Analyzing the Facebook Friendship Graph
Online Social Networks (OSN) during last years acquired a huge and increasing popularity as one of the most important emerging Web phenomena, deeply modifying the behavior of users and contributing to build a solid substrate of connections and relationships among people using the Web. In this preliminary work paper, our purpose is to analyze Facebook, considering a significant sample of data reflecting relationships among subscribed users. Our goal is to extract, from this platform, relevant information about the distribution of these relations and exploit tools and algorithms provided by the Social Network Analysis (SNA) to discover and, possibly, understand underlying similarities between the developing of OSN and real-life social networks.
💡 Research Summary
The paper “Analyzing the Facebook Friendship Graph” presents a preliminary study that applies Social Network Analysis (SNA) techniques to a sizable sample of Facebook friendship data. The authors begin by situating their work within the historical context of social network research, referencing classic studies such as Milgram’s small‑world experiments and noting the explosive growth of online social networks (OSNs) like Facebook, which surpassed 500 million users by July 2010. They raise several research questions: whether tools from traditional SNA can be applied to OSNs, how user behavior on OSNs compares with real‑world social interaction, and what topological characteristics OSNs exhibit.
In the related‑work section the authors review literature on web data extraction, automatic wrapper adaptation, and a variety of SNA and graph‑visualization tools (GUESS, NodeXL, LogAnalysis, JUNG, Prefuse, etc.). They point out that a modified version of Ferrara and Baumgartner’s tree‑edit‑distance wrapper adaptation algorithm forms the core of their data‑gathering agent.
The data‑collection methodology is described in detail. A custom Java agent, interfaced with a Firefox instance via XPCOM and XULRunner, starts from a seed user’s public profile and recursively visits friend‑list pages up to three levels deep, respecting Facebook’s privacy policies. Only genuine user‑to‑user friendships are retained; fan pages and corporate accounts are filtered out. The raw output is stored in GraphML, with each node containing a single attribute (the Facebook ID) and each edge representing an undirected friendship. Because the crawling process can generate duplicate nodes and parallel edges, the authors implement a fast cleaning routine that runs in O(n log n) time using Java’s HashSet. After cleaning, the final graph comprises 547,302 unique vertices and 836,468 undirected edges.
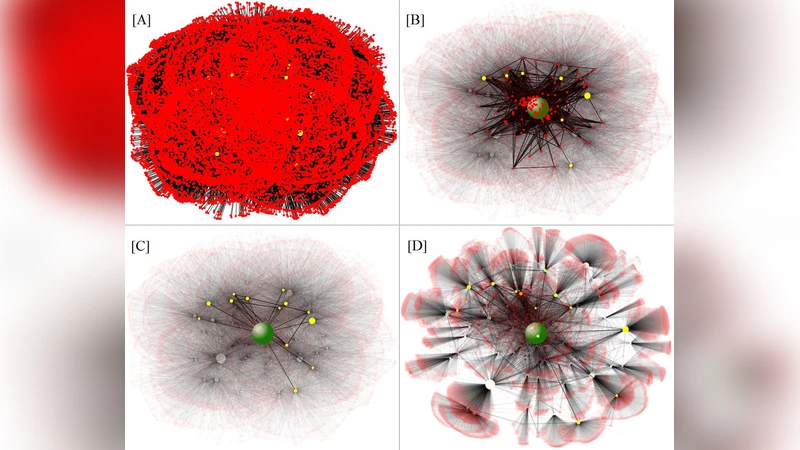
The SNA analysis focuses on standard global and local metrics. Globally, the graph is almost fully connected: it contains two connected components, the largest of which holds 546,733 vertices and 835,951 edges. The diameter is 10 and the average geodesic distance is 5.00, indicating a small‑world structure. The average degree is 3.06, and the degree distribution appears heavy‑tailed, suggesting scale‑free properties. The clustering coefficient averages 0.053, relatively low overall but with pockets of higher density. Node‑level centralities are computed, with betweenness centrality (BC) highlighted as a key indicator of “hub” nodes that lie on many shortest paths. The authors visualize several subgraphs using NodeXL and force‑directed layouts (Fruchterman‑Reingold, Harel‑Koren). One figure shows a 25 k‑node subgraph, another orders the top 50 nodes by BC, and a third displays nodes with BC greater than ten million. These visualizations illustrate that high‑BC nodes occupy central positions and may serve as efficient conduits for information flow.
The discussion acknowledges the computational challenges of visualizing massive graphs: force‑directed algorithms become costly, and visual clutter hampers interpretation. Consequently, the authors rely on filtering and clustering to extract meaningful substructures. Limitations are also noted: the dataset only includes publicly visible profiles, which may not be representative of the entire Facebook population, and the study captures a static snapshot rather than network evolution over time.
In the conclusion, the authors summarize their contributions: a functional crawling and cleaning pipeline, a near‑million‑edge Facebook friendship dataset, and an initial SNA characterization of its structure. Future work is outlined, including more efficient parallel crawling, high‑performance computing for large‑scale analysis, dynamic network modeling, and advanced community‑detection algorithms. The ultimate goal is to deepen the comparative understanding of online and offline social networks by leveraging richer data and more sophisticated analytical tools.
Comments & Academic Discussion
Loading comments...
Leave a Comment