Crawling Facebook for Social Network Analysis Purposes
We describe our work in the collection and analysis of massive data describing the connections between participants to online social networks. Alternative approaches to social network data collection are defined and evaluated in practice, against the popular Facebook Web site. Thanks to our ad-hoc, privacy-compliant crawlers, two large samples, comprising millions of connections, have been collected; the data is anonymous and organized as an undirected graph. We describe a set of tools that we developed to analyze specific properties of such social-network graphs, i.e., among others, degree distribution, centrality measures, scaling laws and distribution of friendship.
💡 Research Summary
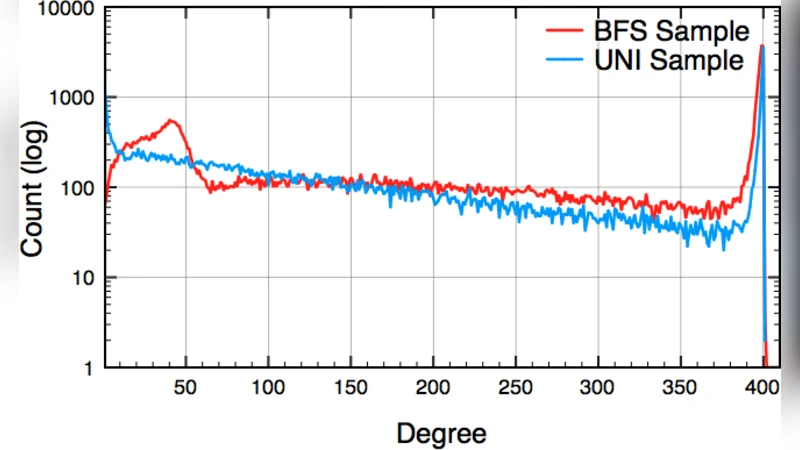
The paper “Crawling Facebook for Social Network Analysis Purposes” presents a comprehensive methodology for collecting and analyzing massive friendship data from Facebook while respecting privacy constraints. The authors first motivate the need for large‑scale social network data, noting that full acquisition of Facebook’s graph would require terabytes of storage and prohibitive computational resources. Consequently, they focus on two sampling strategies that can produce representative sub‑graphs: a breadth‑first search (BFS) crawler and a uniform random‑ID crawler.
The BFS approach starts from a single seed user, explores friends, friends‑of‑friends, and friends‑of‑friends‑of‑friends (three friendship levels), and terminates after 240 hours (10 days) or when the three‑level depth is reached. The crawler maintains a FIFO “ToBeVisited” queue, logs into Facebook using authenticated cookies, fetches the friend‑list page, parses the HTML with regular expressions, and enqueues newly discovered user IDs. The authors acknowledge the well‑documented bias of incomplete BFS toward high‑degree nodes (Kurant et al.) but argue that their limited depth and runtime mitigate the effect sufficiently for local community analysis.
The uniform sampling method exploits Facebook’s 32‑bit user‑ID space. Random IDs are generated uniformly in the range
Comments & Academic Discussion
Loading comments...
Leave a Comment