the definition of the training set measurement. As e xplained in section 3.2, the a priori unknown states ρ and σ can be localised with high probability in n − 1 / 2+ neighbourhoods of ρ 0 and σ 0 by sacrificing a small proportion of the training set systems; this means that ρ 0 and σ 0 are known and can be used by the classification procedure. Let ~ r 0 and ~ s 0 be the Bloch v ectors of ρ 0 and σ 0 and let us parametrise their neighbourhoods as follows ρ = ρ ~ u/ √ n = 1 2 1 + ~ r 0 + ~ u √ n ~ σ , σ = σ ~ v / √ n = 1 2 1 + ~ s 0 + ~ v √ n ~ σ . (16) Let P 0 := [ π 0 ρ 0 − π 1 σ 0 ] + be the optimal projection corresponding to the pair ( ρ 0 , σ 0 ) and note that it can have dimension one, or it can be zero or identity . In the second case, the optimal measurement is trivial , one can guess the state without measuring by checking whether the operator π 0 ρ 0 − π 1 σ 0 is positiv e or negativ e. Lemma 4.1. Let ( ρ 0 , σ 0 ) and ( π 0 , π 1 ) satisfy k π 0 ~ r 0 − π 1 ~ s 0 k < | π 0 − π 1 | . Then P 0 is either zer o or identity and the local minimax excess risk satisfies inf c M n sup k ~ u k , k ~ v k≤ n P e ( c M n ) − P ∗ e = O (exp( − cn )) for some c > 0 . Pr oof. Note that the inequality is satisfied only if π 0 6 = π 1 and it implies that π 0 ρ 0 − π 1 σ 0 = π 0 − π 1 2 1 + π 0 ~ r 0 − π 1 ~ s 0 π 0 − π 1 ~ σ it a positiv e or negativ e operator depending on the sign of π 0 − π 1 . Since both eigen values of π 0 ρ 0 − π 1 σ 0 are non-zero, there exists a constant η > 0 such that k π 0 ρ 0 − π 1 σ 0 − A k 2 ≤ η implies that A is also a positive or negati ve operator . In fact, when n is large enough all π 0 ρ ~ u/ √ n − π 1 σ ~ v / √ n with k ~ u k , k ~ v k ≤ n hav e this property for some other constant ˜ η . Quantum learning: optimal classification of qubit states 16 Consider a simple measurement on the training set where the states are measured separately in the three bases of the Pauli matrices and the outcomes averages are used to construct a estimators of the states ρ ~ u/ √ n and σ ~ v / √ n . Then by basic concentration inequalities we get P π 0 ρ ~ u/ √ n − ρ ˆ ~ u/ √ n + π 1 σ ~ v / √ n − σ ˆ ~ v / √ n 2 ≥ ˜ η ≤ exp ( − cn ) which means that with exponentially small probability error the plug-in estimator of P ∗ := [ π 0 ρ ~ u/ √ n − π 1 σ ~ v / √ n ] + will be equal to P ∗ which is zero or identity . From now on we will w ork under the assumption that k π 0 ~ r 0 − π 1 ~ s 0 k > | π 0 − π 1 | , (17) so that P 0 := [ π 0 ρ 0 − π 1 σ 0 ] + is a one dimensional projection whose Bloch vector is ~ p 0 = ~ d 0 k ~ d 0 k := π 0 ~ r 0 − π 1 ~ s 0 k π 0 ~ r 0 − π 1 ~ s 0 k . The Helstrom projection P ∗ for the pair of unknown states ( ρ, σ ) has Bloch vector ~ p = ~ d k ~ d k = π 0 ~ r 0 + ~ u √ n − π 1 ~ s 0 + ~ v √ n π 0 ~ r 0 + ~ u √ n − π 1 ~ s 0 + ~ v √ n = ~ d 0 + ~ z √ n ~ d 0 + ~ z √ n , (18) where ~ z := π 0 ~ u − π 1 ~ v is a relativ e parameter and ~ d := ~ d 0 + ~ z √ n . As discussed before, we can take the estimator c M n to be a projectiv e measurement c M n := ( b P n , 1 − b P n ) , so to minimise the risk (15) we aim at producing an estimator b P n which is close to P ∗ . Since the latter is obtained by rotating P 0 with angle of order n − 1 / 2+ , we can assume without loss of generality that b P n has a Bloch v ector ˆ ~ p n which is a small rotation of ~ p 0 so that ˆ ~ p n = ~ p 0 + ˆ ~ z n / √ n k ~ p 0 + ˆ ~ z n / √ n k , (19) with ˆ ~ z n = O ( n ) a vector in the plane orthogonal to ~ p 0 . Expanding (18) and (19) in powers of n − 1 / 2 we get ~ p − ˆ ~ p n = 1 √ n " ~ z − ˆ ~ z n k ~ d 0 k − ~ d 0 ( ~ d 0 · ( ~ z − ˆ ~ z n )) k ~ d 0 k 3 # + 1 n " − ~ d 0 ( k ~ z k 2 − k ˆ ~ z n k 2 ) 2 k ~ d 0 k 3 + 3 ~ d 0 (( ~ d 0 · ~ z ) 2 − ( ~ d 0 · ˆ ~ z n ) 2 2 k ~ d 0 k 5 # + o ( n − 1 ) . W e now plug these e xpressions back into into (15) taking into account that ˆ ~ z n is perpendicular to ~ d 0 and obtain P e ( c M n ) − P ∗ e = E T r ( π 0 ρ − π 1 σ )( P − b P n ) = 1 2 E ~ d · ( ~ p − ˆ ~ p n ) = 1 4 n k ~ d 0 k E k ~ z ⊥ − ˆ ~ z n k 2 + o ( n − 1 ) Quantum learning: optimal classification of qubit states 17 where ~ z ⊥ = ~ z − ~ d 0 ( ~ z · ~ d 0 ) / k ~ d 0 k 2 is the projection of ~ z onto the plane orthogonal to ~ d 0 . It is clear no w that the rate of con ver gence of the excess risk (15) is n − 1 , so it is meaningful to optimise the quantity nR ( l ) max ( c M n ) , and the contribution coming from the o ( n − 1 ) term can be dropped. Since c M n is uniquely determined by ˆ ~ z n by (19), we define the quadratic loss function for the measurement on the training set in terms of local variables L (( ~ u, ~ v ) , ˆ ~ z n ) := 1 4 k ~ d 0 k k ~ z ⊥ − ˆ ~ z n k 2 , ~ z := ( π 0 ~ u − π 1 ~ v ) (20) and the associated renormalised risk is R ~ u,~ v ( ˆ ~ z n ) := E L (( ~ u, ~ v ) , ˆ ~ z n ) . The local maximum risk (7) around ( ρ 0 , σ 0 ) is then R ( l ) max ( ˆ ~ z n ; ρ 0 , σ 0 ) := sup k ~ u k , k ~ v k≤ n R ~ u,~ v ( ˆ ~ z n ) = sup k ~ u k , k ~ v k≤ n 1 4 k ~ d 0 k E k ~ z ⊥ − ˆ ~ z n k 2 . (21) In conclusion, we need to find the optimal measurement strategy on the training set with respect to the abov e quadratic form of the local parameters. 4.2. The tr aining set T o solve the abov e problem we employ the machinery of local asymptotic normality . As before, let ρ and σ be states in local neighbourhood of ρ 0 and respecti vely σ 0 described by (16). W e write their local Bloch vectors ( ~ u, ~ v ) as ~ u = u 1 ~ a 1 + u 2 ~ a 2 + u 2 ~ a 3 and ~ v = v 1 ~ b 1 + v 2 ~ b 2 + v 2 ~ b 3 where ( ~ a 1 , ~ a 2 , ~ a 3 ) and ( ~ b 1 , ~ b 2 , ~ b 3 ) are two coordinate systems which satisfy the conditions (see Figure 4) (i) ~ a 3 is parallel to ~ r 0 , (ii) ~ b 3 is parallel to ~ s 0 , (iii) ~ a 1 , ~ b 1 are in the plane ( ~ r 0 , ~ s 0 ) , (iv) ~ a 2 = ~ b 2 is perpendicular to the plane ( ~ r , ~ s ) . W ith these notations the local statistical model for the training set is T n := { ρ nπ 0 ~ u ⊗ σ nπ 1 ~ v : k ~ u k , k ~ v k ≤ n } and the corresponding Gaussian shift model is G (2) := { N ~ u ⊗ N ~ v ⊗ Φ ~ u ⊗ Φ ~ v : ~ u, ~ v ∈ R 3 } (22) where N ~ u := N ( √ π 0 u 3 , 1 − r 2 0 ) , N ~ v := N ( √ π 1 v 3 , 1 − s 2 0 ) , Φ ~ u := Φ r π 0 2 r 0 u 1 , r π 0 2 r 0 u 2 ; 1 2 r 0 , Φ ~ v := Φ r π 1 2 s 0 v 1 , r π 1 2 s 0 v 2 ; 1 2 s 0 (23) Quantum learning: optimal classification of qubit states 18 and Φ( q , p , v ) is a displaced thermal equilibrium state with means ( q, p ) and v ariance v . The following technical lemma sho ws that local asymptotic normality can be used to transfer the problem of the optimal classification from a training set consisting of qubits, to a Gaussian one. The arguments are rather standard though tedious, and since the same method has been used for finding the optimal estimation procedure for qubits [24], we refer to that paper for the proof. Lemma 4.2. Consider the pr oblems of finding asymptotically optimal strate gies for the models T n and r espectively G (2) n with r espect to the loss function (20) . Then the local minimax risks of both pr oblems conver ge to the same constant which is the the minimax risk of the unr estricted Gaussian shift model G (2) . In conclusion, the measurement of the training set should be aimed at optimally estimating the two parameter vector ~ z ⊥ directly , rather than using a ‘plug-in’ strategy where the three dimensional local parameters ( ~ u, ~ v ) are first (optimally) estimated and then the measurement b P n is constructed as in (8). W e will come back to this point later on when the two methods will be compared. 5. Optimal classifier In this section we formulate our main result characterising the asymptotically optimal measurement on the training set and deriv e the expression of the optimal excess risk. Summarising the previous section, we transformed the original problem into a parameter estimation one for the Gaussian shift model (22) with parameters ( ~ u, ~ v ) ∈ R 3 × R 3 . The parameter to be estimated ~ z ⊥ ∈ R 2 is a linear transformation of ( ~ u, ~ v ) ~ z ⊥ = ~ z − ~ d 0 ( ~ z · ~ d 0 ) / k ~ d 0 k 2 , ~ z := π 0 ~ u − π 1 ~ v i.e. we would lik e to minimise the risk R max ( ˆ ~ z ; ρ 0 , σ 0 ) := sup ~ u,~ v E L (( ~ u, ~ v ) , ˆ ~ z ) = sup ~ u,~ v 1 4 k ~ d 0 k E k ˆ ~ z − ~ z ⊥ k 2 . . Since the local parameters contain both classical and quantum components it is con venient to express the loss function L (( ~ u, ~ v ) , ˆ ~ z ) in terms of these components. Let ( ~ p 0 , ~ l 0 , ~ k 0 ) be the reference frame with ~ l 0 in the plane ( ~ r 0 , ~ s 0 ) . Denote by ϕ 0 , ϕ 1 the angles between ( ~ r 0 , ~ l 0 ) and respectiv ely ( ~ s 0 , ~ l 0 ) (see Figure 4). Then ~ z ⊥ = z l ~ l 0 + z k ~ k 0 with components z l = ( π 0 cos ϕ 0 u 3 − π 1 cos ϕ 1 v 3 ) + ( π 0 sin ϕ 0 u 1 + π 1 sin ϕ 1 v 1 ) := z ( c ) l + z ( q ) l , z k = π 0 u 2 − π 1 v 2 where z l was split into a contribution coming from the ‘classical’ parameters ( u 3 , v 3 ) , and another one from the ‘quantum’ parameters. Since the classical and quantum parts of the Gaussian model are independent it is easy to v erify that the optimal estimator ˆ ~ z can be written as ˆ ~ z = ( ˆ z ( c ) l + ˆ z ( q ) l ) ~ l 0 + ˆ z k ~ k 0 where ˆ z ( c ) l is the optimal estimator of z ( c ) l and ( ˆ z ( q ) l , ˆ z k ) are optimal estimators of ( z ( q ) l , z k ) obtained by (jointly) measuring the two quantum Gaussian components. The excess risk can Quantum learning: optimal classification of qubit states 19 be written as 4 k ~ d 0 k E h L ( ~ u, ~ v ) , ˆ ~ z i = E h ( z ( c ) l − ˆ z ( c ) l ) 2 i + E h ( z ( q ) l − ˆ z ( q ) l ) 2 + ( z k − ˆ z k ) 2 i where the classical and quantum contributions separate and can be optimised separately . The optimal choice for the classical estimator is ˆ z ( c ) l = √ π 0 cos ϕ 0 X r − √ π 1 cos ϕ 1 X s where ( X r , X s ) ∼ N ~ u ⊗ N ~ v denote the random variables making up the classical part of the limit Gaussian model. Its contrib ution to the excess risk is E z ( c ) l − ˆ z ( c ) l 2 = π 0 (1 − r 2 0 ) cos 2 ϕ 0 + π 1 (1 − s 2 0 ) cos 2 ϕ 1 . (24) On the other hand ( z ( q ) l , z k ) are the means of the canonical coordinates Q ( l ) := √ 2 r 0 π 0 sin ϕ 0 Q 1 + √ 2 s 0 π 1 sin ϕ 1 Q 2 , Q ( k ) := √ 2 r 0 π 0 P 1 − √ 2 s 0 π 1 P 2 (25) whose commutator is [ Q ( l ) , Q ( k ) ] = i (2 r 0 π 0 sin ϕ 0 − 2 s 0 π 1 sin ϕ 1 ) 1 := ic 1 . Now , the optimal joint measurement of canonical v ariables is the heterodyne type where the non-commuting coordinates are combined with the coordinates of an additional oscillator prepared in a squeezed state [10, 24]. The optimal mean square error is E h ( z ( q ) l − ˆ z ( q ) l ) 2 + ( z k − ˆ z k ) 2 i = V ar ( Q ( l ) ) + V ar ( Q ( k ) ) + | c | = π 0 sin 2 ϕ 0 + π 1 sin 2 ϕ 1 + 1 + 2 | π 0 r 0 sin ϕ 0 − π 1 s 0 sin ϕ 1 | (26) Adding the classical and quantum contributions (24) and (26) we obtain the minimax risk R ( l ) minmax ( ρ 0 , σ 0 ) = 2 + 2 | π 0 r 0 sin ϕ 0 − π 1 s 0 sin ϕ 1 | − r 0 s 0 cos ϕ 0 cos ϕ 1 4 k ~ d 0 k (27) which only depends on the states ( ρ 0 , σ 0 ) , for giv en priors ( π 0 , π 1 ) . Theorem 5.1. Consider the quantum classification pr oblem with training set ρ ⊗ π 0 n ⊗ σ ⊗ π 1 n wher e ρ, σ are unknown qubit states and ( π 0 , π 1 ) ar e known. Let R ( l ) minmax ( ρ 0 , σ 0 ) be the local minimax risk as defined in Section 2.3. Under the assumption (17) , R ( l ) minmax ( ρ 0 , σ 0 ) is given by (27) . The optimal measur ement consists of the following steps: (i) construct r ough estimators of ρ and σ by measuring n 1 − systems; (ii) transfer the localised spins state by T n as in Theor em 3.5 ; (iii) perform the optimal coher ent measur ement of ( Q ( l ) , Q ( k ) ) and combine with classical estimator ˆ z l c to pr oduce estimator b P n . Quantum learning: optimal classification of qubit states 20 ! r 0 ! s 0 π 1 " s 0 π 0 " r 0 ! d 0 ! p 0 ! a 1 ! a 2 ! a 3 ! b 3 ! b 1 ! b 2 ! u √ n ! v √ n ˆ ! z n √ n ! z ⊥ √ n ! l 0 ! k 0 ϕ 1 ϕ 0 Figure 4. Bloch ball geometry of the learning problem. The unknown states are localised in the two yellow balls centred at ~ r 0 and ~ s 0 and have local vectors ~ u/ √ n and ~ v / √ n coloured in purple. The three reference systems ( ~ a 1 , ~ a 2 , ~ a 3 ) , ( ~ b 1 , ~ b 2 , ~ b 3 ) and ( ~ p 0 , ~ l 0 , ~ k 0 ) are coloured in red. The green equatorial plane is orthogonal to ~ p 0 and contains the estimator ˆ ~ z n and the vector to be estimated ~ z ⊥ (coloured in purple). 5.1. Plug-in classifier based on optimal state estimation Here we compute the asymptotics of the renormalised risk of the plug-in classifier based on optimal state estimation. The problem of optimal state estimation for mixed i.i.d. qubits was solved in the asymptotic local minimax setting in [24]. The optimal measurement procedure is adaptiv e and the first two steps are identical to those of Theorem 5.1 (i) construct rough estimators of ρ and σ by measuring n 1 − systems; (ii) transfer the localised spins state by T n as in Theorem 3.5 ; (iii) Perform separate heterodyne measurements on the modes ( Q 1 , P 1 ) and ( Q 2 , P 2 ) and observe the classical components to obtain the estimators ˜ ~ u n and ˜ ~ v n . Once the states (local parameters) ha ve been estimated we can classify ne w states by applying Quantum learning: optimal classification of qubit states 21 the plug-in measurement f M n := ( e P n , 1 − e P n ) where e P n has Bloch vector ˜ ~ p = ˜ ~ d k ˜ ~ d k = ~ d 0 + ˜ ~ z n √ n ~ d 0 + ˜ ~ z √ n , ˜ ~ z n := ˜ ~ z ⊥ := ( π 0 ˜ ~ u n − π 1 ˜ ~ v n ) ⊥ . (28) Note that ˜ ~ z n was chosen to be the orthogonal component of ˜ ~ z onto the vector ~ p 0 rather than ˜ ~ z itself. Howe ver a simple T aylor expansion shows that the two estimators gi ve the same leading order contribution to the risk. As before, the minimax risk is the expectation of the quadratic loss function L (( ~ u, ~ v ) , ˜ ~ z ) defined in (20), but now with ˜ ~ z having a different distribution compared with the optimal ˆ ~ z . Again, we write ˜ z as ˜ z = ˜ z l ~ l 0 + ˜ z k ~ k 0 = ( ˜ z c l + ˜ z q l ) ~ l 0 + ˜ z k ~ k 0 and the risk is R max ( ˜ ~ z ; ρ 0 , σ 0 ) = 1 4 k ~ d 0 k E h ( z ( c ) l − ˜ z ( c ) l ) 2 + ( z ( q ) l − ˜ z ( q ) l ) 2 + ( z k − ˜ z k ) 2 i . While the contribution from the first term is gi ven by (24), the ‘quantum components’ hav e different variances due to the fact that we used a dif ferent heterodyne measurement. By using (25) and the fact that heterodyne adds a factor 1 / 2 to the variance of canonical coordinates we obtain E h ( z ( q ) l − ˜ z ( q ) l ) 2 i = π 0 sin 2 ϕ 0 ( r 0 + 1) + π 1 sin 2 ϕ 1 ( s 0 + 1) E ( z k − ˜ z k ) 2 = π 0 ( r 0 + 1) + π 1 ( s 0 + 1) (29) Adding the three contributions we get 4 k d 0 k R max ( ˜ ~ z ; ρ 0 , σ 0 ) = 2 + π 0 ( r 0 sin 2 ϕ 0 + r 0 − r 2 0 cos 2 ϕ 0 ) + π 1 ( s 0 sin 2 ϕ 1 + s 0 − s 2 0 cos 2 ϕ 1 ) . (30) Theorem 5.2. Consider the quantum classification pr oblem with training set ρ ⊗ π 0 n ⊗ σ ⊗ π 1 n wher e ρ, σ are unknown qubit states and ( π 0 , π 1 ) ar e known. Under the assumption (17) , the asymptotic renormalised maximum risk R max ( ˜ ~ z ; ρ 0 , σ 0 ) of the plug-in classifier (28) is given by (30) . Comparing the minimax risk (27) with the risk (30) of the plug-in classifier we get R max ( ˜ ~ z ; ρ 0 , σ 0 ) − R ( l ) minmax ( ρ 0 , σ 0 ) = π 0 r 0 (1 ± sin ϕ 0 ) 2 + π 1 s 0 (1 ∓ sin ϕ 1 ) 2 , with the signs are chosen according to the sign of π 0 r 0 sin ϕ 0 − π 1 s 0 sin ϕ 1 . This quantity is equal to zero if and only if sin ϕ 0 = ∓ 1 and sin ϕ 1 = ± 1 which means that the v ectors ~ r 0 and ~ s 0 are parallel and point in the same direction. For fixed priors, the dif ference is maximum when the ~ r 0 and ~ s 0 point in opposite directions and hav e length one. This can be easily understood from the Gaussian model. When the vectors are parallel then learning requires an optimal joint measurement of non-commuting v ariables ( Q 1 − Q 2 , P 1 − P 2 ) whose risk is the same as that of heterodyning the oscillators first and constructing linear combinations. In the anti-parallel case we need to measure commuting v ariables ( Q 1 + Q 2 , P 1 − P 2 ) which can be done directly , without any loss. Quantum learning: optimal classification of qubit states 22 5.2. The case of unknown priors The analysis so far deals with known priors π 0 , π 1 , which is the standard set-up usually considered in quantum statistics. In general, the priors may be unknown b ut can be estimated from the training set with a standard n − 1 / 2 error . Since the Helstrom measurement depends also on ( π 0 , π 1 ) , this uncertainty will bring an additional contribution to the excess risk. T o find it, one needs to go back to the deri vation of the quadratic loss function and add another unknown local parameter δ for the prior: π 0 = q 0 + δ / √ n . Then (18) becomes ~ p = ~ d k ~ d k = ~ d 0 + ~ z √ n + δ ( ~ r 0 + ~ s 0 ) √ n ~ d 0 + ~ z √ n + δ ( ~ r 0 + ~ s 0 ) √ n . , (31) By going through the same steps, we get to the quadratic loss function L (( ~ u, ~ v , δ ) , ˆ ~ z n ) := 1 4 k ~ d 0 k k ~ z ⊥ + δ ( ~ r 0 + ~ s 0 ) ⊥ − ˆ ~ z n k 2 , (32) where ( ~ r 0 + ~ s 0 ) ⊥ is the component orthogonal to ~ p 0 . As before, the training set can be cast into a Gaussian model, with an additional independent component Z ∼ N ( δ , π 0 π 1 ) . This means that when taking the expectation of L we get an additional factor k ( ~ r 0 + ~ s 0 ) ⊥ k 2 4 k ~ d 0 k V ar ( Z ) = π 0 π 1 k ( ~ r 0 + ~ s 0 ) ⊥ k 2 4 k ~ d 0 k . 6. Conclusions W e solved the problem of classifying two qubit states in the asymptotic local minimax statistical framework. Asymptotically the problem reduces to that of optimally estimating a sub-parameter of a quantum Gaussian model consisting of two independent oscillators in displaced thermal states with unknown means. The estimator is then used to construct an approximation of the (unknown) Helstrom measurement which is used to classify unlabelled states. The optimal procedure has excess risk of order n − 1 and we computed the exact constant f actor R ( l ) minmax ( ρ 0 , σ 0 ) as function of the two unkno wn states. Except in the special case of states with parallel Bloch v ectors, the optimal procedure performs strictly better than the plug-in classifier obtained by estimating the states and applying the corresponding Helstrom measurement. The difference is only a constant factor , but it would probably become significant in more interesting infinite dimensional models. Finally let us briefly discuss the Bayesian analogue of our result. In the Bayesian framework one would choose a ‘regular’ prior µ ( dρ × dσ ) o ver the two types of states and try to find the (asymptotically) optimal Bayes risk for this prior R µ opt := lim sup n →∞ inf c M n n Z µ ( dρ × dσ ) R ( ρ,σ ) ( c M n ) . When the states are pure and the prior is uniform, this has been done (even non- asymptotically) in [18], but the proof relies on the symmetry of the prior and cannot be applied to general ones, and mixed states. Based on a similar analysis done for state estimation[42], Quantum learning: optimal classification of qubit states 23 we expect that our result can be used to pro ve that R µ opt = Z R ( l ) minmax ( ρ 0 , σ 0 ) µ ( dρ 0 × dσ 0 ) . The intuitive explanation is that when n → ∞ the features of the prior µ are washed out and the posterior distribution concentrates in a local neighbourhood of the true parameter, where the behaviour of the classifiers is gov erned by the local minimax risk. Proving this relation is howe ver beyond the scope of this paper . Acknowledgments W e thank Richard Gill for useful discussions. M.G. was supported by the EPSRC Fellowship EP/E052290/1. References [1] Mitchell T 1997 Machine Learning 1st ed (McGraw-Hill Education) [2] Devroye L, Gy ¨ orfi L and Lugosi G 1996 A Pr obabilistic Theory of P attern Recognition 1st ed (Springer) [3] V apnik V 1998 Statistical Learning Theory (W iley) [4] Friedman J H, Hastie T and T ibshirani R 2003 Elements of Statistical Learning: Data Mining, Inference, and Pr ediction (Springer) [5] Bishop C M 2006 P attern r ecognition and machine learning (Springer) [6] Nielsen M and Chuang I 2000 Quantum Computation and Quantum Information (Cambridge: Cambridge Univ ersity Press) [7] W iseman H M and J M G 2009 Quantum measur ements and contr ol (Cambridge University Press) [8] Smithey D T , Beck, M, Raymer, M G and Faridani, A 1993 Phys. Re v . Lett. 70 1244–1247 [9] H ¨ affner H, H ¨ ansel W , Roos C F , Benhelm J, Chek-al kar D, Chwalla M, K ¨ orber T , Rapol U D, Riebe M, Schmidt P O, Becher C, G ¨ uhne O, D ¨ ur W and Blatt R 2005 Natur e 438 643–646 [10] Holev o A S 1982 Pr obabilistic and Statistical Aspects of Quantum Theory (North-Holland) [11] Helstrom C W 1976 Quantum Detection and Estimation Theory (Academic Press, New Y ork) [12] Leonhardt U 1997 Measuring the Quantum State of Light (Cambridge University Press) [13] Hayashi M (ed) 2005 Asymptotic theory of quantum statistical inference: selected papers (W orld Scientific) [14] Paris M G A and ˇ Reh ´ a ˇ cek J (eds) 2004 Quantum State Estimation [15] Barndorff-Nielsen O E, Gill, R and Jupp, P E 2003 J . R. Statist. Soc. B 65 775–816 [16] Sasaki M and Carlini A 2002 Physical Review A 66 022303 [17] Bergou J and Hillery M 2005 Phys. Rev . Lett. 94 160501 [18] Hayashi A, Horibe M and Hashimoto T 2005 Phys. Rev . A 72 052306 [19] A Hayashi M Horibe T H 2006 Phys. Rev . A 93 012328 [20] A ¨ ımeur E, Brassard G and Gambs S 2006 Pr oc. of the 19th Canadian Confer ence on Artificial Intelligence (Canadian AI’06) (Qu ´ ebec City , Canada: Springer) pp 433–444 [21] A ¨ ımeur E, Brassard G and Gambs S 2007 Pr oc. of the 24th International Confer ence of Machine Learning (ICML’07) (Corvallis, USA) pp 1–8 [22] Gambs S 2008 Quantum classification [23] Gut ¸ ˘ a M and Kahn J 2006 Phys. Rev . A 73 052108 [24] Gut ¸ ˘ a M, Janssens B and Kahn J 2008 Commun. Math. Phys. 277 127–160 [25] Kahn J and Gut ¸ ˘ a M 2009 Commun. Math. Phys. 289 597–652 [26] Gut ¸ ˘ a M and Jenc ¸ ov ´ a A 2007 Commun. Math. Phys. 276 341–379 [27] Le Cam L 1986 Asymptotic Methods in Statistical Decision Theory (Springer V erlag, New Y ork) [28] Gut ¸ ˘ a M, Adesso G and Bowles P Quantum teleportation benchmarks for independent and identically-distributed spin states and displaced thermal states in preparation [29] Bagan E, Baig M, Mu ˜ noz T apia R and Rodriguez A 2004 Phys. Rev . A 69 010304 [30] Bagan E, Ballester M A, Gill R D, Mu ˜ noz T apia R and Romero-Isart O 2006 Phys. Rev . Lett. 97 130501 [31] Bagan E, Ballester , M A, Gill, R D, Monras, A and Mun ˜ oz-T apia, R 2006 Phys. Rev . A 73 032301 [32] Gammelmark S and Molmer K 2009 New J ournal of Physics 11 033017 [33] Bisio A, Chiribella G, D’Ariano G M, Facchini S and Perinotti P 2010 Phys. Rev . A 81 032324 [34] Audibert J Y and Tsybakov A B 2007 Annals of Statistics 35 608–633 Quantum learning: optimal classification of qubit states 24 [35] Cohn D A, Ghahramani, Z and Jordan M I 1996 Journal of Artificial Intelligence Resear ch 4 129–145 [36] Belavkin V P 1976 Theor . Math. Phys. 26 213–222 [37] van der V aart A 1998 Asymptotic Statistics (Cambridge Uni versity Press) [38] Radcliffe J M 1971 J . Phys. A 4 313–323 [39] Kitagawa M and Ueda M 1993 Phys. Re v . A 47 5138–5143 [40] Gut ¸ ˘ a M and Kahn J Optimal state estimation: attainability of the Holev o bound in preparation [41] D’Ariano G M, Presti P L and Perinotti P 2005 Journal of Physics A 38 5979 [42] Gill R D 2008 Quantum Stochastics and Information: Statistics, F iltering and Contr ol ed Belavkin V P and Guta M (W orld Scientific, Singapore) pp 239–261
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment