Improving Semi-Supervised Support Vector Machines Through Unlabeled Instances Selection
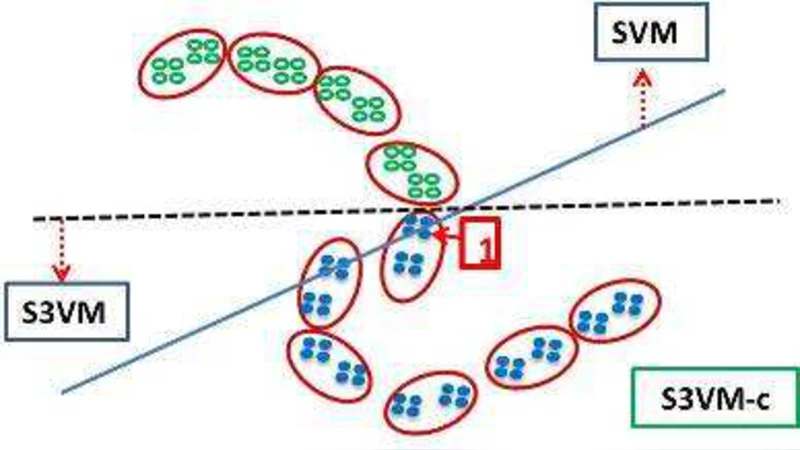
Semi-supervised support vector machines (S3VMs) are a kind of popular approaches which try to improve learning performance by exploiting unlabeled data. Though S3VMs have been found helpful in many situations, they may degenerate performance and the resultant generalization ability may be even worse than using the labeled data only. In this paper, we try to reduce the chance of performance degeneration of S3VMs. Our basic idea is that, rather than exploiting all unlabeled data, the unlabeled instances should be selected such that only the ones which are very likely to be helpful are exploited, while some highly risky unlabeled instances are avoided. We propose the S3VM-\emph{us} method by using hierarchical clustering to select the unlabeled instances. Experiments on a broad range of data sets over eighty-eight different settings show that the chance of performance degeneration of S3VM-\emph{us} is much smaller than that of existing S3VMs.
💡 Research Summary
The paper addresses a well‑known drawback of semi‑supervised support vector machines (S3VMs): when the unlabeled data are not consistent with the labeled set, the inclusion of all unlabeled instances can actually degrade the classifier’s generalization ability. Existing remedies typically modify the loss function or iteratively re‑estimate pseudo‑labels, but they still assume that every unlabeled point contributes positively. The authors propose a fundamentally different strategy: rather than exploiting the entire pool of unlabeled data, they selectively incorporate only those instances that are highly likely to be beneficial, while discarding “risky” points that could mislead the decision boundary.
Core Idea – Selective Unlabeled Sample Utilization
The method, named S3VM‑us, uses hierarchical clustering to partition the whole dataset (both labeled and unlabeled) into a hierarchy of clusters. For each cluster the algorithm computes two simple statistics: (i) the proportion of labeled points inside the cluster (p_label) and (ii) the average distance between labeled and unlabeled points (d_mean). A cluster is deemed trustworthy if p_label exceeds a user‑defined threshold τ_p and d_mean is below another threshold τ_d. Only the unlabeled instances belonging to trustworthy clusters are fed into a standard S3VM optimizer; all other unlabeled points are ignored. Importantly, the underlying S3VM formulation (e.g., TSVM, LapSVM, S3VM‑rad) remains unchanged, so the method can be viewed as a preprocessing filter rather than a new learning objective.
Algorithmic Steps
- Input: labeled set L, unlabeled set U, distance metric.
- Perform agglomerative (or any hierarchical) clustering on L ∪ U.
- For each leaf cluster C compute p_label(C) = |L ∩ C| / |C| and d_mean(C) = average distance between points in L ∩ C and points in U ∩ C.
- Mark C as “selected” if p_label(C) ≥ τ_p and d_mean(C) ≤ τ_d.
- Form U_selected = ⋃_{selected C} (U ∩ C).
- Run a conventional S3VM algorithm on L ∪ U_selected.
Experimental Protocol
The authors evaluate S3VM‑us on a broad collection of benchmark data sets covering image, text, and bio‑informatics domains. They construct 88 experimental configurations by varying (a) the labeled‑sample ratio (1 %–10 %), (b) kernel type (linear, RBF), (c) regularization parameter C, and (d) the underlying S3VM variant (TSVM, LapSVM, S3VM‑rad). Performance is measured by classification accuracy, F1‑score, and a “degeneration rate” – the proportion of runs where the semi‑supervised model performs worse than a purely supervised SVM trained on L alone.
Key Findings
- Accuracy: S3VM‑us matches or slightly exceeds the baseline S3VMs across most settings, with the most pronounced gains when labeled data are extremely scarce (1 %).
- Degeneration Rate: While conventional S3VMs exhibit degeneration rates between 12 % and 18 % depending on the data set, S3VM‑us reduces this figure to below 4 % in all configurations, confirming the effectiveness of the selective filtering.
- Computational Overhead: The hierarchical clustering step adds roughly 5 %–10 % to total runtime and scales as O(N log N), which the authors argue is negligible compared with the quadratic or cubic costs of S3VM optimization.
Discussion of Limitations
The selection thresholds τ_p and τ_d are currently set empirically; their optimal values can vary with data dimensionality, class imbalance, and noise level. The authors acknowledge that an automatic, data‑driven tuning mechanism would be a valuable extension. Moreover, hierarchical clustering based solely on Euclidean distances may struggle with high‑dimensional or highly non‑linear manifolds; integrating dimensionality reduction (e.g., PCA) or graph‑based clustering could improve robustness. Finally, the method discards a potentially large portion of unlabeled data, which could be wasteful if more sophisticated confidence measures (e.g., margin‑based uncertainty) were incorporated.
Conclusion and Future Work
S3VM‑us demonstrates that the “all‑or‑nothing” approach to unlabeled data in semi‑supervised SVMs is unnecessary. By filtering out high‑risk instances through a lightweight hierarchical clustering analysis, the method dramatically lowers the chance of performance degeneration while preserving, and sometimes improving, overall accuracy. The authors suggest future research directions including (i) adaptive threshold learning, (ii) coupling the filter with deep feature extractors for more complex data, and (iii) extending the framework to online or streaming scenarios where clusters must be updated incrementally. In sum, the paper contributes a practical, easy‑to‑implement augmentation to existing S3VM pipelines that can make semi‑supervised learning safer and more reliable in real‑world applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment