Community structure of complex software systems: Analysis and applications
Due to notable discoveries in the fast evolving field of complex networks, recent research in software engineering has also focused on representing software systems with networks. Previous work has observed that these networks follow scale-free degree distributions and reveal small-world phenomena, while we here explore another property commonly found in different complex networks, i.e. community structure. We adopt class dependency networks, where nodes represent software classes and edges represent dependencies among them, and show that these networks reveal a significant community structure, characterized by similar properties as observed in other complex networks. However, although intuitive and anticipated by different phenomena, identified communities do not exactly correspond to software packages. We empirically confirm our observations on several networks constructed from Java and various third party libraries, and propose different applications of community detection to software engineering.
💡 Research Summary
The paper investigates the presence and characteristics of community structure in software systems by modeling them as class‑dependency networks. Each node in the undirected multigraph represents a Java class, and edges capture four types of dependencies: inheritance, field, parameter, and return relationships. Eight diverse Java‑based projects (JUnit, JavaMail, Flamingo, JUNG, Colt, org, javax, and the core java library) are parsed from their JAR files, yielding networks ranging from 128 to 2 581 nodes and from 470 to 34 858 edges.
To uncover community structure, three well‑known detection algorithms are employed: Edge Betweenness (EB), Modularity Optimization (MO, a greedy Louvain‑style method), and Label Propagation (LP). The authors do not aim to compare algorithmic performance; instead, they assess the stability and significance of the resulting partitions using two standard metrics. Modularity Q quantifies how many more intra‑community edges exist than expected under a configuration‑model null graph, while Normalized Mutual Information (NMI) measures the similarity between the detected communities and the actual software packages defined by developers.
Results show that, for all networks except the dense core java library, the algorithms achieve high modularity values (Q ≈ 0.55–0.77). Values above 0.30 are widely accepted as evidence of meaningful community structure, indicating that class‑dependency graphs possess a pronounced modular organization far stronger than random graphs with the same degree distribution. The core java library, with a much higher average degree, appears overly dense; consequently, its modularity is lower (Q ≈ 0.46), reflecting a less modular internal architecture.
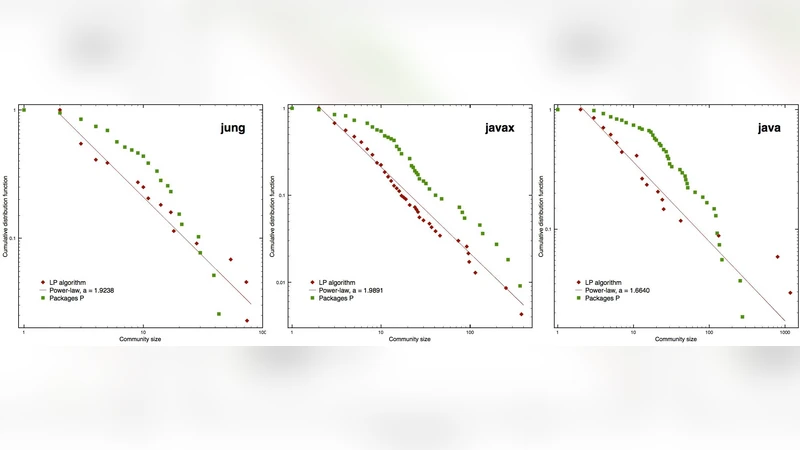
Community size distributions, examined via the LP algorithm, follow an approximate power‑law P(s) ∝ s⁻ᵅ with exponent α ≈ 2 for the JUNG, javax, and java networks. This scaling mirrors observations in many complex networks, suggesting that software systems share universal structural patterns beyond degree distributions and small‑world effects. In contrast, the size distribution of developer‑defined packages does not follow a power‑law, often resembling log‑normal shapes, underscoring a mismatch between design‑level grouping and emergent network modules.
The NMI analysis reveals modest alignment between detected communities and actual packages, with values ranging from about 0.09 to 0.35. While some high‑level packages (e.g., JUNG’s visualization, algorithms, graph, and io modules) are reflected in the community partition, finer‑grained package boundaries are frequently split across multiple communities or merged together. This discrepancy indicates that developers’ package decisions are influenced by factors other than pure class‑level dependencies, such as logical cohesion, historical evolution, or API exposure considerations.
The authors discuss several practical implications of these findings. First, community detection can guide automated refactoring: by reorganizing classes into modules that correspond to tightly‑connected communities, one can achieve higher internal cohesion and lower external coupling, adhering to classic modularity principles. Second, because defects tend to propagate along dense dependency paths, community boundaries may serve as natural fault‑localization zones, informing test‑suite prioritization and impact analysis. Third, tracking the evolution of community structure over successive releases could provide early warnings of architectural decay, as declining modularity or fragmentation of previously cohesive communities may signal design erosion.
In conclusion, the study demonstrates that software systems, when represented as class‑dependency networks, exhibit robust community structure comparable to other complex systems. However, this emergent modularity does not perfectly align with conventional package hierarchies, opening avenues for using network‑based analyses to improve software architecture, maintenance, and evolution. Future work is suggested to incorporate dynamic execution traces, explore multi‑level community detection, and validate the approach on large‑scale industrial codebases.
Comments & Academic Discussion
Loading comments...
Leave a Comment