Coarse-Grained Topology Estimation via Graph Sampling
Many online networks are measured and studied via sampling techniques, which typically collect a relatively small fraction of nodes and their associated edges. Past work in this area has primarily focused on obtaining a representative sample of nodes and on efficient estimation of local graph properties (such as node degree distribution or any node attribute) based on that sample. However, less is known about estimating the global topology of the underlying graph. In this paper, we show how to efficiently estimate the coarse-grained topology of a graph from a probability sample of nodes. In particular, we consider that nodes are partitioned into categories (e.g., countries or work/study places in OSNs), which naturally defines a weighted category graph. We are interested in estimating (i) the size of categories and (ii) the probability that nodes from two different categories are connected. For each of the above, we develop a family of estimators for design-based inference under uniform or non-uniform sampling, employing either of two measurement strategies: induced subgraph sampling, which relies only on information about the sampled nodes; and star sampling, which also exploits category information about the neighbors of sampled nodes. We prove consistency of these estimators and evaluate their efficiency via simulation on fully known graphs. We also apply our methodology to a sample of Facebook users to obtain a number of category graphs, such as the college friendship graph and the country friendship graph; we share and visualize the resulting data at www.geosocialmap.com.
💡 Research Summary
The paper addresses the problem of inferring a coarse‑grained, category‑level view of a large online network when only a small probability sample of nodes is available. The authors assume that the vertex set V of an undirected graph G = (V, E) can be partitioned into a finite set of categories C (e.g., countries, colleges). From this partition they define a “category graph” G_C = (C, E_C) whose nodes are the categories and whose edge weight w(A, B) is the probability that a uniformly chosen node from category A is adjacent to a uniformly chosen node from category B. Formally, w(A, B) = |E_{A,B}| / (|A|·|B|), where E_{A,B} is the set of edges crossing the two categories.
Because the full graph G is typically inaccessible, the goal is to estimate both the category sizes |A| and the inter‑category edge weights w(A, B) from a sampled subset S ⊆ V. The authors consider two observation models:
- Induced subgraph sampling – only the categories of sampled nodes are known, and edges are observed only among sampled nodes.
- Star sampling – when a node is sampled, the categories of all its neighbors are also observed (the neighbor identities or degrees are not required). This model reflects common practices such as HTML scraping of OSN profiles.
Both uniform independent sampling (UIS) and weighted independent sampling (WIS) are treated. For each combination of sampling design and observation model, the paper derives design‑based estimators that are provably consistent (i.e., converge to the true values as the sample size grows).
Category‑size estimators
- Under UIS with induced subgraph sampling, the trivial estimator is |Â| = N·|S_A|/|S|, where N = |V| and S_A is the multiset of sampled nodes belonging to A.
- Under UIS with star sampling, the estimator exploits average degrees: let k_A be the average degree within A and k_V the overall average degree. Since vol(A) = |A|·k_A, the relative volume f_vol(A) = vol(A)/vol(V) can be estimated from the star data, and |Â| = N·f̂_vol(A)·(k̂_V/k̂_A). The required quantities k̂_A and k̂_V are obtained directly from the sampled degrees, while f̂_vol(A) is estimated by counting, for each sampled node, how many of its neighbors belong to A.
Edge‑weight estimators
- For induced subgraph sampling, ŵ(A, B) = (∑{a∈S_A}∑{b∈S_B} 1_{ {a,b}∈E }) / (|S_A|·|S_B|).
- For star sampling, the numerator aggregates all observed cross‑category edges from sampled nodes in A to any neighbor in B and vice‑versa. The denominator uses the estimated category sizes: ŵ(A, B) = (∑{a∈S_A}|E{a,B}| + ∑{b∈S_B}|E{b,A}|) / (|S_A|·|̂B| + |S_B|·|̂A|).
All estimators are shown to be unbiased (asymptotically) and to have decreasing variance with larger samples. The paper also discusses how to estimate the total population size N when it is unknown, using a “reverse coupon collector” approach.
Experimental evaluation
Simulations on synthetic graphs (Erdős‑Rényi, scale‑free) and on fully observed empirical networks demonstrate that star‑sampling estimators consistently achieve lower mean‑squared error than their induced‑subgraph counterparts, especially in dense graphs where average degree is high. The advantage stems from the fact that star sampling leverages many more edge observations (including edges to unsampled neighbors) while induced subgraph sampling relies only on the relatively few edges among sampled nodes. The authors also evaluate non‑uniform sampling (WIS) and show that appropriate weighting restores consistency.
Real‑world application
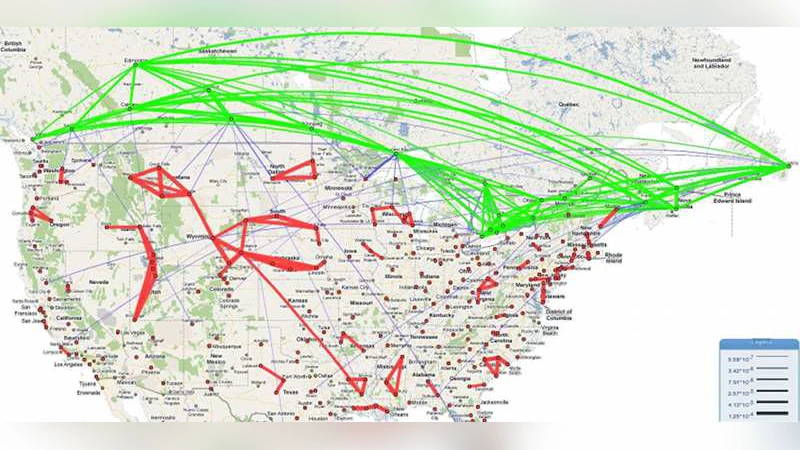
A sample of several hundred thousand Facebook users was collected via API crawling. Users’ declared colleges and countries provide the categorical partition. Using the proposed estimators, the authors construct:
- A “college friendship graph” where nodes are colleges and edge weights reflect the probability that a random student from one college is friends with a random student from another.
- A “country friendship graph” with analogous interpretation at the national level.
These graphs are made publicly available and visualized through an interactive web portal (geosocialmap.com), enabling researchers and the public to explore inter‑institutional and international connectivity patterns.
Contributions and impact
The work fills a gap between local‑property estimation (degree distribution, clustering) and full‑graph reconstruction by providing a principled framework for estimating coarse‑grained topology from limited samples. The dual observation models capture realistic data‑collection scenarios, and the design‑based estimators are simple to compute yet theoretically sound. By validating the methods on both synthetic and real OSN data, the paper demonstrates practical feasibility and opens avenues for sociological, marketing, and policy analyses that require only category‑level network information without exhaustive graph crawling.
Comments & Academic Discussion
Loading comments...
Leave a Comment