High Quality of Service on Video Streaming in P2P Networks using FST-MDC
Video streaming applications have newly attracted a large number of participants in a distribution network. Traditional client-server based video streaming solutions sustain precious bandwidth provision rate on the server. Recently, several P2P streaming systems have been organized to provide on-demand and live video streaming services on the wireless network at reduced server cost. Peer-to-Peer (P2P) computing is a new pattern to construct disseminated network applications. Typical error control techniques are not very well matched and on the other hand error prone channels has increased greatly for video transmission e.g., over wireless networks and IP. These two facts united together provided the essential motivation for the development of a new set of techniques (error concealment) capable of dealing with transmission errors in video systems. In this paper, we propose an flexible multiple description coding method named as Flexible Spatial-Temporal (FST) which improves error resilience in the sense of frame loss possibilities over independent paths. It introduces combination of both spatial and temporal concealment technique at the receiver and to conceal the lost frames more effectively. Experimental results show that, proposed approach attains reasonable quality of video performance over P2P wireless network.
💡 Research Summary
The paper addresses the persistent challenge of delivering high‑quality video over peer‑to‑peer (P2P) networks, especially in wireless environments where packet loss, delay, and bandwidth constraints are common. Traditional client‑server streaming suffers from a single point of congestion at the server, while conventional error‑control mechanisms such as ARQ and FEC either introduce unacceptable latency or require excessive redundancy. To overcome these limitations, the authors propose a Flexible Spatial‑Temporal (FST) multiple‑description coding (MDC) scheme that combines both spatial and temporal error concealment techniques at the receiver.
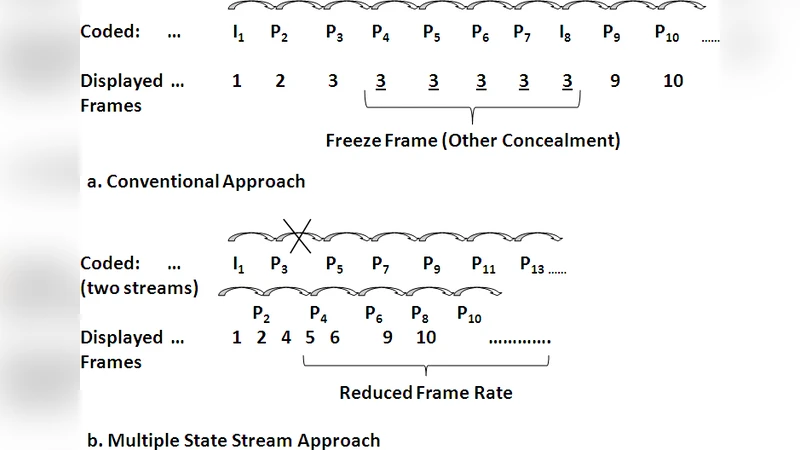
The core idea of the proposed system is to split the original video sequence into two independent sub‑streams: one containing the even‑indexed frames and the other the odd‑indexed frames. Each sub‑stream is encoded as a separate “description” with its own prediction loop and state information. By transmitting the two descriptions over disjoint P2P paths, the probability that both streams are simultaneously corrupted is dramatically reduced. When both descriptions arrive intact, the decoder simply interleaves them to reconstruct the original frame rate. When only one description is received, the decoder activates the FST concealment module.
The FST concealment module works in three stages. First, a temporal concealment step uses previously decoded frames (and, when available, future frames) to estimate motion vectors and generate a temporally interpolated version of the missing frames. Second, a spatial concealment step refines the temporally interpolated frame by exploiting spatial continuity within the current frame—essentially performing edge‑aware interpolation from neighboring correctly decoded macro‑blocks. Finally, a hybrid optimization combines a spatial‑temporal smoothness cost function to select the best pixel values, thereby minimizing visual artifacts such as blocking or flickering. This hybrid approach allows the system to retain half the original frame rate (e.g., 30 fps → 15 fps) while preserving acceptable visual quality, and it also enables state recovery for the lost description using information from the correctly received stream.
Experimental validation was performed on standard test sequences (e.g., “Foreman”, “Mobile”) under simulated P2P wireless conditions with packet loss rates ranging from 5 % to 20 %. Objective metrics (PSNR, SSIM) and subjective Mean Opinion Scores (MOS) were collected. The results show that when both descriptions are present, the proposed method matches the quality of conventional single‑state codecs. When a single description is lost, the FST scheme yields an average PSNR improvement of 3–5 dB and an SSIM increase of 0.02–0.04 compared with baseline single‑state error concealment. Even at a 15 % loss rate, video playback remains continuous, and MOS scores stay above 3.5, indicating satisfactory user experience.
The authors conclude that the FST‑MDC approach provides a practical balance between error resilience and bandwidth efficiency for P2P video streaming. However, they acknowledge several limitations: the experiments were conducted in simulation rather than on real mobile devices; the redundancy overhead introduced by the two descriptions was not quantitatively analyzed; and the performance under rapid scene cuts or high‑motion content was not thoroughly examined. Future work is suggested to include real‑world deployment, adaptive redundancy control, and more sophisticated handling of complex motion patterns.
In summary, the paper contributes a novel hybrid error concealment framework that leverages the inherent redundancy of multiple‑description coding and the complementary strengths of spatial and temporal interpolation. It demonstrates measurable gains in video quality under realistic P2P loss conditions, offering a promising direction for robust, low‑cost video distribution over decentralized networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment