Fountain Communication using Concatenated Codes
This paper extends linear-complexity concatenated coding schemes to fountain communication over the discrete-time memoryless channel. Achievable fountain error exponents for one-level and multi-level concatenated fountain codes are derived. It is als…
Authors: Zheng Wang, Jie Luo
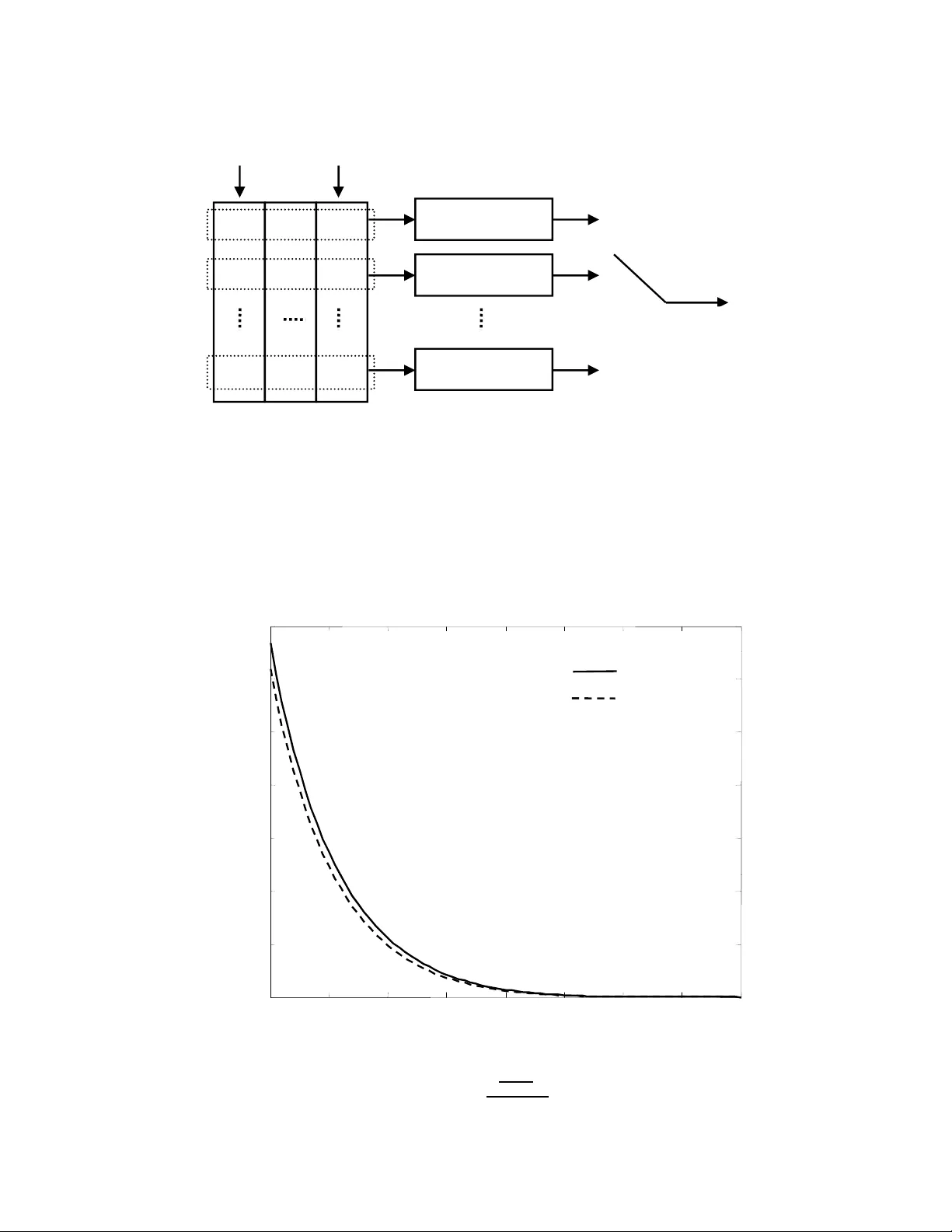
1 F ountain Communication using Concate nated Codes Zheng W ang, Student Member , IEEE , Jie Luo, Member , IEEE Abstract This paper extends linear-complexity concatenate d co ding schemes to founta in co mmunicatio n over the discrete- time memory less channel. Achiev able fo untain err or exponen ts for on e-level an d multi-level c oncatenated fountain codes are derived. It is also shown that concatenated codin g scheme s po ssess inter esting pro perties in se veral multi-user fountain co mmun ication scenarios. I . I N T RO D U C T I O N Fountain communication [2] is a new c ommuni cation model proposed for reliable data transmiss ion over channels with arbitrary erasures. In a p oint-to-point fountain comm unication system , the transmitt er maps a message into an infinite sequence of channel symbol s, which experience arb itrary erasures during transmissio n. The recei ver decodes the m essage after the number of received symbols exce eds certain threshold. W ith the help of random ized codi ng, foun tain com munication achieve s the s ame rate and error performance over diff erent channel erasure realizations corresponding to an identical num ber of receiv ed symbols. Under the assump tion that the erasure stat istics is unknown at the t ransmitter , communicati on duration in a fountain syst em i s determ ined b y the recei ver , rather than b y t he transmitter . The first realization o f fountain codes w as L T codes introduced b y Luby [3] for erasure channels. L T codes can recov er k information bits from k + O √ k ln 2 ( k /δ ) encoded symbols with probability 1 − δ and a com plexity of O ( k ln( k /δ )) , for any δ > 0 [3]. Shokroll ahi propo sed Raptor codes in [4] by combining appropriate L T codes with a pre-code. Raptor codes can recover k information bits from k (1 + ǫ ) encoded symbols at high probability with comple xity O ( k log(1 /ǫ )) . L T codes and Raptor codes can achie ve optimum rate with c lose to linear and linear comple xity , respecti vely . Ho wever , under a fixed rate, error probabilities of t he two coding schemes do not decrease exponentially i n the number of receiv ed symbols. The authors are with the E lectrical and Computer Engineering Department, Colorado State University , Fort Colli ns, CO 80523. E-mail: { zhwan g, r ocke y } @engr .colostate.edu. This work was supported by the National Science Foundation under Gr ant CCF -0728826 . Part of the material in this paper were presented at the IEEE International Symposium on I nformation Theory , Seoul, Korea, June 2009 [1]. 2 Generalization o f Ra ptor codes from erasure channels to bi nary sym metric channels (BSCs) w as st udied by Etesami and Shokrollahi in [5]. In [6], Shamai, T elatar and V erd ´ u systematically extended fountain communication to arbit rary channels and showed that fountain capacity [6] and Shannon capacity take the same v al ue for s tationary mem oryless channels. Achiev ability of fou ntain capacity was demonstrated in [6] using a random codi ng scheme whos e error probabil ity decreases exponentially in the num ber of recei ved symbol s. Unfort unately , the random coding scheme consi dered in [6] is impractical due to it s exponential complexity . In classical point-t o-point comm unication over a discrete-tim e memo ryless chann el, it is well known that Shannon capacity can be achi e ved wit h an exponential error probability scaling law and a lin ear encoding/decoding compl exity [7][ 8]. The fact that comm unication error probabili ty can decrease expo- nentially i n the codeword leng th at any information rate below th e capacity was firstly shown by Feinstein [9]. The corresponding exponent was defined as the error exponent. Tight lower and upper bounds o n error exponent were obtain ed by Gallager [10 ], and by Shannon, Gallager , B erlekamp [11], respectively . In [12], Forne y proposed a on e-le vel concatenated coding scheme t hat com bines a Hamming-sense error correction outer code with Shannon-sense random inner channel codes. One-le vel concatenated codes can achie ve a positive error exponent, known as the Forney’ s exponent, for any rate less than Shannon capacity with a po lynomial complexity [12]. Forney’ s concatenated codes were generalized b y Blokh and Zyablov [13] to mult i-lev el concatenated codes, whose maximum achie vable error exponent is known as the Blokh-Zyablov error exponent. In [7], Guruswami and Indyk introd uced a class of linear complexity near maximum distance separable (MDS) error-correction codes. By using Guruswami-Indyk’ s codes as the ou ter codes in concatenated codi ng schemes, achieva bility of F orney’ s and Blokh-Zyabl ov exponents with linear coding complexity ov er general discrete-time memoryless channels was proved in [8]. In this paper , we show that classical concatenated coding schemes can be extended to fountai n commu- nication over the discrete-time memoryl ess channel to achie ve positiv e fountain error exponent (defined in Section II) at any rate below the fountain capacity with a linear coding comp lexity . Achiev able error exponents for one-lev el and m ulti-leve l concatenated fountain codes are derived. W e sho w that these error exponents are close in v alue to their upper bounds, which a re F orney’ s exponent [12] for one-le vel concatenation and Blokh-Zyablov e xponent [13] for multi-level concatenation, respectively . W e also show that concatenated fountain codes possess s e veral interesting properti es useful for network app lications. More specifically , wh en one or more transmitters send comm on inform ation to multip le recei vers over 3 discrete-time memoryless channels, concatenated fountain codes can often achieve near optimal rate and error performance simu ltaneously for all receiv ers e ven i f t he recei vers have different p rior knowledge about the transmit ted message. The rest of the paper is organized as follows. The fountain communicatio n model is defined in Section II. In Section III , we i ntroduce the prelim inary results on random fountain codes, which are basic components of th e concatenated coding schemes. One-le vel and multi-lev el concatenated fou ntain codes are introduced in Section IV. Special properties of concatenated fountain codes i n network communication scenarios are introduced in Sections V and VI. The conclusions are given in Section VII. W e use natural l ogarithms throughout this paper . I I . F O U N T A I N C O M M U N I C A T I O N M O D E L Consider the foun tain communi cation system illu strated in Figure 1. Assume that the encoder uses a foun tain codin g scheme [6] with W code words to map the source message w ∈ { 1 , 2 , · · · , W } in to an infinite channel input symbol sequence { x w 1 , x w 2 , · · ·} . Assume that the channel is discrete-time memoryless, characterized by the conditional point m ass function (PMF) or probability density function (PDF) p Y | X ( y | x ) , where x ∈ X is the channel input symbol with X being the finite channel inpu t alphabet, and y ∈ Y is channel output symbol with Y being the finite channel out put alphabet, respectiv ely . Assume that the channel information is kno wn at both t he encoder and the dec oder 1 . The channel outpu t symbols are then passed thro ugh an erasure device wh ich generates arbitrary erasures. Define s chedule N = { i 1 , i 2 , · · · , i |N | } as a s ubset of po sitive in tegers, where |N | is its cardinality [6]. Assume that the erasure device generates era sures o nly at those ti me instances not belongi ng to schedule N . In other words, only the channel output symbols wi th indices in N , denot ed by { y w i 1 , y w i 2 , · · · , y w i |N | } , are obs erved by the rece ive r . The schedule N is arbitrarily chosen and u nknown at the encoder . Rate and error performance variables of the system are d efined as follows. W e s ay the foun tain rate of the system is R = (log W ) / N , if the decoder , after observing |N | = N channel symbols , outputs an estimate ˆ w ∈ { 1 , 2 , · · · , W } o f the s ource m essage based on { y w i 1 , y w i 2 , · · · , y w i |N | } and N . Decoding error h appens when ˆ w 6 = w . Define err or probability P e ( N ) as, P e ( N ) = max w sup N , |N |≥ N P r { ˆ w 6 = w | w , N } . (1) 1 The case when channel information is not av ai lable at t he encoder will be in vestigated in Section VI. 4 W e say a foun tain rate R is achievable if there exists a fount ain codin g scheme with lim N →∞ P e ( N ) = 0 at rate R [6]. The exponential rate at which error probabilit y vanishes is defined as t he fountain error exponent, denoted by E F ( R ) , E F ( R ) = lim N →∞ − 1 N log P e ( N ) . (2) Define fountain capacity C F as the supremum of all achie vable fountain rates. It was shown i n [6] that C F equals Shanno n capacity of the stationary memo ryless channel. No te th at th e scaling law h ere i s defined with re spect to the number of r eceived symbols. I I I . R A N D O M F O U N TA I N C O D E S In a random foun tain cod ing s cheme [6], encoder and decoder share a fountain code library L = { C θ : θ ∈ Θ } , whi ch is a coll ection o f fountain codebook s C θ indexed by a s et Θ . All codebook s in the lib rary hav e the same number of codewords and each code word has an infini te num ber of channel input symbols. Let C θ ( w ) j be the j th code word sym bol in codebook C θ corresponding to mess age w , for j ∈ { 1 , 2 , · · ·} . T o encode the message, the encoder first selects a codebook by generating θ according t o a distribution ϑ , such that the random variables x w ,j : θ → C θ ( w ) j are i.i.d. with a pre-determined input dis tribution p X [6]. Then the encoder uses codebook C θ to map the message into a codew ord. W e assume that the actual realization of θ is known to the decoder but is unknown t o the era sure device. Therefore channel erasures, although arbitrary , are independent from the codebook generatio n. Maximum likelihood decoding is assumed at t he decoder given the knowledge of the codebook, schedule, and channel information [6]. Due to the random codebook selection, wi thout being cond itioned on θ , the error probability experienced by each message is identical. Therefore, t he error probabi lity P e ( N ) d efined in (1) can b e written as follows [6], P e ( N ) = ma x w sup N , |N |≥ N P r { ˆ w 6 = w | w , N } = sup N , |N |≥ N 1 W X w P r { ˆ w 6 = w | w , N } . (3) Theor em 1: Consider fountain com munication over a discrete-time memoryless channel p Y | X . Let C F be the fountain capacity . For any fountain rate R < C F , random fount ain codes achieve the foll owing random-coding fountain error e xponent E F r ( R ) = max p X E F L ( R, p X ) , (4) 5 where E F L ( R, p X ) is defined as E F L ( R, p X ) = ma x 0 ≤ ρ ≤ 1 {− ρR + E 0 ( ρ, p X ) } , E 0 ( ρ, p X ) = − log X y X x p X ( x ) p Y | X ( y | x ) 1 1+ ρ ! (1+ ρ ) . (5) If the channel is cont inuous, t hen su mmations in (5) should be replaced by integrals. Theorem 1 was c laimed implicitly in, and can be sho wn by , the proof of [6, Theorem 2]. E F r ( R ) given in (4) equals the random-codi ng exponent of a classical com munication system over the same channel [10]. For binary symmetric channels (BSCs), since random li near codes simult aneously achie ve the random-coding exponent at high rates and the expurgated exponent at low rates [14], it can be easily shown that the same fountain error exponent is achiev able by random l inear fountain codes. Howe ver , it is not clear whether there exists an expur g ation operation, such as t he one proposed in [10], that is rob us t to the observ ation of any subset of channel outputs . T herefore, whether th e expurgated exponent is achieva ble for fou ntain communication over a general discrete-time mem oryless channel is unknown. I V . C O N C A T E N A T E D F O U N TA I N C O D E S Consider a one-lev el concatenated fountain codin g scheme illustrated in Figure 2 . Ass ume t hat s ource message w can take ⌊ exp( N R ) ⌋ possi ble values wi th equiprobabili ty , where R is the targeted fountain information rate. Assume t hat the communication terminat es after N channel out put sym bols are observed at the d ecoder . T he o ne-lev el concatenated fountain code cons ists of an outer code and se veral inner codes. The encoder first encodes the message using the outer code in to an out er code word { ξ 1 , ξ 2 , · · · , ξ N o } , with N o outer symbols, each belongi ng t o a finite field of appropriate size. W e ass ume th at the outer code is a linear-time encodable/decodable near MD S error-corre ction code of rate r o ∈ (0 , 1] . That is, at a fixed r o and as N o is taken to in finity , th e outer cod e can reco ver t he source message from a receiv ed code word with dN o symbol erasures and tN o symbol errors, so long as 2 t + d ≤ (1 − r o − ζ 0 ) , where ζ 0 > 0 is a positive constant that can be made arbit rarily small . The encoding and decoding com plexities are linear in the number of outer codew ord length N o . An example of such linear complexity error-correction code was present ed by Guruswami and Indyk in [7]. Each outer sy mbol ξ k ( k ∈ { 1 , · · · , N o } ) can take j exp N N o R r o k possible v alues. W e use a set of random fountain codes described in Section III as the inner codes, each with ⌊ exp( N i R i ) ⌋ code words, where N i = N N o and R i = R r o . T o simplify the notations, we have assum ed that N i and N o 6 are both integers. W e also assume that N o ≫ N i ≫ 1 . The encoder then uses these inner codes to map each outer sy mbol ξ k into an i nner code word, which is an infinite sequence of channel i nput symbo ls { x k 1 , x k 2 , · · ·} . The inner codew ords are regarded as N o channel input symbol queues, as shown in Figure 2. In each time unit, the encoder us es a random switch to pick one inner code and sends th e first channel input symbol in the corr esponding queue through the channel as mo deled in Sec tion II. The transmitted symbol is then removed from the queue. W e use θ to index the realization of the compounded randomness of codebook generation and swit ch selectio n. Let C ( k ) θ ( ξ k ) j be the j th code word symbol of the k th inner code in codebook C ( k ) θ , corresponding to ξ k . Let Z l,θ ∈ { 1 , · · · , N o } be index o f the queue that the random switch chooses at t he l th time unit for l ∈ { 1 , 2 , · · ·} . W e assume that ind ex θ i s generated according to a dist ribution ϑ such that random v ariables x k ,ξ k ,j : θ → C ( k ) θ ( ξ k ) j are i.i.d. wit h a pre-determined input distribution p X , random variables I l : θ → Z l,θ are i.i.d. uniform, x k ,ξ k ,j and I l are independent. The decoder is assumed to know the outer codebook and the code libraries of the inner codes. W e also assume that t he decoder knows the exact codebook used for each inner code and the exact order in which channel input symbols are transm itted. Decoding st arts after N = N o N i channel outpu t sym bols are recei ved. The decoder first di stributes the recei ved sym bols to t he corresponding inner codes. Assu me that, for k ∈ { 1 , · · · , N o } , z k N i channel output symbo ls are recei ved from the k th inner code, where z k > 0 and z k N i is an int eger . W e term z k the “eff ective codeword l ength parameter” of th e k th inner code. By definition, we have P N o k =1 z k = N o . Based on z k , and the recei ved channel out put symbols, { y k i 1 , y k i 2 , . . . , y k i z k N i } , the decoder computes the maximum likelihood est imate ˆ ξ k of the outer symbol ξ k together with an optim ized reliabilit y weight α k ∈ [0 , 1] . W e assume that, given z k and { y k i 1 , y k i 2 , · · · , y k i z k N i } , reliabil ity weight α k is com puted using Forne y’ s algorithm presented in [12, Section 4.2]. W ith { ˆ ξ k } and { α k } for all k , t he decoder then carries out a generalized minim um distance (GMD) decoding of the out er code and ou tputs an estim ate ˆ w of the source message. GMD decoding of the outer code here is the same as that in a classical com munication system, the detail of which can be found in [8]. Due to random codebook selection and random switching, without being conditioned on θ , error probabilities experienced by all messages are equal, i.e., P e ( N ) satisfies (3). Compared wit h a classical concatenated code where all inner codes have the same length, in a concatenated fountain coding scheme, numbers of recei ved sy mbols from dif ferent inner codes may be dif ferent. Consequentl y , error exponent achie vable by one-level concatenated fountain codes, gi ven in the following theorem, is less than Forney’ s 7 exponent. Theor em 2: Consider fountain communicati on over a discrete-time mem oryless channel p Y | X with fountain c apacity C F . For any fountain rate R < C F , the following fountain error e xponent can be arbitrarily a pproached by o ne-le vel concatenated fountain codes, E F c ( R ) = max p X , R C F ≤ r o ≤ 1 , 0 ≤ ρ ≤ 1 (1 − r o ) − ρ R r o + E 0 ( ρ, p X ) 1 − 1 + r o 2 E 0 ( ρ, p X ) , (6) where E 0 ( ρ, p X ) is defined in (5). Encoding and decoding complexities of the one-lev el concatenated codes are l inear in the number of transmitted symbols and the n umber o f re ceiv ed s ymbols, re spectively . The proof of Theorem 2 is given in Appendix A. Corollary 1: E F c ( R ) is upper -bounded by Forney’ s error exponent E c ( R ) giv en in [12], and is lower - bounded by ˜ E F c ( R ) , defined by ˜ E F c ( R ) = max p X , R C F ≤ r o ≤ 1 , 0 ≤ ρ ≤ 1 (1 − r o ) − ρ R r o + E 0 ( ρ, p X ) [1 − E 0 ( ρ, p X )] . (7) The bounds are asymptotically t ight in the sense that lim R →C F ˜ E F c ( R ) E F c ( R ) = 1 . The proof of Corollary 1 is gi ven in Appendix B. In Figure 3, we illustrate E F c ( R ) , E c ( R ) , and ˜ E F c ( R ) for a BSC wit h crossover probability 0 . 1 . W e can see that E F c ( R ) is closely approxim ated by ˜ E F c ( R ) , especially at rates clo se to the fountain capacity . Extending the one-level concatenated fountain codes to the m ulti-level concatenated fountain codes is essentially the same as in classical communicatio n sy stems [13][8] except that random fountain codes are used as inner codes in a fountain system. For a posi tive integer m , the achieva ble error exponent of an m -le vel concatenated fountain c odes is given in the following Theorem. Theor em 3: Consider fountain communicati on over a discrete-time mem oryless channel p Y | X with fountain c apacity C F . For any fountain rate R < C F , the following fountain error e xponent can be arbitrarily a pproached by an m -lev el ( m ∈ { 1 , 2 , · · · } ) c oncatenated fountain codes, E ( m ) F c ( R ) = max p X , R C F ≤ r o ≤ 1 R r o − R R r o m P m i =1 h E F L i m R r o , p X i − 1 , E F L ( x, p X ) = max 0 ≤ ρ ≤ 1 ( − ρx + E 0 ( ρ, p X ) [1 − E 0 ( ρ, p X )]) , (8) where E 0 ( ρ, p X ) is defined in (5). For a give n m , the encod ing and decodi ng complexities of the m -le vel concatenated codes are linear in t he number of transmitted sym bols and the number of recei ved symbol s, respectively . 8 Theorem 3 can be proved by following the analy sis of m -level concatenated codes presented in [13 ][15] and replacing the error exponent of code i n each con catenation lev el with t he corresponding error exponent lower bound gi ven in Corollary 1. Corollary 2: The f ollowing fountain error e xponent can be arbitrarily approached by multi-level con- catenated fountain codes with l inear encoding /decoding comp lexity , E ( ∞ ) F c ( R ) = max p X , R C F ≤ r o ≤ 1 R r o − R " Z R r o 0 dx E F L ( x, p X ) # − 1 , (9) where E F L ( x, p X ) is defined in (8). In Figure 4, we illustrate E ( ∞ ) F c ( R ) and the Blokh-Zyablov e xponent E ( ∞ ) c ( R ) for a BSC with crossover probability 0 . 1 . It can be seen that E ( ∞ ) F c ( R ) does not deviate si gnificantly f rom the Blokh-Zyablov exponent, which is the error e xponent upper bound for mu lti-leve l concatenated fountain codes. V . R A T E C O M P A T I B L E F O U N TA I N C O M M U N I C A T I O N In this section, we consider the fountain communication where the r eceiv er already has partial knowledge about the transmitted m essage. T ake t he application of s oftware patch distribution as an example. When a significant number of patches are released, the software company may want to combine the patches together as a service pack. Howe ver , if a user already has some of the patches, he may only want to download the ne w patches, rather t han the whole service pack. On on e hand, for the conv enience of t he p atch s erver , all patches of th e service pack should be encoded jointly . On the other hand, for the comm unication ef ficiency of each p articular user , we als o want the fountain s ystem to achiev e the same rate and error performance as if only the novel part of the service pack is transmitted. W e require such performance o bjectiv e to be achie ved sim ultaneously for all users, and define such a fountain communication model as t he rate compatible fountain communi cation. W e will show next t hat efficient rate com patible fountai n comm unication can be achie ved using a class of extended concatenated foun tain codes with linear complexity . Assume that a source message w , which takes ⌊ exp( N R ) ⌋ pos sible va lues, is partitioned into L sub-messages [ w 1 , w 2 , · · · , w L ] , where w i ( i ∈ { 1 , · · · , L } ) can take ⌊ exp( N r i ) ⌋ possible v alues wi th P i r i = R . Cons ider the following extended on e-le vel concatenated fountain coding scheme. For each i ∈ { 1 , · · · , L } , the encoder first us es a near MDS out er c ode with leng th N o and rate r o to encod e sub- message w i into an outer codeword { ξ i 1 , · · · , ξ iN o } , as il lustrated in Figure 5. Next, for all k ∈ { 1 , · · · , N o } , 9 the encoder com bines outer codew ord symbols { ξ 1 k , · · · , ξ Lk } into a macro symbol ξ k = [ ξ 1 k , · · · , ξ Lk ] . A random f ountain code is then used to map ξ k into an infinite channel i nput sequence { x k 1 , x k 2 , · · ·} . W itho ut loss of generality , we a ssume that there is only one decoder ( receiv er) and it already has sub- messages { w l +1 , · · · , w L } , where l ∈ [1 , L − 1] is an integer . The decoder estimates the source message after N l = N P l i =1 r i R channel output symbol s are recei ved 2 . From the decoder’ s point of view , since the un known messages [ w 1 , · · · , w l ] can only take ⌊ exp ( N P l i =1 r i ) ⌋ possible values, the effective fountain information rate of the sys tem is R ef = N P l i =1 r i N l = R . According to the known m essages { w l +1 , · · · , w L } , t he decoder first strike s out from fountain codebooks all codew ords corresponding to the wrong messages. The extended one-lev el concatenated fountain code is then decoded using t he same procedure as described in Section IV. Ass ume that the aver age n umber o f s ymbols receiv ed by each inner code word ˜ N i = N l N o = N N o P l i =1 r i R is lar ge enough to enable asymptotic analysis. By following a similar analysis given in the proof of Theorem 2, it can be seen that e rror exponent E F c ( R ) gi ven in (6) can still b e ar bitrarily approached. Therefore, give n a rate partit ioning R = [ r 1 , · · · , r L ] , the encoder can encode t he complete message irrespectiv e of the s ub-messages known at th e decoder . The fountain system can achiev e the same rate and error performance as if only the unknown sub-messages are encoded and transmitted. If the system has mul tiple receiv ers wit h different priori sub-messages, the rate and error performance tradeoff as characterized in Th eorem 2 can be achiev ed si multaneously for all receivers. Extendin g this scheme to the multi-lev el concatenated codes is straightforward. V I . F O U N TA I N C O M M U N I C A T I O N OV E R A N U N K N O W N C H A N N E L In pre vious sections, we have assumed that concatenated fountain codes shou ld be optim ized based on a known discrete-time memoryless channel m odel p Y | X . Howe ver , such an optim ization may fac e va rious challenges in practical applications. For example, s uppose that a transmit ter broadcasts encoded symbols to mul tiple receiv ers simul taneously . Channels experienced by di ff erent receiver s may be different. Even if the channels are known, the transmi tter still needs to optimize fountai n codes s imultaneousl y for multipl e channels. For anot her example, s uppose that t he source message (e.g., a software patch) is ava ilable at multiple servers. A user may coll ect encoded sym bols from mu ltiple servers separately over different channels and use t hese s ymbols to joi ntly decode the message. By regarding the symbols as receiv ed over a vi rtual c hannel, we want the fountain system to achieve good ra te and error performance without requiring the ful l statistical model of th e virtual channel at the transmi tter . W e term t he communicati on 2 Assume t hat N l and N l / N o are both integers. 10 model in the latter e xample the rate combining fountain communication. In b oth examples, the research question is whether ke y codin g para meters can b e d etermined without full channel knowledge at the transmitter . In this section, we s how that, e ven when t he channel state is unknown at the transmitter , i t is still p ossible to achiev e n ear optimal rate and error performance using concatenated fountain codes. Consider fountain comm unication o ver a discrete-time memoryless channel p Y | X using one-le vel con- catenated fountain codes. W e assume that the channel is sym metric, and hence the opti mal input dis tribu- tion p X is known at the transmit ter . Other than channel alphabets and the symm etry property , we assume that channel i nformation p Y | X is unknown at the transm itter , but known at the receiver . Given p X , define I ( p X ) = I ( X ; Y ) as th e mutu al information between the inp ut and output of the memoryless channel. W e assu me th at the t ransmitter and the receiv er agree on achieving a fount ain information rate of γ I ( p X ) where γ ∈ [0 , 1] is ter med the normal ized fount ain rate, known at the transmit ter . Recall from the proof o f Theorem 2 t hat, if p Y | X is known at the transmitt er , the outer code rate r o can be predetermined at the transmitter and the following error exponent can be arbit rarily appro ached, E F c ( γ , p X ) = max 0 ≤ r o ≤ 1 E F c ( γ , p X , r o ) , E F c ( γ , p X , r o ) = max 0 ≤ ρ ≤ 1 (1 − r o ) I ( p X ) − ρ γ r o + E 0 ( ρ, p X ) I ( p X ) 1 − 1 + r o 2 E 0 ( ρ, p X ) ! . (10) W itho ut p Y | X at the transmitter , th e o ptimal r o cannot be deri ved. Howe ver , with the knowledge of γ , we can set a sub optimal ou ter code rate by lett ing r o = √ γ 2 +8 γ − γ 2 and define the corresponding error exponent by E F cs ( γ , p X ) = E F c γ , p X , r o = √ γ 2 + 8 γ − γ 2 ! . (11) The follo wing theorem indicates t hat E F cs ( γ , p X ) approaches E F c ( γ , p X ) asymptotically as γ → 1 . Theor em 4: Gi ven the discrete-time memoryless channel p Y | X and a so urce dist ribution p X , the fol- lowing limit holds, lim γ → 1 E F cs ( γ , p X ) E F c ( γ , p X ) = 1 . (12) The proof of Theorem 4 is given in Appendix C. In Figure 6, we plot E F cs ( γ , p X ) and E F c ( γ , p X ) for BSC with crossover probabil ity 0 . 1 . It can be seen that setting r o at r o = √ γ 2 +8 γ − γ 2 is near opt imal for all normalized fountain rate values. Indeed, computer simulatio ns suggest that such optimalit y conclusi on app lies to a w ide range of channels over a wid e range of fountain rates. Ho wev er , furth er in vestigation on this issue is outsi de the scope o f this paper . 11 V I I . C O N C L U S I O N S W e extended l inear- complexity concatenated codes to fountain communication over a discrete-time memoryless channel. Fountain error exponents achiev able by on e-le vel and multi-level concatenated cod es were deriv ed. It was shown t hat the fountain error e xponents are l ess than but close to Forney’ s and Blokh-Zyablov exponents. In rate compatible com munication where decoders know part of th e transm itted message, with the encoder st ill encoding the complete message, concatenated fountain codes can a chiev e the same rate and error performance as i f only the nov el part of th e message i s encoded for each individual user . For one-lev el concatenated codes and for certain channels, it was also shown that near optim al error exponent can be achieved with an outer code rate independent of the channel statis tics. A P P E N D I X A. Pr oof of Theor em 2 Pr oof : W e first introduce the basic idea of the proo f. Assume that the d ecoder st arts decoding after receiving N = N o N i symbols, where N o is t he length of the outer codeword, N i is th e expected number of received symbols from each inner code. In the fol lowing error exponent anal ysis, we wil l obtain asymptotic resu lts by first taking N o to i nfinity and then taking N i to infinity . Let z be an N o -dimensional vector whose k th element z k is the eff ective code word length parameter of the k th inner code, for k ∈ { 1 , · · · , N o } . Note t hat z is a random vector . L et dz > 0 be a small constant. W e define { z g | z g = ndz , n = 0 , 1 , . . . , } as th e set of “grid values” each can be written as an non-negati ve i nteger multip lying dz . Define a point mass fun ction (PMF) f ( dz ) Z as follows. W e first quantize each element o f z , for example z k , to t he closest g rid v alue no lar ger than z k . Denote the quantized z vector by z ( q ) , whose elements are denoted by z ( q ) i for i ∈ { 1 , · · · , N o } . For an y grid value z g , we define I z g = n i z ( q ) i = z g o as the set of indices corresponding t o which the elements of z ( q ) vector equal the particular z g . Giv en z , the empirical PMF f ( dz ) Z is a function defined for the grid values, with f ( dz ) Z ( z g ) = |I z g | N o , where | I z g | is the cardinalit y of I z g . Since f ( dz ) Z is induced from r andom vector z , itself is ra ndom. Let P r n f ( dz ) Z o denote the probability t hat the rec eiv ed ef fective inner codeword length parameter v ector z gives a particular PMF f ( dz ) Z . Let us now consider a decodi ng algori thm, called “ dz -decoder” , which is the same as th e on e introdu ced in Section IV except that the decoder , after recei ving N i z k symbols for the k th inner code (for all k ∈ 12 { 1 , · · · , N o } ), only uses the fi rst N i z ( q ) k symbols to decode the i nner code. Assume that the foun tain information rate R , the outer code rate r o , and the in put distribution P X are given. Due to sy mmetry , it is easy to see that, wit hout being conditioned on random variable θ (defined in Section IV), d iffe rent z vectors corresponding to the same f ( dz ) Z (which is indeed induced from z ( q ) ) give the same error probability performance. Let P e f ( dz ) Z be the commu nication error probability of the dz -decoder giv en f ( dz ) Z . Comm unication error probabili ty P e of the dz -dec oder without gi ven f ( dz ) Z can be written as, P e = X f ( dz ) Z P e f ( dz ) Z P r n f ( dz ) Z o . (13) For a given f ( dz ) Z , define E f ( f ( dz ) Z ) = − lim N i →∞ lim N o →∞ 1 N i N o log P e f ( dz ) Z . Consequently , we can find a constant K 0 ( N i , N o ) , su ch that the following inequality hol ds for all f ( dz ) Z and all N i , N o , P e f ( dz ) Z ≤ K 0 ( N i , N o ) exp − N i N o E f f ( dz ) Z , lim N i →∞ lim N o →∞ log K 0 ( N i , N o ) N i N o = 0 . (14) Giv en dz , N i , N o , let K 1 ( N i , N o ) be the total number of possib le quanti zed z ( q ) vectors (the quantized vector of z ). K 1 ( N i , N o ) can be upper b ounded by K 1 ( N i , N o ) ≤ 2 N o l N o dz m + N o − 1 ! l N o dz m !( N o − 1)! . (15) In the above b ound, the term ( ⌈ N o dz ⌉ + N o − 1 ) ! ( ⌈ N o dz ⌉ ) !( N o − 1)! represents the total number of possible outcomes of assigni ng l N o dz m identical balls to N o distinctive boxes. This is the number of possib le z ( q ) vectors we can get if the recei ved s ymbols are assigned to the inner codes in g roups with N i dz (assum ed to be an integer) symbols per group. Let us t erm the assumpt ion of assign ing recei ved sy mbols i n groups the “symbol -grouping” assumption . T o relax the symbol-grouping assumption, we no te that, if the number of symbols obtained by an inner code, say th e k th inner code, is a litt le less that an i nteger multiplication of N i dz , then the quantization value z ( q ) k obtained without the sym bol-grouping assumption can be one unit less than t he corresponding value with the symbol-groupi ng assumption. Therefore, the total n umber of possible z ( q ) vectors we can get without the sym bol-grouping ass umption is upper bounded by 2 N o multiply ing the corresponding number with the sy mbol-groupin g assumption. Not e that, give n dz , t he right hand side of (15) is not a function of N i , and i t is also an upper bound on the total numb er of possible f ( dz ) Z functions. Due to Stirling’ s approximation [16], (15) i mplies t hat lim N o →∞ log K 1 ( N i ,N o ) N o < ∞ , and hence lim N i →∞ lim N o →∞ log K 1 ( N i , N o ) N i N o = 0 . (16) 13 Combining ( 13), (14) and (16), the error e xponent of a dz -decoder is gi ven by E F c = − lim N i →∞ lim N o →∞ log P e N i N o = min f ( dz ) Z E f f ( dz ) Z − lim N i →∞ lim N o →∞ 1 N i N o log P r n f ( dz ) Z o . (17) The rest of the proof contains four parts. In Part I, the expression of lim N i →∞ lim N o →∞ 1 N i N o log P r n f ( dz ) Z o is deriv ed. In Part II, we deriv e the expression of E f f ( dz ) Z . In Par t III, we use the results of the first two parts to obtain lim dz → 0 E F c . Complexity and the achiev able error exponent of th e concatenated fountain code is obtained based on the der ive d re sults in Part IV . Part I: Let z ( i ) (for all i ∈ { 1 , · · · , N o } ) be an N o -dimensional vec tor with onl y o ne non-zero elem ent corresponding to the i th recei ved symbo l. If the i th recei ved sym bol belon gs to the k th inner code, then we let the k th element of z ( i ) equal 1 and let all other elements equal 0 . Since the random s witch (illustrated in Fig ure 2) picks inner codes uniformly , we hav e E [ z ( i )] = 1 N o 1 , cov [ z ( i )] = 1 N o I N o − 1 N o 2 11 T , (18) where 1 is an N o -dimensional vec tor with all elements being one, and I N o is the identit y m atrix o f size N o . According to the definiti ons, we ha ve z = 1 N i P N i N o i =1 z ( i ) . Since the total number of recei ved symbols equal N i N o , we must ha ve 1 T z = N o . Let ω be a real-valued N o -dimensional vector whose entries satisfy − π √ N i N o ≤ ω k < π √ N i N o , ∀ k ∈ { 1 , · · · , N o } . Since z equals the normalized su mmation of N i N o independently distri buted v ectors z ( i ) , the characteristic function of q N i N o ( z − 1 ) , denoted by ϕ Z ( ω ) = E h exp j q N i N o ω T ( z − 1 ) i , can t herefore be written as ϕ Z ( ω ) = E " exp j s N i N o ω T ( z − 1 ) !# = N i N o Y i =1 E " exp j s 1 N i N o ω T ( z ( i ) − 1 N o 1 ) !# = ( E " exp j s 1 N i N o ω T ( z ( i ) − 1 N o 1 ) !#) N i N o = " 1 − 1 2 k Q T ω k 2 N 2 o N i + o k Q T ω k 2 N 2 o N i !# N o N i , (19) where i n the last equalit y , Q is a real-valued N o × ( N o − 1) -dimensional matrix satisfying Q T Q = I N o − 1 and Q T 1 = 0 , whi ch imply QQ T = I N o − 1 N o 11 T . In other words, k Q T ω k 2 = ω T ( I N o − 1 N o 11 T ) ω . Note that, since z is discrete-valued, ϕ Z ( ω ) is similar to a multi-dimensional dis crete-time F ourier transform o f the PMF of q N i N o ( z − 1 ) . Because √ N i N o hq N i N o ( z − 1 ) i = P N i N o i =1 z ( i ) − N i 1 takes integer- valued entries, t he ϕ Z ( ω ) function is periodic ω in the sense that ϕ Z ω + 2 π √ N i N o e k = ϕ Z ( ω ) , k ∈ { 1 , · · · , N o } , where e k is an N o -dimensional vector whose k th entry is one and all other entries are zeros. This is why we can focus on “frequency” vector ω with − π √ N i N o ≤ ω k < π √ N i N o , ∀ k ∈ { 1 , · · · , N o } . 14 Equation (19) implies that lim N o →∞ ϕ Z ( ω ) − exp − 1 2 N o ω T QQ T ω = 0 . (20) Therefore, wi th lar ge enough N o and for any z , t he probability P r { z } is upper -bou nded by P r { z } ≤ 1 2 π √ N i N o ! N o N o 2 π N o − 1 2 exp − N i 2 h k z − 1 k 2 − dz k 1 k 2 i , (21) where the constant 2 π √ N i N o in the denominato r of the first term on the right hand s ide of (21) is due to the range of − π √ N i N o ≤ ω k < π √ N i N o , ∀ k ∈ { 1 , · · · , N o } . The constant dz k 1 k 2 in the exponent of (21) is added to ensure the existence of a lar ge enough N o to satisfy the inequality , as implied by (20). Inequality (21) further implies that P r { z } ≤ 1 2 π √ N i N o ! N o N o 2 π N o − 1 2 exp − N i 2 h k z ( q ) − 1 k 2 − 3 dz k 1 k 2 i , (22) where z ( q ) is the quantized ve rsion o f z . C onsequently , the probabili ty of z ( q ) is upper -bound ed by P r n z ( q ) o ≤ ⌈ N i dz ⌉ N o 1 2 π √ N i N o ! N o N o 2 π N o − 1 2 exp − N i 2 h k z ( q ) − 1 k 2 − 3 N o dz i . (23) The probability of any PMF f ( dz ) Z is upper -bound ed by P r n f ( dz ) Z o ≤ K 1 ( N i , N o ) P r n z ( q ) o ≤ K 1 ( N i , N o ) ⌈ N i dz ⌉ N o 1 2 π √ N i N o ! N o N o 2 π N o − 1 2 exp − N i 2 h k z ( q ) − 1 k 2 − 3 N o dz i , (24) where K 1 ( N i , N o ) is the total nu mber of possible z ( q ) vectors satisfyin g (16). From (24), we can see that f or all f ( dz ) Z the fol lowing inequality holds, − lim N i →∞ lim N o →∞ log P r n f ( dz ) Z o N i N o ≥ 1 2 X z g h ( z g − 1) 2 − 3 dz i f ( dz ) Z ( z g ) , (25) where f ( dz ) Z ( z g ) is the v alue o f P MF f ( dz ) Z at z g . Note t hat, b ecause 1 T z = N o , for all empirical PMFs f ( dz ) Z , we have P z g z g f ( dz ) Z ( z g ) ∈ [1 − dz , 1] . Part II: Next, we will derive the expression of E f f ( dz ) Z , whi ch is the error exponent condition ed on an empirical PMF f ( dz ) Z . Let z be a particular N o -dimensional effecti ve inner codeword length p arameter vector following the empirical PMF f ( dz ) Z , under a giv en dz . Let P e ( z ) be the error p robability given z ( or z ( q ) ). Let P e ( f ( dz ) Z ) be the error p robability giv en f ( dz ) Z . From the definit ion of the concatenated fountain codes, we can see that the inn er codes are logically equiv alent, so do the cod e word symbols of the near MDS outer code. In other words, error probabilit ies corresponding to all z vectors with th e same PMF f ( dz ) Z are equal. Thi s 15 consequently implies t hat P e ( z ) = P e ( f ( dz ) Z ) . Therefore, when bound ing E f f ( dz ) Z , instead of assuming a particular f ( dz ) Z which corresponds to mult iple z vectors, we can assume a single z vector whose corresponding empirical PMF is f ( dz ) Z . Assume t hat the outer code h as rate r o , and is able t o recov er the source message from dN o outer symbol erasures and tN o outer symbol errors so long as d + 2 t ≤ (1 − r o − ζ 0 ) , where ζ 0 > 0 is a constant satisfying lim N i →∞ lim N o →∞ ζ 0 = 0 . An example of such near MDS code was introduced in [7]. Assume that, for all k , the k th outer codeword s ymbol is ξ k , and the k th inner code reports an esti mate of the outer symbol ˆ ξ k together with a reliabil ity weight α k ∈ [0 , 1] . Appl ying Forney’ s GMD decoding to the outer code [8], the source message can be recovered i f the following inequalit y ho lds [12, Theorem 3.1b], N o X k =1 α k µ k > ( r o + ζ 0 ) N o , (26) where µ k = 1 if ˆ ξ k = ξ k , and µ k = − 1 if ˆ ξ k 6 = ξ k . Consequentl y , error probabi lity conditioned on the giv en z vector is bounded by P e ( f ( dz ) Z ) = P e ( z ) ≤ P r ( N o X k =1 α k µ k ≤ ( r o + ζ 0 ) N o ) ≤ min s ≥ 0 E h exp − sN i P N o k =1 α k µ k i exp( − sN i ( r o + ζ 0 ) N o ) , (27) where the last inequality is due to Chernoff ’ s bound. Giv en the effecti ve inner cod e word length parameter vector z , random variables α k µ k for different inner codes are independent. Therefore, (27) can be further written as P e ( f ( dz ) Z ) = P e ( z ) ≤ min s ≥ 0 Q N o k =1 E [exp ( − sN i α k µ k )] exp( − sN i ( r o + ζ 0 ) N o ) = min s ≥ 0 exp P N o k =1 log E [exp ( − sN i α k µ k )] exp( − sN i ( r o + ζ 0 ) N o ) . (28) Now we will derive the expression of log E [exp ( − sN i α k µ k )] for the k th inner code. Assume that the effecti ve codeword length parameter is z k . Giv en z k , whose q uantized value is z ( q ) k , depending on the recei ved channel symbols, the decoder generates the maximum likelihood outer code estimate ˆ ξ k , and generates α k using Forne y’ s alg orithm presented in [12, Section 4.2 ]. Define an adjusted error exponent function E z ( z ) as follo ws. E z ( z ) = max 0 ≤ ρ ≤ 1 − ρ R r o + z E 0 ( ρ, p X ) , (29) where E 0 ( ρ, p X ) is defined i n (5). By following Forney’ s error exponent analysi s presented in [12, Section 4.2], we obtain − log E [exp ( − sN i α k µ k )] ≥ max n min { N i E z z ( q ) k , N i 2 E z z ( q ) k − s , N i s } , 0 o + K 2 ( N i , N o ) , (30) where K 2 ( N i , N o ) is a constant satis fying lim N i →∞ lim N o →∞ K 2 ( N i ,N o ) N i N o = 0 . 16 Define a function φ ( z , s ) as follo ws, φ ( z , s ) = − sr o z , E z ( z ) < s/ 2 2 E z ( z ) − (1 + r o ) s z , s/ 2 ≤ E z ( z ) < s (1 − r o ) s z , E z ( z ) ≥ s . (31) Substitute (30) into (28), and take N i , N o to i nfinity (wh ich implies ζ 0 → 0 ), we get the following bound on t he conditional error exponent E f f ( dz ) Z , E f f ( dz ) Z ≥ max s ≥ 0 X z g φ ( z g , s ) f ( dz ) Z ( z g ) . (32) Part III: According to (17 ), (25) and (32), we have E F c ≥ min f ( dz ) Z , P z g z g f ( dz ) Z ( z g ) ∈ [1 − dz , 1] E f ( f ( dz ) Z ) + X z g ( z g − 1) 2 2 f ( dz ) Z ( z g ) − 3 2 dz ≥ min f ( dz ) Z , P z g z g f ( dz ) Z ( z g ) ∈ [1 − dz , 1] max s ≥ 0 X z g φ ( z g , s ) + ( z g − 1) 2 2 ! f ( dz ) Z ( z g ) − 3 2 dz . (33) Define E (0) F c = lim dz → 0 E F c . Let f Z be a probabili ty density function defined for z ∈ [0 , ∞ ) . Inequality (33) implies that E (0) F c ≥ min f Z , R ∞ 0 z f Z ( z ) dz =1 max s ≥ 0 Z ∞ 0 φ ( z , s ) + ( z − 1 ) 2 2 ! f Z ( z ) d z = max s ≥ 0 min f Z , R ∞ 0 z f Z ( z ) dz =1 Z ∞ 0 φ ( z , s ) + ( z − 1 ) 2 2 ! f Z ( z ) d z . (34) Assume that f ∗ Z is t he densit y function minimi zing the last term in (34). If we can find 0 < λ < 1 , and two densit y functi ons f (1) Z , f (2) Z with R ∞ 0 z f (1) Z ( z ) d z = 1 , R ∞ 0 z f (2) Z ( z ) d z = 1 , such that f ∗ Z = λf (1) Z + (1 − λ ) f (2) Z , (35) then it is easy to show that the last term in (34) must be mi nimized either by f (1) Z or f (2) Z . Since this contradicts the assumption that f ∗ Z is op timum, a nontrivial decomposition like (35) must n ot be possible. Consequently , f ∗ Z can take non-zero values on at mos t two different z values. Therefore, we can carry out the optimizatio n in (34) only ove r th e fol lowing class of f Z functions, characterized by two variables 0 ≤ z 0 ≤ 1 and 0 ≤ γ ≤ 1 , f Z ( z ) = γ δ ( z − z 0 ) + (1 − γ ) δ z − 1 − z 0 γ 1 − γ ! , (36) where δ () is the im pulse functio n. 17 Let us fix γ first, and consider t he following lower bound on E (0) F c ( γ ) , which is ob tained by substit uting (36) into (34), E (0) F c ( γ ) ≥ min 0 ≤ z 0 ≤ 1 max s ≥ 0 γ φ ( z 0 , s ) + (1 − γ ) φ 1 − z 0 γ 1 − γ , s ! + γ 1 − γ (1 − z 0 ) 2 2 . (37) Since giv en z 0 , γ φ ( z 0 , s ) + (1 − γ ) φ 1 − z 0 γ 1 − γ , s is a linear function of s , dependi ng on the value of γ , the optimum s ∗ that maximizes the right hand side of (37) shoul d satisfy either s ∗ = E z ( z 0 ) or s ∗ = E z 1 − z 0 γ 1 − γ . When γ ≥ 1 − r o 2 , we have s ∗ = E z ( z 0 ) . This yields E (0) F c ≥ min 0 ≤ z 0 ,γ ≤ 1 " γ 1 − γ (1 − z 0 ) 2 2 + (1 − r o ) E z ( z 0 ) # . (38) When γ ≤ 1 − r o 2 , we have s ∗ = E z 1 − z 0 γ 1 − γ , whi ch gi ves E (0) F c ≥ min 0 ≤ z 0 ,γ ≤ 1 " 2 γ E z ( z 0 ) + γ 1 − γ (1 − z 0 ) 2 2 + (1 − r o − 2 γ ) E z 1 − γ z 0 1 − γ !# . (39) By substituting E z ( z ) = ma x 0 ≤ ρ ≤ 1 [ − ρ R r o + z E 0 ( ρ, p X )] into (39), we get E (0) F c ≥ min 0 ≤ z 0 ,γ ≤ 1 max 0 ≤ ρ ≤ 1 (1 − r o ) − ρ R r o + E 0 ( ρ, p X ) − γ 1 − γ " (1 + r o )(1 − z 0 ) E 0 ( ρ, p X ) − (1 − z 0 ) 2 2 #) . (40) Note that if (1 + r o )(1 − z 0 ) E 0 ( ρ, p X ) − (1 − z 0 ) 2 2 < 0 , then E (0) F c ≥ (1 − r o ) h − ρ R r o + E 0 ( ρ, p X ) i with the right hand side o f the inequalit y equaling F orney’ s exponent for gi ven p X and r o . This cont radicts with the fact that F o rney’ s exponent i s the m aximum achiev able exponent for one-level concatenated codes in a classical system [12 ]. Therefore, we m ust have (1 + r o )(1 − z 0 ) E 0 ( ρ, p X ) − (1 − z 0 ) 2 2 ≥ 0 . Consequently , the right hand sides of both (38 ) and (40) are mi nimized at the mar gin o f γ ∗ = 1 − r o 2 . This gives E (0) F c ≥ min 0 ≤ z 0 ≤ 1 ( (1 − r o ) E z ( z 0 ) + 1 − r o 1 + r o (1 − z 0 ) 2 2 ) = min 0 ≤ z 0 ≤ 1 max 0 ≤ ρ ≤ 1 ( (1 − r o ) − ρ R r o + E 0 ( ρ, p X ) + 1 − r o 1 + r o (1 − z 0 ) 2 [(1 − z 0 ) − 2(1 + r o ) E 0 ( ρ, p X )] ) . (41) Note that if ρ i s chosen to satisfy (1 + r o ) E 0 ( ρ, p X ) ≥ 1 , th e last term i n (41) is minim ized at z ∗ 0 = 0 , which gi ves E (0) F c ≥ max 0 ≤ ρ ≤ 1 − ρ R r o (1 − r o ) + 1 − r o 1 + r o . (42) The right h and side of (42) is maximized at ρ ∗ = 0 . Ho wever , ρ = 0 implies (1 + r o ) E 0 ( ρ, p X ) = 0 < 1 which contradicts the assumption (1 + r o ) E 0 ( ρ, p X ) ≥ 1 . There fore, we ca n assume that (1 + r o ) E 0 ( ρ, p X ) ≤ 18 1 . Consequently , the last term in (41) is minimized at z ∗ 0 = 1 − (1 + r o ) E 0 . This gives E (0) F c ≥ max 0 ≤ ρ ≤ 1 (1 − r o ) − ρ R r o + E 0 ( ρ, p X ) 1 − 1 + r o 2 E 0 ( ρ, p X ) . (43) By opti mizing (43) over p X and r o , it can be seen that the error e xponent given i n (6) is achiev able if we fi rst take N o to i nfinity and then take N i to infinity . Part I V : T o achiev e l inear cod ing complexity , l et us assu me that N i is fix ed at a large const ant while N o is taken to infinity . According t o [7], it is easy t o see that the encoding com plexity i s linear in the nu mber of transm itted symbo ls 3 . A t the receiver , we keep at mos t 2 N i symbols for each inner code and drop th e extra recei ved symbols. Consequently , the effecti ve codew ord length parameter of an y inner code is u pper- bounded by 2 . Because (38) and (40) are both min imized at γ ∗ = 1 − r o 2 , according to (36), the em pirical density function f Z ( z ) that mi nimizes the error exponent bound t akes t he form f Z ( z ) = 1 − r o 2 δ ( z − z 0 ) + 1+ r o 2 δ z − 2 − z 0 (1 − r o ) 1+ r o , with z 0 , 2 − z 0 (1 − r o ) 1+ r o < 2 . Therefore, upper boundi ng the ef fectiv e codew ord length parameter by 2 does not change the error exponent result. Howe ver , wi th z k ≤ 2 , ∀ k , the decoding complexity of any inner code is up per -bounded by a constant in the order of O (exp(2 N i )) . According t o [8], the overall decoding comp lexity of the concatenated code is therefore linear in N o , and hence is linear in N . Since fixing N i causes a reduction of ζ 1 > 0 in t he achiev able error e xponent, and ζ 1 can be m ade arbitrarily small as we increase N i , we concl ude that fountain error exponent E F c ( R ) given in (6) can be arbitrarily appr oached by one-level concatenated fountain codes with a linear coding comp lexity . B. Pr oof of Cor ollary 1 Pr oof : Because 0 ≤ r o ≤ 1 , it is easy to see ˜ E F c ( R ) ≤ E F c ( R ) ≤ E c ( R ) . W e will next prove lim R →C F ˜ E F c ( R ) E F c ( R ) = 1 . Define g ( p X , r o , ρ ) = (1 − r o ) − ρ R r o + E 0 ( ρ, p X ) h 1 − 1+ r o 2 E 0 ( ρ, p X ) i , such that E F c ( R ) = max p X , R C F ≤ r o ≤ 1 , 0 ≤ ρ ≤ 1 g ( p X , r o , ρ ) . (44) Using T aylor’ s expansion to expand g ( p X , r o , ρ ) at r o = 1 and ρ = 0 , we get g ( p X , r o , ρ ) = X i,j 1 ( i + j )! β ( i, j )( r o − 1) i ρ j , (45) 3 In other words, we assume that no encoding complexity is spent on codew ord symbols that are not transmitted. 19 where β ( i, j ) = ∂ ( i + j ) g ( p X ,r o ,ρ ) ∂ r i o ∂ ρ j r o =1 ,ρ =0 , with i and j being nonnegative integers. It can be verified that β ( i, j ) = 0 if i = 0 or j = 0 . W e also ha ve β (1 , 1) = ( R r 2 o − ∂ E 0 ( ρ, p X ) ∂ ρ + 2 r o E 0 ( ρ, p X ) ∂ E 0 ( ρ, p X ) ∂ ρ ) r o =1 ,ρ =0 = R − C F , β (2 , 1) = − 2 R 6 = 0 , β (1 , 2) = − ∂ 2 E 0 ( ρ, p X ) ∂ ρ 2 − 2 ∂ E 0 ( ρ, p X ) ∂ ρ ! 2 ρ =0 6 = 0 . (46) Similarly , define ˜ g ( p X , r o , ρ ) = (1 − r o ) − ρ R r o + E 0 ( ρ, p X ) [1 − E 0 ( ρ, p X )] , su ch that ˜ E F c ( R ) = max p X , R C F ≤ r o ≤ 1 , 0 ≤ ρ ≤ 1 ˜ g ( p X , r o , ρ ) . (47) Using T aylor’ s expansion to expand ˜ g ( p X , r o , ρ ) at r o = 1 and ρ = 0 , we get ˜ g ( p X , r o , ρ ) = X i,j 1 ( i + j )! ˜ β ( i, j )( r o − 1) i ρ j . ( 48) where ˜ β ( i, j ) = ∂ ( i + j ) ˜ g ( p X ,r o ,ρ ) ∂ r i o ∂ ρ j r o =1 ,ρ =0 . Similarly , we hav e ˜ β ( i, j ) = 0 if i = 0 or j = 0 and ˜ β (1 , 1) = β (1 , 1) = R − C F , ˜ β (2 , 1) = β (2 , 1) 6 = 0 , ˜ β (1 , 2) = β (1 , 2) 6 = 0 . By L ’ Hospital’ s rule, the following equality holds, lim R →C F ˜ E F c ( R ) E F c ( R ) = lim R →C F ,r o → 1 ,ρ → 0 1 2 ˜ β (1 , 1)( r o − 1) ρ + 1 6 ˜ β (2 , 1)( r o − 1) 2 ρ + 1 6 ˜ β (1 , 2)( r o − 1) ρ 2 1 2 β (1 , 1)( r o − 1) ρ + 1 6 β (2 , 1)( r o − 1) 2 ρ + 1 6 β (1 , 2)( r o − 1) ρ 2 = 1 . (49) C. Proof of The or em 4 Pr oof : Define ˆ g ( γ , r o , ρ ) = (1 − r o ) ρI ( p X ) 1 − γ r o + ρ 2 2 ∂ 2 E 0 ( ρ, p X ) ∂ ρ 2 ρ =0 − 2 I 2 ( p X ) , ˆ E F c ( γ , p X , r o ) = max 0 ≤ ρ ≤ 1 ˆ g ( γ , r o , ρ ) , ˆ E F c ( γ , p X ) = max 0 ≤ r o ≤ 1 ˆ E F c ( γ , p X , r o ) . (50) W e will first prove that lim γ → 1 E F cs ( γ , p X ) ˆ E F c ( γ , p X ) = 1 . (51) Note that ˆ g ( γ , r o , ρ ) is maxi mized at ρ ∗ = I ( p X ) ( 1 − γ r o ) − ∂ 2 E 0 ( ρ,p X ) ∂ ρ 2 ρ =0 +2 I 2 ( p X ) , where we ha ve assu med th at 0 ≤ ρ ∗ ≤ 1 . This assumpt ion is v alid when r o is also optim ized. Consequently , ˆ E F c ( γ , p X , r o ) is maximi zed at r ∗ o = arg max 0 ≤ r o ≤ 1 (1 − r o ) 1 − γ r o 2 = √ γ 2 +8 γ − γ 2 . Therefore, lim γ → 1 E F cs ( γ , p X ) ˆ E F c ( γ , p X ) ≥ lim γ → 1 " E F cs ( γ , p X , ρ ) ˆ g ( γ , p X , ρ, r o ) ρ = ρ ∗ ,r o = r ∗ o = 1 . (52) 20 Follo wing a similar id ea a s the proof of C orollary 1, it can be shown that lim γ → 1 ˆ E F c ( γ , p X ) E F c ( γ , p X ) = 1 . (53) Combining ( 52) and (53 ), we get lim γ → 1 E F cs ( γ , p X ) E F c ( γ , p X ) = lim γ → 1 E F cs ( γ , p X ) ˆ E F c ( γ , p X ) lim γ → 1 ˆ E F c ( γ , p X ) E F c ( γ , p X ) ≥ 1 . (54) Because E F cs ( γ , p X ) ≤ E F c ( γ , p X ) , (54 ) implies lim γ → 1 E F cs ( γ ,p X ) E F c ( γ ,p X ) = 1 . R E F E R E N C E S [1] Z . W ang and J. Luo, C oncatenated F ountain Codes, IEEE ISIT’09, Seoul, K orea, Jun. 2009. [2] J. Byers, M. Luby and A. Rege, A Digital F ountain Appr oach to R eliable Distribution of Bulk Data , A CM S IGCOMM’98, V ancouver , Canada, S ep. 1998. [3] M. Luby , LT codes , IEEE FOCS’02, V ancou ver , Canada , Nov . 2002. [4] A. S hokrollahi, Raptor Codes , IEE E Trans. Infom. Theory , V ol. 52, pp. 2551-2567, Jun. 2006. [5] O. Et esami and A. Shokrollahi, Raptor Codes on Bi nary Memoryless Symmetric Channels , IEEE T rans. Inform. Theory , V ol. 52, pp. 2033-205 1, May 2006. [6] S . Shamai, I. T eletar and S. V erd ´ u, F ountain Capacity , IEEE Tran s. Inform. Theory , V ol. 53, pp. 4327-4376, Nov . 2007. [7] V . Guruswami and P . Indyk, L inear-T ime Encodable/Decod able Codes W i th Near-Optimal Rate , IEEE Trans. Inform. Theory , V ol. 51, pp. 3393-3400, Oct. 2005. [8] Z . W ang and J. Luo, Appro aching Blokh-Zyablov Err or Exponent with L inear-T ime Encodable/Decod able Codes , IEEE Communications Letters, V ol. 13, pp. 438-440, Jun. 2009. [9] A. F einstein, E rr or Bounds in Noisy Channels W ithout Memory , IEEE Tran s. Inform. Theory , V ol. 1, pp. 13-14, Sep. 1955. [10] R. Gall ager , A Simple Derivation of The Coding Theor em and Some Applications , IEEE Trans. Inform. Theory , V ol. 11, pp. 3-18, Jan. 1965. [11] C. Shannon, R. Gallager, and E. Berlekamp, Lower Bounds to Error P r obability for Coding on Di scr ete Memoryless Channels, Information and Control, V ol. 10, pp. 65-10 3, 522-552, 1967. [12] G. Forney , Concatenated Codes , The MIT Press, 1966. [13] E. B lokh and V . Zyablov , Linear Concatenated Codes , Nauka, Mosco w , 1982 (In Russian). [14] A. Barg, G. Forney , Random Codes: Minimum Distances and Error Exponents , IE EE T rans. Inform. Theory V ol. 48, pp. 2568-2573, Sep. 2002. [15] A. Barg and G. Z ´ emor , Multilevel Expander Codes , Algebraic Coding Theory and Information T heory , American Math. Soc. V ol. 68, AMS-DIMA CS series, pp. 69-83, 2005. [16] D. Romik, “Stir ling’ s Approximation for n!: The Ultimate S hort Proof, ” The American Mathematical Monthly , V ol. 107, pp. 556-557, Jun.-Jul. 2000. 21 Channel Erasure Encoder Decoder w x w 1 , x w 2 , … y w 1 , y w 2 , … y wi 1 , y wi 2 , … w Fig. 1. Fountain communication ove r a memoryless channel. w …, x 22 , x 21 …, x 12 , x 1 1 1 2 Inner codewords Outer codeword Message Encoded symbols Random switch …, x N o 2 , x N o 1 N o Fig. 2. One-le vel concatenated fountain codes. 22 0.14 0.1 0.12 p onent Fountain error exponent Upper bound (Forney’ s exponent) Lower bound 0.06 0.08 n tain error ex p 0.02 0.04 Fou n 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0 Fountain rate R Fig. 3. Comparison of fountain error exponen t E F c ( R ) , its upper bound E c ( R ) , and its lo wer bound ˜ E F c ( R ) . 0.16 l i l l f i 0 1 0.12 0.14 p onent Mu l t il eve l f ounta i n error exponent Blokh-Zyablov exponent 0.06 0.08 0 . 1 n tain error ex p 0.02 0.04 Fou n 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0 Fountain rate R Fig. 4. Comparison of mulit- lev el fountain error expone nt E ( ∞ ) F c ( R ) and the B lokh-Zyablo v exponent E ( ∞ ) c ( R ) . 23 1 1 12 L 1 L 2 w 1 w L …, x 22 , x 21 …, x 12 , x 1 1 Outer codewords Random switch Encoded symbols Inner codewords 1 N o LN o …, x N o 2 , x N o 1 Outer codewords Encoded symbols Inner codewords Fig. 5. Concatenated f ountain codes for rate compatible communication. 0.014 0.01 0.012 xponent E Fc ( , p X ) E Fcs ( , p X ) 0.006 0.008 o untain error e 0.002 0.004 F o 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 Normalized fountain rate Fig. 6. Error expo nents achiev ed by optimal r o and suboptimal r o = √ γ 2 +8 γ − γ 2 versus normalized fountain r ate γ .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment