Shaping Level Sets with Submodular Functions
We consider a class of sparsity-inducing regularization terms based on submodular functions. While previous work has focused on non-decreasing functions, we explore symmetric submodular functions and their \lova extensions. We show that the Lovasz ex…
Authors: Francis Bach (LIENS, INRIA Paris - Rocquencourt)
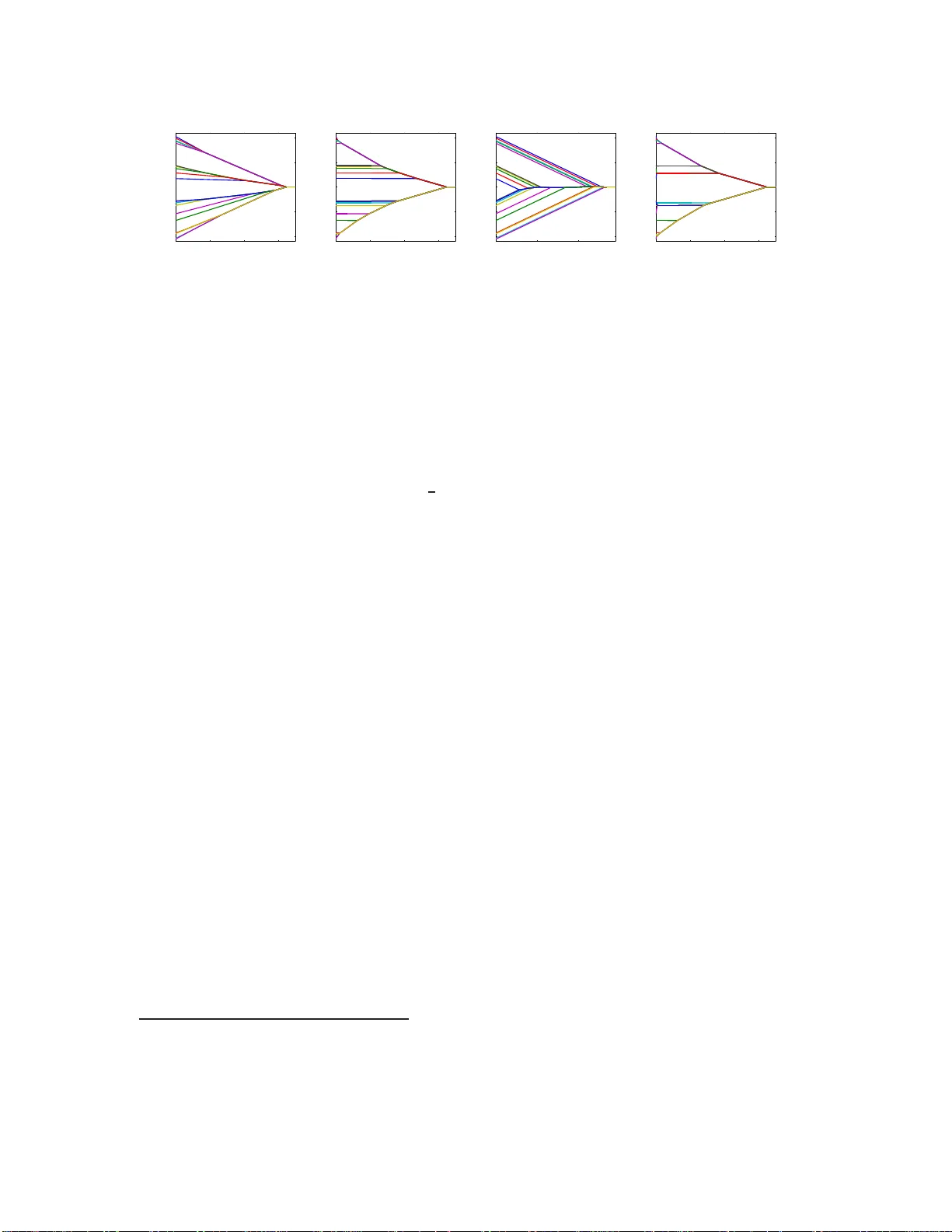
Shaping Lev el Sets with Submo dular F unctions F rancis Bac h INRIA - Sierra pro j e ct-team Lab oratoire d’Informatique de l’Ecole Normale Sup ´ erieure P aris, F rance francis.bac h@ens.fr Septem b er 6, 2018 Abstract W e consider a class of sparsit y-indu cing regularization terms based on submo dular functions. While previous w ork has focu s ed on non-decreasing functions, we e xplore symmetric sub m o d- ular fun ctio ns and their Lov´ asz ext en si ons. W e sho w that th e Lo v´ asz extension ma y b e seen as the con vex env elope of a fun ctio n that dep ends on lev el sets (i.e ., the set of indices whose correspondin g components of the u n derlying predictor ar e greater th a n a given constant): th i s leads to a class of conv ex structured regularization terms that imp ose prior know ledge on t h e leve l sets, and not only on the supp orts of th e un d erlying predictors. W e provide a unified set of optimization algori thms, suc h as pro ximal o p erators, and theoretic al guarantees (al low ed lev el sets and reco v ery conditions). By selecting sp ecific submodular fun ctio ns, w e give a new inter- pretation to known norms, suc h as the total v ariation; w e also define n ew norms, in particular ones that are based on order statistics wi th app l ication to clustering and outlier detection, and on noisy cut s in graphs with app li cation to c hange point d etectio n in the presence of outliers . 1 In tro duction The conce pt of parsimony is cen tral in ma n y scientifi c doma ins. In the context of statistics, signal pro cessing or ma c hine learning, it may take several forms. Classically , in a v ariable or feature selection problem, a sparse solution with ma ny zeros is sought so that the mo del is either mor e int erpre ta ble, c heap er to use, or simply matches av ailable prior knowledge (see, e.g., [1, 2, 3] and references therein). In this pap er, we instea d cons ider spar sit y-inducing regularization terms that will lead to solutions with many e qu a l va lues . A classical exa mple is the total v ariation in o ne or t wo dimensions, whic h lea ds to piecewise constan t so lutions [4, 5] and can be applied to v ar ious image lab elling problems [6, 5], o r c hange point detection tasks [7, 8, 9]. Ano ther example is the “Oscar” pena lt y which induces automatic grouping of the features [10]. In this pap er, w e follow the approach of [3], who designed sparsity-inducing norms based on non-de cr e a sing submodular functions, as a conv ex approximation to impos ing a specific prior o n the su pp orts of the predictors. Her e, w e show that a similar par allel holds for some other class of submo dular functions, namely non-negativ e set- functions whic h a re equal to zero for the full and empty s et. Our main instance of such functions are symmetric submodular functions. W e make the following contributions: − W e provide in Section 3 explicit links betw een prio rs on level sets and ce rtain submodular functions: we show that the Lo v´ asz extensio ns (see, e.g., [11] and a short review in Section 2) 1 asso ciated to these submo dular functions ar e the con vex en velopes (i.e., tigh test c o n v ex lo wer bo unds) of sp e cific functions that dep end on all level sets of the under lying vector. − In Section 4, w e rein terpret existing norms such as the total v ariation and des ign new norms, based on noisy cuts or order statis tics . W e pro pose applications to clustering and outlier detection, as well as t o c hange p oin t detectio n in the presence of outlier s. − W e provide unified algor ithm s in Sectio n 5, such a s proximal op erators , whic h are based on a sequence of submo dular function minimizations (SFMs), when such SFMs are efficien t, or by adapting the gene r ic slow er approach of [3] other w is e. − W e derive unified theoretical guarantees for lev el set r e co very in Sectio n 6, showing that even in the abse nce o f cor relation betw een predictor s , level set recovery is not alw ays guar an teed, a situation whic h is to b e co n trasted with tra ditional supp ort reco very situations [1, 3]. Notation. F or w ∈ R p and q ∈ [1 , ∞ ], w e denote b y k w k q the ℓ q -norm of w . Given a subset A of V = { 1 , . . . , p } , 1 A ∈ { 0 , 1 } p is the indica tor vector of the subse t A . Moreov er, given a vector w and a matrix Q , w A and Q AA denote the co rrespo nding subv ector and submatrix of w and Q . Fina lly , for w ∈ R p and A ⊂ V , w ( A ) = P k ∈ A w k = w ⊤ 1 A (this defines a mo dular set-function). In this pap er, for a certain vector w ∈ R p , we call level s ets the sets of indice s whic h are la rger (or smaller ) or equal to a certain constant α , which we denote { w > α } (or { w 6 α } ), while we call c onstant sets the sets o f indices which ar e equal to a consta nt α , which w e denote { w = α } . 2 Review of Submo du la r Analysis In this sec tion, we rev iew relev an t r esults from submo dular a na lysis. F or more details, see, e.g., [12], and, for a rev iew with pro ofs derived fro m clas sical conv ex a nalysis, see, e.g., [11]. Definition. Throughout this paper , we consider a s u bmo dular function F de fined on the power set 2 V of V = { 1 , . . . , p } , i.e., suc h that ∀ A, B ⊂ V , F ( A ) + F ( B ) > F ( A ∪ B ) + F ( A ∩ B ). Unless otherwise stated, we consider functions which are non-nega tiv e (i.e., suc h that F ( A ) > 0 for all A ⊂ V ), and that satisfy F ( ∅ ) = F ( V ) = 0. Usual examples ar e s ymmetric s ubm o dular functions, i.e., such that ∀ A ⊂ V , F ( V \ A ) = F ( A ), which are known to a lw a ys have no n-negativ e v alues. W e give several examples in Section 4; for illustr ating the concepts in tro duced in this section and Section 3, we will co nsider the cut in an undirected chain graph, i.e., F ( A ) = P p − 1 j =1 | (1 A ) j − (1 A ) j +1 | . Lo v´ asz extensio n. Given a n y set-function F suc h that F ( V ) = F ( ∅ ) = 0, o ne can define its L ov´ asz extension f : R p → R , as f ( w ) = R R F ( { w > α } ) dα (see, e.g., [11] for this particular form ulation). The Lov´ as z ex tens io n is conv ex if and only if F is submo dular. Moreov er, f is piecewise-linear and for all A ⊂ V , f (1 A ) = F ( A ), that is, it is indeed a n extension from 2 V (whic h can be iden tified to { 0 , 1 } p through indicator vectors) to R p . Finally , it is always p ositiv ely homogeneous. F or the c hain graph, w e obtain t he usual total v a riation f ( w ) = P p − 1 j =1 | w j − w j +1 | . Base p olyhedron. W e denote by B ( F ) = { s ∈ R p , ∀ A ⊂ V , s ( A ) 6 F ( A ) , s ( V ) = F ( V ) } the b ase p olyhe dr on [12], wher e w e use the notation s ( A ) = P k ∈ A s k . One imp o rtan t res ult in submo dular analysis is that if F is a submodula r function, then we have a repres en tatio n of f as a maximum of linear functions [12, 11], i.e., for a ll w ∈ R p , f ( w ) = max s ∈ B ( F ) w ⊤ s . Moreov er, instead o f solving a line a r progr am with 2 p contrain ts, a so lution s may b e o btained by the following “greedy algorithm”: or der the compo nen ts of w in decreasing order w j 1 > · · · > w j p , and then ta ke for all k ∈ { 1 , . . . , p } , s j k = F ( { j 1 , . . . , j k } ) − F ( { j 1 , . . . , j k − 1 } ) . 2 Tigh t and inseparable sets. The p olyhedra U = { w ∈ R p , f ( w ) 6 1 } and B ( F ) are p o lar to each other (see, e.g., [13] fo r definitions and pro p erties of polar sets). Therefore, the facial structure o f U may b e obtained f rom the one of B ( F ). Given s ∈ B ( F ), a set A ⊂ V is said tight if s ( A ) = F ( A ). It is known that the set of tigh t sets is a distributiv e lattice, i.e ., if A and B are tigh t, then s o are A ∪ B and A ∩ B [12, 11]. The faces of B ( F ) a re thus in tersections of hyperplane s { s ( A ) = F ( A ) } for A b elonging to certa in distr ibutive lattices (see P rop. 3 ). A set A is said sep ar able if ther e ex ists a non-trivial pa rtition of A = B ∪ C such that F ( A ) = F ( B ) + F ( C ). A set is said inseparable if it is not s eparable. F or the c ut in an undirected graph, inseparable sets are exactly connected sets. 3 Prop erties of the Lo v´ asz Extension In this section, w e derive prop erties of the Lo v´ asz extension for submo dular functions, which g o beyond con vexit y and homogeneity . Thr o ughout this section, w e assume that F is a no n-negativ e submo dular set-function that is equa l to zero at ∅ and V . This immedia tely implies that f is inv aria n t by addition of any constant vector (that is, f ( w + α 1 V ) = f ( w ) for all w ∈ R p and α ∈ R ), and that f (1 V ) = F ( V ) = 0. Thus, contrary to the non-decreasing ca se [3], our reg ularizers a r e not norms. How ever, they ar e norms on the h y perplane { w ⊤ 1 V = 0 } as so on as for A 6 = ∅ and A 6 = V , F ( A ) > 0 (which we a ssume for the rest of this pap er). W e now sho w that the Lov´ a sz extensio n is the c o n vex en velope of a certain co mbinatorial function which do es depend on all le vets sets { w > α } of w ∈ R p (see pro of in supplementary material): Prop osition 1 (Conv ex env elop e) The L ov´ asz extension f ( w ) is the c onvex envelop e of the func- tion w 7→ max α ∈ R F ( { w > α } ) on the set [0 , 1] p + R 1 V = { w ∈ R p , max k ∈ V w k − min k ∈ V w k 6 1 } . Note the difference with the result of [3 ]: w e consider her e a different set on whic h w e compute the conv ex envelope ([0 , 1] p + R 1 V instead of [ − 1 , 1] p ), and no t a function of the supp ort of w , but of al l its level sets. 1 Moreov er, the Lov´ asz extension is a conv ex rela xation of a function o f level sets (of the form { w > α } ) and no t of c onst a nt sets (of the form { w = α } ). It would hav e be en p erhaps more int uitive to co nsider for example R R F ( { w = α } ) dα , since it does not depend on the ordering o f the v alues that w may take; how ever, the la tter function do es no t lead to a conv ex function amenable to p olynomial-time a lgorithms. This definition through level sets will generate some p oten tially undesired behavior (suc h a s the well-kno wn staircas e effect for the o ne-dimensional total v a riation), as w e sho w in Sec tion 6. The next prop osition describ es the set of extreme p o in ts of the “unit ball” U = { w , f ( w ) 6 1 } , giving a first illustratio n of sparsity-inducing effects (see example in Figur e 1). Prop osition 2 (Extreme p oin ts) The ext reme p oints of the set U ∩ { w ⊤ 1 V = 0 } ar e the pr oje c- tions of the ve ctors 1 A /F ( A ) on the pla ne { w ⊤ 1 V = 0 } , fo r A such that A is insep ar able for F and V \ A is insep ar able for B 7→ F ( A ∪ B ) − F ( A ) . P artially ordered sets and distributive lattices. A subset D of 2 V is a (distributive) lattice if it is in v ar ian t by in tersection a nd union. W e a ssume in this paper that all lattices con tain the empt y set ∅ and the full set V , and w e endo w the lattice with the inclusion order. Such lattices may b e represen ted as a p artial ly or der e d set (p oset) Π( D ) = { A 1 , . . . , A m } (with order relations hip < ), wher e the s e ts A j , j = 1 , . . . , m , form a p artition of V (we a lw ays assume a top ological ordering of the sets , i.e., A i < A j ⇒ i > j ). As illustrated in Figure 2, w e go fro m D to Π( D ), by cons idering all maximal chains in D and the differe nces betw een consecutive sets. W e go fro m Π( D ) to D , by constructing a ll ide als of Π( D ), i.e., sets J suc h that if an element of Π( D ) is lower than an element 1 Note that the support { w = 0 } is a constan t set which is the intersect ion of t wo level sets. 3 w > w >w 1 2 1 w > w >w 3 2 3 2 w > w >w 1 1 3 w > w >w 2 2 w > w >w 1 3 2 1 w =w w =w 1 3 3 2 w =w 1 2 w > w >w 3 (0,1,1)/F({2,3}) (0,0,1)/F({3}) (1,0,1)/F({1,3}) (1,0,0)/F({1}) (1,1,0)/F({1,2}) (0,1,0)/F({2}) 3 (0,1,0)/2 (0,0,1) (0,1,1) (1,0,1)/2 (1,0,0) (1,1,0) Figure 1: T o p: Polyhedral level set o f f (pro jected on the set w ⊤ 1 V = 0 ), for 2 different s ubmo dular symmetric functions of three v aria bles, with differen t inseparable sets leading to different s e ts of extreme points; changing v alues of F may make some o f the extreme p oin ts disa ppear. The v ar ious extreme p oin ts cut the spac e int o p olygons where the ordering of the comp onent is fixed. Left: F ( A ) = 1 | A |∈{ 1 , 2 } (all p ossible extreme p o in ts); note that the polyg on need not be symmetric in general. Right: one- dimensional total v ar iation on three no des, i.e., F ( A ) = | 1 1 ∈ A − 1 2 ∈ A | + | 1 2 ∈ A − 1 3 ∈ A | , leading to f ( w ) = | w 1 − w 2 | + | w 2 − w 3 | , for which the extreme points corresp onding to the separable set { 1 , 3 } a nd its complement disa pp ear. {5,6} {2,3,4,5,6} {1,2,5,6} {2,5,6} {1,2} {2} {5,6} {1,2,3,4,5,6} {1} {2} {3,4} Figure 2: Left: distributive lattice with 7 elemen ts in 2 { 1 , 2 , 3 , 4 , 5 , 6 } , represented with the Ha sse diagram c orrespo nding to the inclusion o rder (for a partial order , a Hasse diagr a m co nnects A to B if A is smaller than B and there is no C such that A is smaller than C and C is smaller than B ). Righ t: corres p onding po set, with 4 elements that form a partition of { 1 , 2 , 3 , 4 , 5 , 6 } , represented with the Hasse diagram corresp onding to the order < (a no de points to its immediate sma lle r no de a ccording to < ). Note that this corresp onds to an “allow ed” la ttice (see Pr op. 3) for the o ne-dimensional total v aria t ion. of J , then it has to b e in J (see [12] for more details, and an example in Figur e 2). Distributive lattices a nd pos ets are thus in one - to-one co rrespo ndence. Throug hout this section, we go ba c k and forth betw een these tw o representations. The distributiv e lattice will cor respond to all authorized level s e ts { w > α } in a sing le face of U , while the element s of the p oset are the constant sets (o ver which w is consta n t), with the o rder b et ween the subsets g iving p artial constr ain ts betw een the v alues of the corresp onding constants. F aces of U . The faces of U a re characterized by la tt ices D , with their corresp onding p osets Π( D ) = { A 1 , . . . , A m } . W e denote by U ◦ D (and by U D its closure) the set o f w ∈ R p such that (a) w is piecewise co nstan t with resp ect to Π( D ), with v a lue v i on A i , and (b) for all pairs ( i, j ), A i < A j ⇒ v i > v j . F or certain lattices D , these will be exactly the relative interiors of all fa ces of U : Prop osition 3 (F aces of U ) The (non-empty) r elative i nteriors of al l fac es of U ar e exactly of t h e form U ◦ D , wher e D is a lattic e such that: (i) the r estriction of F to D is mo dular, i.e., for al l A, B ∈ D , F ( A ) + F ( B ) = F ( A ∪ B ) + F ( A ∩ B ) , (ii) fo r al l j ∈ { 1 , . . . , m } , the set A j is insep ar able for the fun ct i on C j 7→ F ( B j − 1 ∪ C j ) − F ( B j − 1 ) , wher e B j − 1 is the u nion of al l anc estors of A j in Π( D ) , (iii) among al l lattic es c orr esp onding to the same unordered p artition, D is a maximal element of the set of lattic es satisfying (i) and (ii). 4 5 10 15 20 −5 0 5 weights 5 10 15 20 −5 0 5 weights 5 10 15 20 −5 0 5 weights −2 0 2 4 6 0 0.1 0.2 0.3 0.4 log( σ 2 ) estimation error TV robust TV robust TV − 2 −2 0 2 4 6 0 0.1 0.2 0.3 0.4 log( σ 2 ) estimation error TV robust TV robust TV − 2 −2 0 2 4 6 0 0.1 0.2 0.3 0.4 log( σ 2 ) estimation error TV robust TV Figure 3: Three left plo ts : E s tim ation of noisy piecewise constant 1D signal with outliers (indices 5 and 15 in the chain of 20 no des). Left: original signal. Middle: b est estimation with t otal v a riation (level sets are not correctly es tim ated). Righ t: b est estimation with the r obust to ta l v a riation based on noisy cut functions (level sets are correctly estimated, with less bias a nd with detection of outliers). Ri g h t plot : clus tering estimation error v s . nois e level, in a s equence of 100 v ar ia bles, with a single jump, wher e noise of v a riance o ne is added, with 5% of outliers (av era ged ov er 20 replications). Among the three conditions, the second one is the easie st to in terpret, as it reduces to ha ving constant sets whic h are insepara ble for certain submo dular functions, and for cuts in an undir ected graph, these will exa ctly b e c onnected sets. Since w e are able to c haracter ize al l faces of U (of all dim ensions ) with non-empt y relative in terior , we have a partition of the space and a n y w ∈ R p which is no t propor tional to 1 V , will b e, up to the strictly po sitiv e cons ta n t f ( w ), in exa ctly one of these relative interiors of faces; we r efer to this lattice a s the lattic e asso ciate d to w . Note that from the face w belo ngs to, we have strong constraints on the co nstan t s ets, but w e may not be able to determine all lev el sets o f w , b ecause only partial constra ints are given by the order o n Π( D ). F or example, in Figure 2, w 2 may b e larger or smaller than w 5 = w 6 (and ev en potentially equal, but with zero probabilit y , see Section 6) . 4 Examples of Su bmo dular F unc tions In this sectio n, we provide exa mples of submodular functions and of their Lov´ asz extensions. Some are well-known (suc h as cut functions and total v ariatio ns), some ar e new in the co n text of super vised learning (regular functions), while some hav e interesting effects in ter ms of clustering or outlier detection (cardinality-based functions). Symmetrization. F rom any submo dular function G , one ma y define F ( A ) = G ( A ) + G ( V \ A ) − G ( ∅ ) − G ( V ), which is symmetric. Potentially interesting examples whic h are beyond the scope of this paper are m utual information, or functions of eigenv alues of submatrices [3]. Cut functions. Given a set of nonne gative weigh ts d : V × V → R + , define the cut F ( A ) = P k ∈ A,j ∈ V \ A d ( k , j ). The Lov´ a sz extensio n is e q ual to f ( w ) = P k,j ∈ V d ( k , j )( w k − w j ) + (whic h shows submodula rit y b ecause f is conv ex), a nd is often r eferred to as the total v a riation. If the weigh t function d is symmetric, then the submo dular function is a lso symmetric. In this case, it can be sho wn th at insepara ble se ts for functions A 7→ F ( A ∪ B ) − F ( B ) are exactly c onne cte d sets. Hence, cons ta n t sets are connected sets, which is the usua l justification be hind the total v a riation. Note ho wev er that some configuratio ns o f connected sets are not a llo wed due to the other conditions in Prop. 3 (see examples in Se c t ion 6). In Figure 5 (right plot), we give an exa mp le of the usual chain g raph, leading to the one-dimensional total v a riation [4, 5]. Note that these functions can be extended to cuts in h yp ergraphs, which may hav e interesting applications in computer visio n [6]. Moreov er, directed cuts ma y b e in ter esting to favor incr e asing or decrea sing jumps along the edges of the graph. 5 Regular functions and robust total v ariation. By partial minimization, we obtain so - called r e gular functions [6 , 5]. One application is “noisy cut functions” : for a given weight function d : W × W → R + , wher e each node in W is uniquely asso ciated in a no de in V , we co nsider the submo dular function o bt ained a s the minim um cut ada pted t o A in the augmen ted graph (see right plot of Figure 5): F ( A ) = min B ⊂ W P k ∈ B , j ∈ W \ B d ( k , j ) + λ | A ∆ B | . This allows for robust v ersio ns of cuts, where some gaps may be tolerated. See examples in Figure 3, illustrating the behavior of the t yp e of g raph display ed in the b ottom-right plot of Fig ure 5, wher e the p erformance of the robust total v a riation is significantly mor e stable in presence of outliers. Cardinalit y-based functions. F or F ( A ) = h ( | A | ) where h is such that h (0) = h ( p ) = 0 a nd h concav e, we obtain a submo dular function, a nd a Lov´ asz extensio n that dep ends on the order statistics of w , i.e., if w j 1 > · · · > w j p , then f ( w ) = P p − 1 k =1 h ( k )( w j k − w j k +1 ). While these examples do not provide significant ly different b eha viors for the no n-decreasing submo dular functions explor ed by [3] (i.e., in terms of supp ort ), they lead to in teresting behaviors here in ter ms of level sets , i.e., they will mak e the comp onen ts w cluster together in sp ecific wa ys. Indeed, as shown in Section 6, allow ed constant s e ts A are such that A is insepar able for the function C 7→ h ( | B ∪ C | ) − h ( | B | ) (where B ⊂ V is the s et of components with higher v alues than the ones in A ), whic h imposes that the concav e function h is not linear on [ | B | , | B | + | A | ]. W e consider the following examples: 1. F ( A ) = | A | · | V \ A | , leading to f ( w ) = P p i,j =1 | w i − w j | . This function can th us b e also seen as the cut in the fully connected graph. All patterns of lev el sets are allowed as the function h is strongly concave (see left plot o f Figur e 4 ). This function ha s b een extended in [1 4] by considering situations where each w j is a vector, instead of a scalar , and replacing the abso lute v alue | w i − w j | b y an y norm k w i − w j k , leading to co nvex formulations for clustering. 2. F ( A ) = 1 if A 6 = ∅ and A 6 = V , a nd 0 otherwis e, leading to f ( w ) = max i,j | w i − w j | . Tw o large level sets at the top and b ottom, all the rest of the v ariables are in-b et ween and separ ated (Figure 4, se cond plot from the left ). 3. F ( A ) = max {| A | , | V \ A |} . This function is piecewise affine, with only o ne kink, thus only one level se t of ca rdinalt y greater than one (in the middle) is p ossible, which is o bserv ed in Figure 4 (third plot fr om the left). This may hav e applications to multiv ariate outlier detection by considering extensions similar to [14]. 5 Optimization Algorithms In this section, we present optimization meth o ds for minimizing convex ob jective functions reg ular- ized by the Lov´ asz extension of a submo dular function. These lead to conv e x optimization pr oblems, which w e tac kle using proximal metho ds (see, e.g., [15]). W e first star t by mentioning that subgradi- ent s ma y easily b e derived (but subgradient descent is here ra ther inefficien t as shown in Figure 5). Moreov er, no te that with the squa re loss, the r egularization paths are piecewise affine, as a direct consequence of regularizing by a p olyhedral function. Subgradien t. F rom f ( w ) = max s ∈ B ( F ) s ⊤ w and the gree dy alg orithm 2 presented in Section 2, one can easily get in p olynomial time one subgradient a s one of the maximizers s . This a llo w s to use subgradient descent, with slow conv erg ence co mpared to proximal metho ds (see Figure 5). Pro ximal problems through sequences o f submo dular function mini mizations (SFMs ). Given regular ized problems of the form min w ∈ R p L ( w ) + λf ( w ), w he r e L is differen tiable with 2 The greedy algorithm to find extreme points of the base p olyhe dron should no t be confused with the greedy algorithm (e.g., forward selection) that is common in sup ervised learning/statistics. 6 0 0.01 0.02 0.03 −10 −5 0 5 10 weights λ 0 1 2 3 −10 −5 0 5 10 weights λ 0 0.2 0.4 −10 −5 0 5 10 weights λ 0 1 2 3 −10 −5 0 5 10 weights λ Figure 4: Left: Piece w is e linea r r egularization paths of proximal problems (Eq. (1)) for different functions of ca rdinalit y . F rom left to right: quadratic function (all lev el sets allow ed), second example in Section 4 (t wo large le vel sets at the top and bottom), piecewise linear w ith tw o pieces (a single large lev el set in the middle). Right: Same plot for the one-dimensional total v ariatio n. Note that in b oth ca ses the r egularization paths for orthogona l designs are agglomer ative (see Sec tion 5), while for general des igns, they would still b e piec e w is e affine but not a gglomerative. Lipschitz-con tinuous gradient, pr oximal metho ds have been shown to b e particularly efficient first- order metho ds (see, e.g., [15]). In this pap er, we use the metho d “IST A” and its accelerated v aria n t “FIST A” [15]. T o apply these methods, it suffices to b e able to solve efficiently: min w ∈ R p 1 2 k w − z k 2 2 + λf ( w ) , (1) which w e refer to as the pr oximal pr oblem . It is known that so lv ing the pr o ximal problem is r elated to submo dular function minimization (SFM). More precisely , the minimum of A 7→ λF ( A ) − z ( A ) ma y be obtained by selecting negativ e compo nen ts of the solution of a sing le proximal problem [12, 1 1 ]. Alternatively , the solution of the pr o ximal problem may be obtained by a sequence o f at mo st p submo dular function minimizations of the form A 7→ λF ( A ) − z ( A ), b y a decomp o sition algorithm adapted from [16], and describ ed in [11]. Thu s, computing the proximal op erator has polynomial co mplexit y since SFM has po lynomial com- plexity . Howev e r, it ma y b e to o slow for practica l purpo ses, as the b est generic a lg orithm has complexity O ( p 6 ) [17] 3 . Nevertheless, this strategy is efficient for families of submo dular functions for whic h dedicated f ast algo rithms exist: – Cuts : Minimizing the cut o r the par tially minimized cut, plus a mo dular function, ma y b e done with a min-cut/ma x-flo w a lgorithm (see, e.g., [6, 5]). F o r pr o ximal metho ds, w e need in fact to s olv e an instance of a p ar ametric max-flow problem, which may b e done using other efficient dedicated algorithms [19, 5 ] than the decompositio n algor it hm deriv ed from [16]. – F unctions of car dinali ty : minimizing functions o f the form A 7→ λF ( A ) − z ( A ) ca n b e done in closed for m by so rting the elemen ts of z . Pro ximal problems through minimum-norm-p oin t algorithm . In the generic case (i.e., beyond cuts and car dina lit y- ba sed functions), w e can follow [3]: since f ( w ) is e x pressed as a minimum of linear functions, the pro blem reduces to the pro jection on the p olytope B ( F ), for which we happ en to b e able to easily maximize linea r functions (using the greedy algor ithm des cribed in Section 2). This can b e tackled efficiently by the minim um-no rm-point algor ithm [12], whic h itera tes betw een orthogo nal pro jections on affine subspaces and the greedy algorithm for the submodula r f unction 4 . W e compare all optimization metho ds on sy n thetic examples in F igure 5. 3 Note that ev en in the case of symmetric submodular functions, where more efficien t algori thms in O ( p 3 ) for submodular function minimi za tion (SFM) exist [18], the minimi z ation of functions of the form λF ( A ) − z ( A ) is prov ably as hard as general SFM [18]. 4 In terestingly , when used for submo dular function minimization (SFM), the minim um-norm-p oin t algorithm has no complexity bound but is empiricall y faster than algorithms with such b ou nds [12]. 7 0 2 4 6 8 10 10 −15 10 −10 10 −5 10 0 time (seconds) f(w)−min(f) fista−generic ista−generic subgradient fista−card ista−card subgradient−sqrt V W Figure 5: Left : Matlab running times of different optimiza tio n metho ds on 20 replica tions of a lea st- squares reg ression problem with p = 100 0 for a c a rdinalit y-based submo dular function (b est s e en in color). P r o ximal methods with the gener ic a lgorithm (using the minimum-norm-po in t a lgorithm) are faster than subgradie nt descent (with tw o schedules for the learning rate, 1 /t or 1 / √ t ). Using the dedicated algo rithm (which is not av ailable in a ll situations) is significantly fas ter . Rig h t : Exa mples of graphs (top: chain graph, b ottom: hidden chain graph, with s ets W and V and e x amples of a set A in ligh t red, and B in blue, see text f or details). Pro ximal path as agg l omerativ e clustering. When λ v a ries from zer o to + ∞ , then the unique optimal solution o f Eq. (1) go es from z to a consta n t. W e now pr o vide conditions under which the reg ularization path of the proximal problem may b e obtained b y agglomera tiv e clustering (see examples in Figure 4): Prop osition 4 (Aggl omerativ e clustering) Assume that for all sets A, B such that B ∩ A = ∅ and A is insep ar able for D 7→ F ( B ∪ D ) − F ( B ) , we have : ∀ C ⊂ A, | C | | A | [ F ( B ∪ A ) − F ( B )] 6 F ( B ∪ C ) − F ( B ) . (2) Then the r e gu larization p ath for Eq. (1) is agglomer ativ e , that is, if two variab les ar e in the same c onstant fo r a c ertain µ ∈ R + , so ar e they for all lar ger λ > µ . As sho wn in the supplemen tary material, the assumptions required for by P rop. 4 are satisfied b y (a) all submodular set-functions that only dep end on the ca rdinalit y , and (b) b y the one-dimensional total v a riation—w e thus recov er and extend kno wn results f rom [7, 20, 14]. Adding an ℓ 1 -norm. F ollowing [4], we may add the ℓ 1 -norm k w k 1 for additiona l sparsity of w (on top of shaping its level sets). The following prop osition extends the r esult for the o ne-dimensional total v a riation [4, 21] to all s ubm o dular functions a nd their Lov´ asz extensions: Prop osition 5 (Prox imal probl em for ℓ 1 -p enalized problems) The u niq ue minimizer of 1 2 k w − z k 2 2 + f ( w ) + λ k w k 1 may b e obtaine d by soft-thr esholding the minimizers of 1 2 k w − z k 2 2 + f ( w ) . That is, the pr oximal op er ator for f + λ k · k 1 is e qual to t he c omp osition of the pr oximal op er ator for f and the one for λ k · k 1 . 6 Sparsit y-indu c i ng P r op erties Going from the penalization of suppor ts to the penaliza tion of level sets introduces some complexity and for simplicity in this section, we o nly co nsider the analysis in the context of o rthogonal design matrices, whic h is o ften referred to as the denoising problem, and in the cont ext of level set estimation already leads to in ter esting results. That is, we study the glo bal minim um of the proximal problem in Eq. (1) and make some assumption regar ding z (t ypically z = w ∗ + no ise ), and provide guarantees related to the recov er y o f the lev el sets of w ∗ . W e fir st s ta rt by characterizing the allow ed lev el sets, 8 showing that the partial constraints defined in Section 3 on faces of { f ( w ) 6 1 } do not create b y chance further groupings of v ar iables (see pro of in supplemen tary material). Prop osition 6 (Stable constant sets) Assu me z ∈ R p has an abso lutely c ontinuous density with r esp e ct t o the L eb esgue me asur e. Then, with pr ob ability one, the unique minimizer ˆ w of Eq. (1) has c onstant sets that define a p artition c orr esp onding to a lattic e D define d in Pr op. 3. W e now show that under certain conditions the recovered constant sets are the c orrect ones: Theorem 1 (Lev el set reco v ery) As s ume that z = w ∗ + σ ε , wher e ε ∈ R p is a s t and ar d Gaussian r andom ve ctor, and z ∗ is c onsistent with t h e lattic e D and its asso ciate d p oset Π( D ) = ( A 1 , . . . , A m ) , with values v ∗ j on A j , for j ∈ { 1 , . . . , m } . Denote B j = A 1 ∪ · · · ∪ A j for j ∈ { 1 , . . . , m } . Assume that ther e exists some c onstants η j > 0 and ν > 0 such that: ∀ C j ⊂ A j , F ( B j − 1 ∪ C j ) − F ( B j − 1 ) − | C j | | A j | [ F ( B j − 1 ∪ A j ) − F ( B j − 1 )] > η j min | C j | | A j | , 1 − | C j | | A j | , (3) ∀ i, j ∈ { 1 , . . . , m } , A i < A j ⇒ v ∗ i − v ∗ j > ν , (4) ∀ j ∈ { 1 , . . . , m } , λ F ( B j ) − F ( B j − 1 ) | A j | 6 ν / 4 . (5) Then t he unique minimizer ˆ w of Eq. ( 1 ) is asso ciate d to the same lattic e D than w ∗ , with pr ob ability gr e ater than 1 − P m j =1 exp − ν 2 | A j | 32 σ 2 − 2 P m j =1 | A j | exp − λ 2 η 2 j 2 σ 2 | A j | 2 . W e now discuss the three main assumptions of Theorem 1 as well as the probability estimate: – Eq. (3) is the equiv alent o f the supp ort recovery of the Lasso [1] or its extensions [3]. The main difference is that for suppo rt recov ery , this assumption is alw ays met for orthogona l desig ns, while here it is not alwa ys met. In terestingly , the v alidity of level set recov ery implies the agglomer ativit y of pro ximal paths (Eq. (2) in Prop. 4). Note that if Eq. (3) is sa tis fie d only with η j > 0 (it is then ex actly Eq. (2) in Prop. 4), then, even with infinitesimal no is e, one ca n show that in some cases, the wrong level sets may be obtained with non v anishing probability , while if η j is strictly negative, one can sho w that in so me cases, we never get the cor rect lev el sets. E q . (3) is thus essentially s ufficie nt and necessary . – Eq. (4) cor responds to ha ving distinct v a lues o f w ∗ far enough f rom each other. – Eq. (5) is a constraint on λ which con trols the bias of the estimator: if it is to o large, then there ma y be a merging of tw o clusters. – In the pro babilit y estimate, the second term is small if a ll σ 2 | A j | − 1 are small enoug h (i.e., given the noise , there is enough data to correctly es tim ate the v alues of the constant sets) and the third term is small if λ is large enough, to avoid that clusters split. One-dime ns ional total v ariation. In t his situation, w e alwa ys get η j = 0 , but in some cases, it cannot be improved (i.e., the best p ossible η j is equal to zero), and as shown in the supplementary material, this occur s a s so on as there is a “stairca se”, i.e., a piecewise constant vector, with a sequence of at least tw o consecutive increases , o r tw o co nsecutiv e decr eases, showing that in the presence of such sta ircases, one cannot have consistent suppo rt recov ery , which is a well-known is s ue in signal pro cessing (typically , more steps are cre a ted). If there is no stairca se effect, we hav e η j = 1 and E q . (5) b ecomes λ 6 ν 8 min j | A j | . If w e take λ equal to the limiting v a lue in E q. (5), then we obtain a pro babilit y less than 1 − 4 p exp( − ν 2 min j | A j | 2 128 σ 2 max j | A j | 2 ). Note that we could also derive general results when an additiona l ℓ 1 -p enalt y is used, th us extending results from [22]. 9 Tw o -dimensional total v ariation. In this situation, even with only tw o different v alues for z ∗ , then we may ha ve η j < 0, leading to additional problems, which has alrea dy b een noticed in contin uous settings (see, e.g., [2 3 ] and the s upplemen tar y materia l). Clustering with F ( A ) = | A | · | V \ A | . In this case, we ha ve η j = | A j | / 2, and Eq. (5) b ecomes λ 6 ν 4 p , leading to the probability of correct supp ort estimatio n greater than 1 − 4 p exp − ν 2 128 pσ 2 . This indicates that the no ise v a riance σ 2 should b e small compared to 1 / p , which is not satisfactor y and w o uld b e corrected with the weigh ting schemes propose d in [14]. 7 Conclusion W e hav e presented a family o f sparsity-inducing norms dedicated to inco rpora tin g pr ior knowledge or structural constra in ts on the level sets of linear predictors. W e ha ve pr ovided a set of common a lgo- rithms and theoretical results, as well a s simulations on synthetic examples illustrating the behavior of these norms. Sev eral a ven ues a re worth in vestigating: first, w e could follo w current pra ctice in sparse metho ds, e.g., b y considering related adapted co nca ve p enalties to enhance sparsit y-inducing capabilities, or by extending some of the concepts for no rms of matrices, with p oten tial applica tions in matrix factorization [24] or m ulti-task learning [25]. Ac kno wledgemen t s This paper w as partially supp orted by the Agence Na tionale de la Recherche (MGA Pr o ject), the Europ ean Resea rc h Council (SIERRA Pro ject) and Digiteo (BIOV IZ pro ject). 10 A Pro of of Prop osition 1 Pro of F o r any w ∈ R p , lev el sets of w a re characterized b y an or dered partition ( A 1 , . . . , A m ) s o that w is constant o n eac h A j , with v a lue t j , j = 1 , . . . , m , and so that ( t j ) is a strictly decreasing sequence. W e can now decomp ose minimization with resp ect to w using these order ed par titions and ( t j ). In order to co mput e the conv ex env elop e, we simply need to co mput e t wice the F enchel conjugate of the function we wan t to find the en velop e of (see, e.g., [26, 2 7 ] for definitions and prop erties o f F enchel conjugates). Let s ∈ R p ; we consider the function g : w 7→ max α ∈ R F ( { w > α } ), and we compute its F enc hel conjugate: g ∗ ( s ) def = max w ∈ [0 , 1] p + R 1 V w ⊤ s − g ( w ) , = max ( A 1 ,...,A m ) partition max t 1 > ··· >t m , t 1 − t m 6 1 m X j =1 t j s ( A j ) − max j ∈{ 1 ,...,m } F ( A 1 ∪ · · · ∪ A j ) , = max ( A 1 ,...,A m ) partition max t 1 > ··· >t m , t 1 − t m 6 1 m − 1 X j =1 ( t j − t j +1 ) s ( A 1 ∪ · · · ∪ A j ) + t m s ( V ) − max j ∈{ 1 ,...,m } F ( A 1 ∪ · · · ∪ A j ) by integration by pa rts, = ι s ( V )=0 ( s ) + max ( A 1 ,...,A m ) partition max j ∈{ 1 ,...,m − 1 } s ( A 1 ∪ · · · ∪ A j ) − max j ∈{ 1 ,...,m } F ( A 1 ∪ · · · ∪ A j ) , = ι s ( V )=0 ( s ) + max ( A 1 ,...,A m ) partition max j ∈{ 1 ,...,m − 1 } s ( A 1 ∪ · · · ∪ A j ) − max j ∈{ 1 ,...,m − 1 } F ( A 1 ∪ · · · ∪ A j ) , where ι s ( V )=0 is the indicator function of the set { s ( V ) = 0 } (with v alues 0 or + ∞ ). Note that max j ∈{ 1 ,...,m } F ( A 1 ∪ · · · ∪ A j ) = max j ∈{ 1 ,...,m − 1 } F ( A 1 ∪ · · · ∪ A j ) because F ( V ) = 0. Let h ( s ) = ι s ( V )=0 ( s ) + max A ⊂ V { s ( A ) − F ( A ) } . W e clearly hav e g ∗ ( s ) > h ( s ), b ecause we take a maximum o ver a lar g er se t (consider m = 2). Moreover, for all par titions ( A 1 , . . . , A m ), if s ( V ) = 0, ma x j ∈{ 1 ,...,m − 1 } s ( A 1 ∪ · · · ∪ A j ) 6 max j ∈{ 1 ,...,m − 1 } ( h ( s ) + F ( A 1 ∪ · · · ∪ A j )) = h ( s ) + max j ∈{ 1 ,...,m − 1 } F ( A 1 ∪ · · · ∪ A j ), whic h implies tha t g ∗ ( s ) 6 h ( s ). Thus g ∗ ( s ) = h ( s ). Moreov er, we ha ve, since f is in v ar ian t b y adding constan ts and f is submodular, max w ∈ [0 , 1] p + R 1 V w ⊤ s − f ( w ) = ι s ( V )=0 ( s ) + max w ∈ [0 , 1] p { w ⊤ s − f ( w ) } = ι s ( V )=0 ( s ) + max A ⊂ V { s ( A ) − F ( A ) } = h ( s ) , where w e ha ve used the fact that minimizing a submo dular function is equiv alent to minimizing its Lov´ asz extension on the unit hypercub e. Thus f and g have the same F enchel conjugates. The result follows from the convexit y of f , using the fa c t the conv ex env elo pe is the F enchel bi-c onjugate [26, 27]. 11 B Pro of of Prop osition 2 Pro of Extreme points of U co rrespo nd to full-dimensional faces of B ( F ). F r om Coro llary 3.4.4 in [12], these facets are exactly the ones that corres pond to sets A with the g iv e n conditions. These facets are defined as the in tersection of { s ( A ) = F ( A ) } and { s ( V ) = F ( V ) } , which leads to the desired result. Note that this is also a consequence of Pro p. 3 . Note that when F is symmetric, the second condition is equiv alent to V \ A being insepara ble for F . C Pro of of Prop osition 3 Pro of Given that the polyhedra U and B ( F ) are p olar to eac h other [13], the prop osition follows from Theo rem 3.43 in [1 2 ], where ea c h o f our three assumptions are equiv a len t to a cor responding one in The o rem 3.4 3 from [12]. D Pro of of Prop osition 4 W e fir s t start by a lemma, whic h follows common pra ctice in spars e recovery (as sume a certa in sparsity pattern and c heck when it is actually optimal): Lemma 1 (Optimalit y of l at tice for pro ximal problem) The s olut io n of the pr oximal pr ob- lem i n Eq. (1 ) c orr esp onds to a lattic e D if and only if v = ( M ⊤ M ) − 1 ( M ⊤ z − λt ) satisfies the or der r elationships imp ose d by D and 1 λ ( I − M ( M ⊤ M ) − 1 M ⊤ ) z + M ( M ⊤ M ) − 1 t ∈ B ( F ) , wher e M ∈ R p × m is the indic ator matrix o f the p artition Π( D ) , and t i = F ( A 1 ∪ · · · ∪ A i ) − F ( A 1 ∪ · · · ∪ A i − 1 ) , i = 1 , . . . , m . Pro of An y w ∈ R p belo ngs to a single face relative in ter ior from Pr op. 3, defined b y a lattice D , i.e., w is constant on A i with v alue v i (whic h implies that w = M v ) a nd such that v i > v j as soo n as A i < A j . W e ass ume a topologic al order ing of the sets A i , i.e, A i < A j ⇒ i > j . Since the Lov´ asz extension is linear for w in U D (and equa l to t ⊤ v for w = M v ), the o ptim um o ver w can be found by minimizing with respect to v 1 2 k z − M v k 2 2 + λt ⊤ v . W e th us get, b y setting the gradient to zero: v = ( M ⊤ M ) − 1 ( M ⊤ z − λt ) . Optimality co nditions for w for Eq. (1) are that w − z + λs = 0, for s ∈ B ( F ) and f ( w ) = w ⊤ s (these are obtained from genera l optimality c o nditions for functions defined as p o in twise maxima [27]). Thu s our candidate w = M v is o ptima l if and only if M v − z + λs = w − z + λs = 0 for (a) s ∈ B ( F ) and (b) f ( w ) = w ⊤ s . F r om Prop. 10 in [1 1 ], for (b) to be v alid, s ∈ B ( F ) simply has to sa tisfy s ( A 1 ∪ · · · ∪ A i ) = F ( A 1 ∪ · · · ∪ A i ) for a ll i . 12 Note that z − M v = ( I − M ( M ⊤ M ) − 1 M ⊤ ) z + λM ( M ⊤ M ) − 1 t, and that for all i ∈ { 1 , . . . , m } , 1 ⊤ A i ( I − M ( M ⊤ M ) − 1 M ⊤ ) z = δ ⊤ i M ⊤ ( I − M ( M ⊤ M ) − 1 M ⊤ ) z = 0 , where δ i is indicator v ector of the singleton { i } . Mor e o ver, we have 1 ⊤ A i M ( M ⊤ M ) − 1 t = t i = F ( A 1 ∪ · · · ∪ A i ) − F ( A 1 ∪ · · · ∪ A i − 1 ) , so that, if B i = A 1 ∪ · · · ∪ A i , [( I − M ( M ⊤ M ) − 1 M ⊤ ) z ]( B i ) = 0, [ M ( M ⊤ M ) − 1 t ]( B i ) = F ( B i ), for all i ∈ { 1 , . . . , m } . This implies that 1 λ ( z − M v ) ( A i ) = t i , and thus 1 λ ( z − M v ) ( B i ) = F ( B i ). Thu s, if (a) is satisfied, then (b) is alwa ys s a tisfied. Thus to c he ck if a cer tain lattice leads to the optimal solution, we simply hav e to chec k that 1 λ ( I − M ( M ⊤ M ) − 1 M ⊤ ) z + M ( M ⊤ M ) − 1 t ∈ B ( F ). W e now turn to the pro of of Propo sition 4. Pro of W e show that when λ increa ses, we mov e to a lattice which has to b e mer ging some co nstan t sets. Let us assume that a lattice D is optimal for a cer tain µ . Then, from Lemma 1, we ha ve 1 µ ( I − M ( M ⊤ M ) − 1 M ⊤ ) z + M ( M ⊤ M ) − 1 t ∈ B ( F ) . Moreov er, since from P rop. 3, A i is separa ble for C i 7→ F ( B i − 1 ∪ C i ) − F ( B i − 1 ), from the assumption of the propos itio n, w e obtain: ∀ C i ⊂ A i , [ M ( M ⊤ M ) − 1 t ]( C i ) = | C i | | A i | ( F ( B i − 1 ∪ A i ) − F ( B i − 1 )) 6 F ( B i − 1 ∪ C i ) − F ( B i − 1 ) , which implies, for all C ⊂ V : [ M ( M ⊤ M ) − 1 t ]( C ) = m X j =1 [ M ( M ⊤ M ) − 1 t ]( C ∩ A i ) b y modula rit y , 6 m X i =1 F ( B i − 1 ∪ ( C ∩ A i )) − F ( B i − 1 ) from above, 6 m X i =1 F (( B i − 1 ∩ C ) ∪ ( C ∩ A i )) − F ( B i − 1 ∩ C ) by submo dularity , = m X i =1 F ( B i ∩ C ) − F ( B i − 1 ∩ C ) = F ( C ) . Thu s, for an y set C , w e ha ve for λ > µ (which implies µ λ ∈ [0 , 1]), 1 λ ( I − M ( M ⊤ M ) − 1 M ⊤ ) z + M ( M ⊤ M ) − 1 t ( C ) = µ λ 1 µ ( I − M ( M ⊤ M ) − 1 M ⊤ ) z + M ( M ⊤ M ) − 1 t ( C ) + (1 − µ λ ) M ( M ⊤ M ) − 1 t ( C ) 6 µ λ F ( C ) + (1 − µ λ ) F ( C ) = F ( C ) . 13 Thu s the second co ndition in Lemma 1 is satisfied, th us it has to b e t he first one whic h is v iolated, leading to mer ging tw o constant sets. W e now show that for special cases, the co ndition in Eq. (2) is satisfied, and w e also s ho w when the condition in Eq. (3) of Theorem 1 is satisfied or not: • Cardinalit y-based functions : the condition in Eq. (2) is equiv alent to h ( | B | + | A | ) − h ( | B | ) | A | 6 h ( | B | + | C | ) − h ( | B | ) | C | , which is a co nsequence of the conca vity o f h . Moreov er the condition in Eq. (3) is equiv alent to h ( | B | + | C | ) − h ( | B | ) − | C | | A | [ h ( | B | + | A | ) − h ( | B | )] > η min n | C | | A | , 1 − | C | | A | o . F or h ( t ) = t ( p − t ), this is equiv a le n t to | A | ( | C | − | A | ) > η min n | C | | A | , 1 − | C | | A | o , which is true as so on as η 6 | A | / 2. • One-dimens ional total v ariation : we assume that w e have a chain gr aph. Note that A m ust b e an in terv al and that B only enters the problem if one of its elements is a ne ig h b or of one of the tw o extreme elemen ts of A . W e th us hav e eigh t cases, depending on the three po ssibilities for these t wo neig h b ors of A (in B , in V \ B , or no neighbor, i.e., end of the chain). W e consider all 8 ca ses, where C is a no n trivial subset of A , and compute a lower b ound on F ( B ∪ C ) − F ( B ) − | C | | A | [ F ( B ∪ A ) − F ( B )]. – left: B , right: B . F ( B ) = 2, F ( B ∪ A ) = 0, F ( C ∪ B ) > 2. Bound= 2 | C | | A | – left: B , right: V \ B . F ( B ) = 1, F ( B ∪ A ) = 1 , F ( C ∪ B ) > 1. Bound= 0 – left: B , right: none. F ( B ) = 1, F ( B ∪ A ) = 0, F ( C ∪ B ) > 1. Bound= | C | | A | – left: V \ B , right: B . F ( B ) = 1, F ( B ∪ A ) = 1 , F ( C ∪ B ) > 1. Bound= 0 – left: V \ B , right: V \ B . F ( B ) = 0 , F ( B ∪ A ) = 2, F ( C ∪ B ) > 2. Bound= 2 − 2 | C | | A | – left: V \ B , right: none. F ( B ) = 0 , F ( B ∪ A ) = 1, F ( C ∪ B ) > 1. Bound= 1 − | C | | A | – left: no ne, right: B . F ( B ) = 2, F ( B ∪ A ) = 0 , F ( C ∪ B ) > 2. Bound= | C | | A | – left: no ne, right: V \ B . F ( B ) = 1 , F ( B ∪ A ) = 0, F ( C ∪ B ) > 1. Bound= | C | | A | – left: no ne, right: none. F ( B ) = 0 , F ( B ∪ A ) = 0, F ( C ∪ B ) > 1. Bo und= 1. Considering all cases, w e get a low er bo und of zero , which shows that the paths are agg lomera- tive. How ever, there are tw o ca ses where no strictly p o sitiv e low er b ounds are p ossible, namely when the tw o extr emities o f A have resp ectiv e neighbors in B a nd V \ B . Given that B is a set of higher v alues for the parameters and V \ ( A ∪ B ) is a set of low er v alues , this is exactly a staircase . When th ere is no suc h stair case, we get a low er b o und of min { | A | / | C | , 1 − | A | / | C |} , hence η = 1. 14 E Pro of of Prop osition 5 Pro of W e denote by w the unique mininizer of 1 2 k w − z k 2 2 + f ( w ) and s the asso ciated dual v ector in B ( F ). The optimality conditions are w − z + s = 0, and f ( w ) = w ⊤ s (ag ain fr om optimalit y conditions for point wise maxima). W e assume that w takes distinct v alues v 1 , . . . , v m on the sets A 1 , . . . , A m . W e define t as t k = sign( w k )( | w k | − λ ) + (whic h is the unique minimizer of 1 2 k w − t k 2 2 + λ k t k 1 ). The cons tan t sets of t a r e A j , f or j such that | v j | > λ a nd zero for the union of all A j ’s suc h that | v j | 6 λ . Since t is obtained by soft-thresho lding w , which corres ponds to ℓ 1 -proximal problem, we hav e that t − w + λq = 0 with k q k ∞ 6 1 and q ⊤ t = k t k 1 . By combining these t wo equa lities, with have t − z + s + λq = 0 with k q k ∞ 6 1, q ⊤ t = k t k 1 and s ∈ B ( F ). The only remaining elemen t to sho w that t is optimal for the full problem is that f ( t ) = s ⊤ t . This is true since the level sets of w are finer than the o nes of t (i.e., it is obtained b y grouping some v alues of w ), with no c ha nge of ordering [11]. F Pro of of Prop osition 6 Pro of F rom Lemma 1, the solution has to co rrespo nd to a lattice D a nd w e only ha ve to show that with probability o ne, the vector v = ( M ⊤ M ) − 1 ( M ⊤ z − λt ) has distinct components, whic h is straightforward b ecause it has an absolutely con tinuous density with resp ect to the Lebesgue mea- sure. G Pro of of Theorem 1 Pro of F rom Lemma 1, in order to c o rrespo nd to the sa me la ttice D , w e simply need that (a) v = ( M ⊤ M ) − 1 ( M ⊤ z − λt ) satisfies the o rder relatio ns hips impos e d by D and that ( b) 1 λ ( I − M ( M ⊤ M ) − 1 M ⊤ ) z + M ( M ⊤ M ) − 1 t ∈ B ( F ) . Condition (a) is sa tisfied as so on as k w − w ∗ k ∞ 6 ν , which is implied b y σ k ( M ⊤ M ) − 1 M ⊤ ε k ∞ 6 ν / 4 and k λ ( M ⊤ M ) − 1 t k ∞ 6 ν / 4 . (6) The second condition in Eq . (6) is met b y assumption, while the first one leads to the sufficien t conditions ∀ j, | ε ( A j ) | 6 ν | A j | / 4 σ , le a ding b y the union b ound to the probabilities P m j =1 exp − ν 2 | A j | 32 σ 2 . F ollowing the same reasoning than in the pro of of P r op. 4, condition (b) is satis fie d as so on as for all j ∈ { 1 , . . . , m } , and all C j ⊂ A j , σ 1 λ ( I − M ( M ⊤ M ) − 1 M ⊤ ) ε ( C j ) 6 η j min | C j | | A j | , 1 − | C j | | A j | . 15 Indeed, this implies tha t for all j , 1 λ ( I − M ( M ⊤ M ) − 1 M ⊤ ) z + M ( M ⊤ M ) − 1 t ( C j ) = σ λ ( I − M ( M ⊤ M ) − 1 M ⊤ ) ε + M ( M ⊤ M ) − 1 t ( C j ) 6 η j min | C j | | A j | , 1 − | C j | | A j | + | C j | | A j | ( F ( B j − 1 ∪ A i ) − F ( B j − 1 )) 6 F ( B j − 1 ∪ C j ) − F ( B j − 1 ) , which leads to 1 λ ( I − M ( M ⊤ M ) − 1 M ⊤ ) z + M ( M ⊤ M ) − 1 t ∈ B ( F ) using the sequence o f inequalities used in the pro of of P r op. 4. F rom Lemma 2 b elow, we thus get the probability 2 P m j =1 | A j | exp − λ 2 η 2 j 2 σ 2 | A j | 2 . Lemma 2 F or F ( A ) = min | A | p , 1 − | A | p , and s normal with me an zer o and varianc e I − 1 V 1 ⊤ V p , we have: P max A ⊂ V ,A 6 = ∅ ,A 6 = V s ( A ) F ( A ) > t 6 2 p exp − t 2 2 p 2 . Pro of Since F dep ends on uniquely on the cardinality | A | and is symmetric w e ha ve, with ˜ s ∈ R p the sorted (in desce nding order ) comp onen ts of s , and h ( a ) = min { a/p, 1 − a/p } : P max A ⊂ V ,A 6 = ∅ ,A 6 = V s ( A ) F ( A ) > t = P max k ∈{ 1 ,...,p − 1 } ˜ s ( { 1 , . . . , k } ) h ( k ) > t 6 P max k ∈{ 1 ,..., ⌊ p/ 2 ⌋− 1 } ˜ s ( { 1 , . . . , k } ) h ( k ) > t + P max k ∈{⌊ p/ 2 ⌋ ,...,p − 1 } ˜ s ( { 1 , . . . , k } ) h ( k ) > t 6 2 P max k ∈{ 1 ,..., ⌊ p/ 2 ⌋− 1 } ˜ s ( { 1 , . . . , k } ) k /p > t bec ause of symmetry due to the cov ariance of s 6 2 P max k ∈{ 1 ,..., ⌊ p/ 2 ⌋− 1 } ˜ s ( { 1 , . . . , k } ) k /p > t 6 2 P max k ∈{ 1 ,...,p } s k > t/ p 6 2 p exp( − t 2 / 2 p 2 ) . W e now consider the three special cases: • One-dimens ional total v ariation : without the sta ircase effect, as shown in App endix D, we ha ve η j = 1 . Mo reo ver, | F ( B j ) − F ( B j − 1 ) | 6 2, a nd thus Eq. (5) leads to λ 6 ν 8 min j | A j | . 16 Figure 6: Signal a ppro ximation with the t wo-dimensional total v aria tion: F or tw o piecewise constant images with tw o v alues, the e s tim ation ma y (left case ) or may not (righ t c a se) recov er the correct level sets, even with infinitesimal noise. F o r the tw o cases , left: origina l pattern, right: b est po ssible recov ered level sets. Using the la rgest p ossible λ in Eq. (5), w e obtain a probabilit y greater tha n 1 − m X j =1 exp − ν 2 | A j | 32 σ 2 − 2 m X j =1 | A j | exp − λ 2 η 2 j 2 σ 2 | A j | 2 > 1 − m X j =1 exp − ν 2 | A j | 32 σ 2 − 2 m X j =1 | A j | exp − ν 2 min j | A j | 2 128 σ 2 max j | A j | 2 > 1 − m X j =1 exp − ν 2 | A j | 32 σ 2 − 2 p exp − ν 2 min j | A j | 2 128 σ 2 max j | A j | 2 > 1 − 4 p exp − ν 2 min j | A j | 2 128 σ 2 max j | A j | 2 , bec ause the second term is a lways greater than th e third one. • Tw o -dimensional total v ariation : we simply build the f ollowing coun ter-example: where B ar e the bla ck no des, C the gray no des and A the complement of B . W e indeed hav e A connected, and F ( B ∪ C ) − F ( B ) = 4 − 5 = − 1 , F ( B ∪ A ) − F ( B ) = − 5, leading to F ( B ∪ C ) − F ( B ) − | C | | A | [ F ( B ∪ A ) − F ( B )] = − 1 + 5 × 2 13 = − 3 13 . W e also illustrate this in Figure 6, where we show that dep ending on the shap e o f the level sets (which still ha ve to b e connected), we may no t recover the cor rect pattern, even with very small noise. References [1] P . Zhao and B. Y u. On mo del selection co nsistency of Lass o. J o urnal of Machine L e arning R ese ar ch , 7:254 1–2563, 2006. 17 [2] S. Negahban, P . Ravikumar, M. J. W ainwright, and B. Y u. A unified framework for hig h- dimensional analysis of M-e s tim ator s with decompos a ble regulariz e rs. In A dv. NIPS , 20 09. [3] F. Bach. Structured sparsity-inducing norms through submo dular functions. In A dv. NIPS , 2010. [4] R. Tibshirani, M. Saunders, S. Rosset, J. Zhu, a nd K. Knight. Spar s it y and smo othness via the fused Lasso. J. R oy. Stat. So c. B , 67 (1):91–108, 2005 . [5] A. Chambolle and J . Darb o n. On total v ar iation minimization a nd surface evolution using parametric maxim um flo ws. International J ournal of Computer V ision , 84(3):28 8–307, 2009 . [6] Y. B oyko v, O. V eks ler, a nd R. Zabih. F ast approximate energy minimization via g raph cuts. IEEE T r ans. P AMI , 23(11):1 2 22–1239, 2001. [7] Z. Harc haoui and C. L´ evy- Leduc. Catching c hang e-points with Lasso. A dv. NIPS , 20, 2008. [8] J.-P . V er t and K. Bleakley . F ast detection of mult iple change-p oin ts shared by man y signals using group LARS. A dv. NIPS , 23, 2010. [9] M. Kolar , L. Song, and E. Xing. Sparsistent le a rning of v a rying-co efficien t mo dels with struc- tural c hanges. A dv. NIPS , 22, 2009. [10] H. D. Bondell and B. J. Reich. Simultaneous reg ression shrink ag e, v a riable selection, and sup e rvised cluster ing of predictors with oscar. Biometrics , 64(1):115–12 3, 2008 . [11] F. Bac h. Conv ex analysis a nd optimization with submo dular functions : a tutorial. T echnical Repo rt 005 27714, HAL, 2010. [12] S. F ujishige. Su bmo dular F unctions and Optimization . Els e v ier, 2005 . [13] R. T. Ro ck afella r . Convex A nalysis . Pr inceton Universit y Press, 1997. [14] T. Hocking, A. Joulin, F. Bach , and J .-P . V er t. Clusterpath: an algorithm for clus tering using conv ex fusion p e na lties. In Pr o c. ICML , 20 11. [15] A. Bec k and M. T eb oulle. A fast iterative shrink a ge-thresholding algo rithm for linear in verse problems. SIAM J o urnal on Imaging Scienc es , 2(1):18 3–202, 2009. [16] H. Gro enevelt. Two algor ithms for maximizing a sepa rable co nca ve function ov er a p olymatroid feasible region. Eur op e an Journal of Op er ational Rese ar ch , 54(2):227–2 36, 1 991. [17] J. B. O rlin. A faster stro ngly p olynomial time algorithm for submo dular function minimization. Mathematic al Pr o gr amming , 118(2 ):237–251, 2009. [18] M. Queyranne. Minimizing symmetric submo dular functions. Mathematic al Pr o gr amming , 82(1):3–1 2, 1998. [19] G. Gallo, M. D. Grigoria dis, and R. E. T arjan. A fast parametric maximum flow alg orithm and applications. SIA M Journal on Computing , 18(1):30– 5 5, 19 89. [20] H. Ho efling. A path algo rithm for the fused Lasso s ignal approximator. T echnical Rep ort 0910.0 526v1, a rXiv, 20 09. [21] J. Mairal, F. Bach, J. P once, and G. Sapiro. Online learning for matrix factorizatio n and s parse co ding. Journal of Machine L e arning R ese ar ch , 11:19–60 , 201 0. [22] A. Rinaldo. Prop erties a nd re finements of the fused Lasso. Ann. Stat. , 37(5):2922–2 952, 200 9. 18 [23] V. Duv al, J.-F. Aujol, and Y. Gousseau. The TVL1 mo del: A geometric p oin t of view. Multisc ale Mo deling and Simulation , 8(1):154–18 9, 2009 . [24] N. Sre bro, J. D. M. Rennie, and T. S. Jaa kk ola. Ma xim um-ma rgin matrix factorizatio n. In A dv. N IPS 17 , 200 5. [25] A. Arg yriou, T. E vgeniou, and M. Pon til. Convex multi-task feature learning. Machine L e arn- ing , 73(3):243–2 72, 200 8. [26] S. P . Bo yd and L. V a ndenber ghe. Convex Optimization . Ca m bridg e Univ ersity Pr ess, 20 04. [27] J. M. Borwein a nd A. S. Lewis . Convex Analysis and Nonline ar Optimization: The ory and Examples . Springer, 2006 . 19 (0,1,1)/F({2,3}) w > w >w 2 1 w =w 2 3 3 1 w =w w =w 1 2 3 1 w > w >w 2 2 w > w >w 3 1 1 w > w >w 2 3 2 3 w > w >w 1 2 1 w > w >w 3 (0,1,0)/F({2}) (1,1,0)/F({1,2}) (1,0,0)/F({1}) (1,0,1)/F({1,3}) (0,0,1)/F({3}) 3
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment