Metamorphic Virus Detection in Portable Executables Using Opcodes Statistical Feature
Metamorphic viruses engage different mutation techniques to escape from string signature based scanning. They try to change their code in new offspring so that the variants appear non-similar and have no common sequences of string as signature. However, all versions of a metamorphic virus have similar task and performance. This obfuscation process helps to keep them safe from the string based signature detection. In this study, we make use of instructions statistical features to compare the similarity of two hosted files probably occupied by two mutated forms of a specific metamorphic virus. The introduced solution in this paper is relied on static analysis and employs the frequency histogram of machine opcodes in different instances of obfuscated viruses. We use Minkowski-form histogram distance measurements in order to check the likeness of portable executables (PE). The purpose of this research is to present an idea that for a number of special obfuscation approaches the presented solution can be used to identify morphed copies of a file. Thus, it can be applied by antivirus scanner to recognize different versions of a metamorphic virus.
💡 Research Summary
The paper addresses the problem of detecting metamorphic viruses—malware that repeatedly rewrites its own code to evade signature‑based detection—by exploiting a static, low‑level feature: the frequency distribution of machine opcodes. The authors argue that, despite extensive code mutation (garbage code insertion, register/variable exchange, instruction replacement, instruction permutation, and code transposition), the overall opcode histogram of a virus family remains relatively stable because the functional semantics of the program are preserved.
The proposed detection pipeline consists of several steps. First, a Portable Executable (PE) file is disassembled (using IDA Pro) and split into its constituent sub‑routines (functions). For each sub‑routine a histogram is built that counts how many times each opcode appears; this yields a high‑dimensional vector whose length equals the number of distinct opcodes supported by the target architecture. The histograms are normalized (the paper mentions L2 or mean‑variance normalization) to reduce bias caused by differing file sizes.
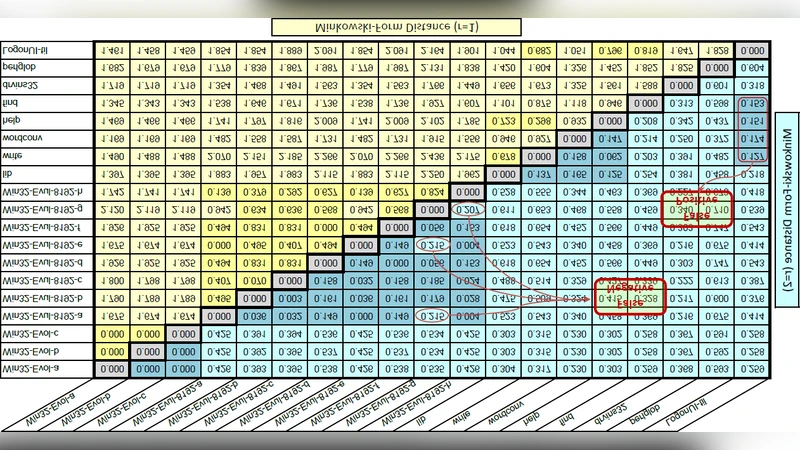
Similarity between two files, P1 and P2, is then measured by comparing every histogram of P1 with every histogram of P2 using Minkowski‑form distance metrics (Manhattan (r = 1) and Euclidean (r = 2)). For each histogram of P1 the minimum distance to any histogram of P2 is recorded; the average of these minima constitutes a directional distance d(P1,P2). Because the metric is not symmetric, the final distance is defined as the average of d(P1,P2) and d(P2,P1). If this bidirectional distance falls below a pre‑determined threshold, the two files are classified as mutated versions of the same metamorphic virus.
To evaluate the approach, the authors implemented the algorithm in MATLAB R2008a and built a modest dataset comprising two known metamorphic viruses (Win32/Evol and Win32/Evul) and a handful of legitimate programs (e.g., Microsoft Visual Studio, WordPad). Multiple obfuscated variants of each virus were generated, their opcode histograms extracted, and pairwise distances computed. The experimental results show that distances between variants of the same virus are consistently lower than distances between virus variants and benign programs, suggesting that the method can separate metamorphic families from clean software.
While the concept is straightforward and computationally inexpensive, several limitations are evident. The study assumes that opcode frequencies remain “almost equal” across mutations, yet many modern metamorphic engines deliberately replace instructions with semantically equivalent alternatives that can significantly alter the histogram. The paper provides no quantitative analysis of false‑positive/false‑negative rates, nor does it report ROC curves or statistical confidence intervals. The threshold selection is described only qualitatively, leaving open the question of how the system would adapt to diverse real‑world workloads. Moreover, the dataset is narrow; only two virus families are examined, and the benign set is small, making it difficult to assess scalability or robustness against unseen obfuscation techniques.
From an implementation perspective, the need to disassemble every PE file and generate a histogram for each sub‑routine incurs non‑trivial overhead, especially for large binaries or for environments that must scan many files in real time. The O(m × k) pairwise distance computation (where m and k are the numbers of sub‑routines in the two files) could become a bottleneck without further optimization or indexing strategies.
In conclusion, the paper contributes a novel angle to metamorphic virus detection by leveraging opcode frequency histograms and Minkowski distance metrics. It demonstrates that static opcode statistics can capture enough similarity to differentiate mutated variants of a virus from unrelated software. However, to become a practical component of modern anti‑malware solutions, the approach would need to be extended with additional features (control‑flow graphs, data‑flow analysis, or machine‑learning classifiers), validated on larger and more diverse malware corpora, and optimized for speed and low false‑positive rates. Future work should also explore adaptive thresholding and hybrid static‑dynamic schemes to improve resilience against increasingly sophisticated metamorphic engines.
Comments & Academic Discussion
Loading comments...
Leave a Comment