Social content matching in MapReduce
Matching problems are ubiquitous. They occur in economic markets, labor markets, internet advertising, and elsewhere. In this paper we focus on an application of matching for social media. Our goal is to distribute content from information suppliers to information consumers. We seek to maximize the overall relevance of the matched content from suppliers to consumers while regulating the overall activity, e.g., ensuring that no consumer is overwhelmed with data and that all suppliers have chances to deliver their content. We propose two matching algorithms, GreedyMR and StackMR, geared for the MapReduce paradigm. Both algorithms have provable approximation guarantees, and in practice they produce high-quality solutions. While both algorithms scale extremely well, we can show that StackMR requires only a poly-logarithmic number of MapReduce steps, making it an attractive option for applications with very large datasets. We experimentally show the trade-offs between quality and efficiency of our solutions on two large datasets coming from real-world social-media web sites.
💡 Research Summary
The paper addresses the problem of distributing social‑media content from producers (items) to consumers (users) in a way that maximizes overall relevance while respecting per‑item and per‑user activity limits. Formally, the authors model the scenario as a weighted b‑matching problem on a bipartite graph G = (T, C, E), where T is the set of items, C the set of consumers, each edge (t, c) carries a relevance weight w(t,c) > 0, and each vertex v has a capacity b(v) that limits how many incident edges may be selected. The goal is to find a subset of edges (a b‑matching) of maximum total weight subject to the capacity constraints.
Exact solutions via maximum‑flow techniques run in Õ(n·m) time, which is prohibitive for the massive graphs typical of modern social platforms. Consequently, the authors develop two scalable approximation algorithms that fit the MapReduce programming model: GreedyMR and StackMR.
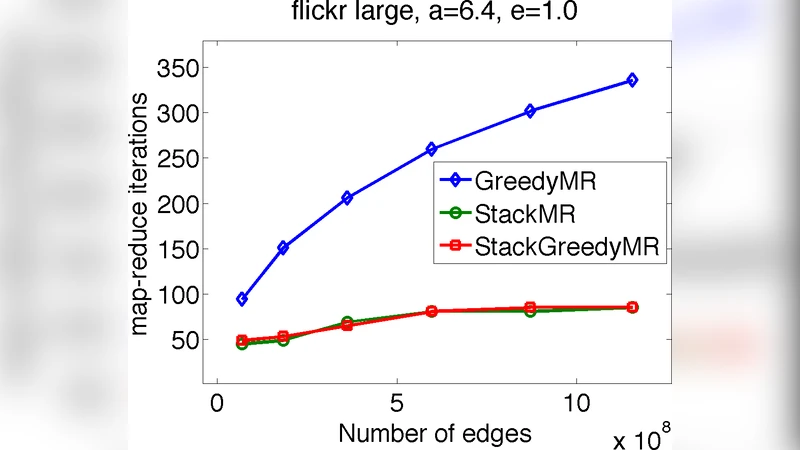
GreedyMR adapts the classic greedy algorithm for weighted b‑matching to the MapReduce paradigm. In each map phase edges are emitted keyed by their weight; the shuffle groups edges of similar weight, and reducers process them in descending order, adding an edge to the matching if both its endpoints still have remaining capacity. This simple scheme yields a 1/2‑approximation guarantee and can be stopped at any iteration, returning the best solution found so far. Empirically, GreedyMR converges after only a few rounds (typically 3–5) on real data and often outperforms StackMR in total weight, achieving about 10–20 % higher objective values. Its main drawback is that, in the worst case, it may require a linear number of MapReduce rounds, which is theoretically less attractive.
StackMR is inspired by distributed matching algorithms that use a “stack” data structure to process high‑weight edges first while allowing a controlled violation of capacities. The algorithm permits each vertex to exceed its capacity by a factor of (1 + ε) and guarantees a (6 + ε)‑approximation to the optimal weighted b‑matching for any ε > 0. Crucially, StackMR can be implemented with only a poly‑logarithmic number of MapReduce rounds (typically 12–18 in the experiments), making it highly scalable to graphs with hundreds of millions of edges. Although its objective value is slightly lower than GreedyMR’s, it consumes far less memory and network bandwidth because the number of communication rounds is bounded logarithmically.
Before applying either algorithm, the system must construct the candidate edge set E′, i.e., all (t, c) pairs whose relevance exceeds a threshold σ. Enumerating all |T|·|C| pairs is infeasible, so the authors adopt a similarity‑join approach based on the state‑of‑the‑art self‑join algorithm of Baraglia et al. (2010). By treating items and users as documents represented by TF‑IDF vectors, they perform a prefix‑filtering join in two MapReduce iterations, efficiently extracting only those pairs with similarity ≥ σ. This preprocessing step dramatically reduces the size of the graph fed to GreedyMR or StackMR.
The experimental evaluation uses two large, real‑world datasets: Flickr (photo sharing) and Yahoo! Answers (question‑answering). For each dataset, items are photos or questions, users are viewers or answerers, and relevance scores are computed via cosine similarity of TF‑IDF vectors (or via a learned recommendation model). Capacity constraints for users are derived from historical activity logs; item capacities are either uniform or proportional to a quality score q(t) estimated by a separate machine‑learning model.
Key findings from the experiments include:
- Scalability: StackMR processes graphs with hundreds of millions of edges in under 30 minutes using a modest Hadoop cluster, with a predictable number of rounds. GreedyMR finishes slightly faster in wall‑clock time but may need more rounds on pathological inputs.
- Solution Quality: GreedyMR consistently achieves higher total weight (≈ 1.12× the weight of StackMR) while still respecting capacities exactly. StackMR’s slight capacity violation (≤ 1 + ε) is acceptable in many practical settings.
- Resource Usage: StackMR’s bounded number of rounds leads to lower shuffle volume and memory footprint, which is advantageous when network bandwidth is a bottleneck.
- Flexibility: GreedyMR can be halted early to provide a feasible solution at any time, a useful property for real‑time recommendation pipelines.
The paper concludes that both algorithms constitute practical tools for large‑scale social‑content distribution. StackMR is preferable when strict guarantees on the number of MapReduce steps and resource consumption are required, while GreedyMR is attractive when the highest possible relevance is desired and the system can tolerate a few extra rounds. The authors suggest future work on dynamic capacities, multi‑objective extensions (e.g., diversity, fairness), and streaming updates to the matching as new content arrives.
In summary, this work delivers a complete MapReduce‑based framework for weighted b‑matching in social media, introduces two novel algorithms with provable approximation bounds, demonstrates how to efficiently generate the underlying candidate graph, and validates the approach on massive real‑world datasets, thereby bridging the gap between theoretical matching algorithms and practical, scalable recommendation systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment