Recursive double-size fixed precision arithmetic
This work is a part of the SHIVA (Secured Hardware Immune Versatile Architecture) project whose purpose is to provide a programmable and reconfigurable hardware module with high level of security. We propose a recursive double-size fixed precision arithmetic called RecInt. Our work can be split in two parts. First we developped a C++ software library with performances comparable to GMP ones. Secondly our simple representation of the integers allows an implementation on FPGA. Our idea is to consider sizes that are a power of 2 and to apply doubling techniques to implement them efficiently: we design a recursive data structure where integers of size 2^k, for k>k0 can be stored as two integers of size 2^{k-1}. Obviously for k<=k0 we use machine arithmetic instead (k0 depending on the architecture).
💡 Research Summary
The paper presents “RecInt”, a recursive double‑size fixed‑precision arithmetic framework developed within the SHIVA (Secured Hardware Immune Versatile Architecture) project. The authors’ goal is to provide a programmable, reconfigurable hardware module with a high security level, suitable for cryptographic primitives such as RSA and elliptic‑curve cryptography. RecInt is based on the observation that integers whose size is a power of two can be represented recursively as two halves of half the size. Formally, for a size parameter k > k₀ (where k₀ depends on the target architecture, e.g., 5 for 32‑bit and 6 for 64‑bit machines), a RecInt
The implementation exploits C++ templates and partial specialization. The generic template defines the recursive structure and declares the high‑level arithmetic functions, while the specializations for k ≤ k₀ map directly to GMP’s limb type and its assembly‑level routines (e.g., mul_ppmm). This design yields a clean separation: small operands benefit from the full speed of native arithmetic, while large operands are automatically handled by recursive calls without manual code duplication.
Key algorithmic contributions include:
-
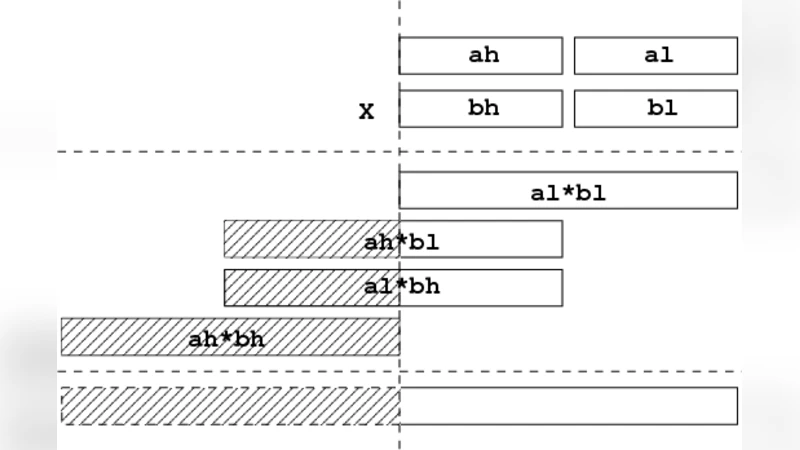
Truncated multiplication – When only the low 2ᵏ bits of a product are required (as in modular arithmetic), a level‑k multiplication can be performed with one full multiplication of the high halves and two truncated multiplications of level k‑1, instead of the naïve four full multiplications. This reduces the constant factor dramatically for fixed‑precision workloads.
-
Recursive division – The authors adopt the Burnikel‑Ziegler recursive division algorithm, which splits the problem into sub‑divisions of 2‑digit by 1‑digit and 3‑halves by 2‑halves. The resulting complexity is O(rs log 3 − 1 + r log s) for dividing an s‑digit integer by an r‑digit integer, offering a practical advantage for Euclidean and extended Euclidean algorithms on large operands.
-
Montgomery reduction – By choosing the radix R = 2^{2^k}, reduction modulo R becomes a simple extraction of the Low part, while division by R corresponds to discarding the Low part and keeping the High part. Consequently, the REDC algorithm requires only one truncated multiplication and one full multiplication, eliminating costly trial divisions in modular multiplication and exponentiation.
The software library, named “Paloalto”, builds on GMP for the low‑level limb operations and provides a rich API covering addition, subtraction, multiplication, squaring, division, GCD, extended GCD, and a full suite of modular operations (addition, subtraction, multiplication, squaring, exponentiation, inversion, division, quadratic‑residue testing, and square‑root extraction). Functions are offered both in “full‑precision” form (producing high and low parts) and “word‑size” form (result reduced modulo 2^{2^k}). Benchmarks using the GMPbench suite on a Xeon X5482 (3.2 GHz) show that RecInt’s throughput for fixed‑precision addition, multiplication (both complete and truncated), modular multiplication, and modular exponentiation is comparable to GMP 5.0.1, and it even outperforms GMP for small fixed precisions (≤256 bits).
On the hardware side, the authors leverage GAUT, a high‑level synthesis tool that translates C++ source into VHDL. By feeding the same RecInt source code into GAUT, they generate hardware descriptions for modular exponentiation at 128‑, 256‑, and 512‑bit word sizes on a Xilinx Virtex‑5 FPGA. The generated designs, though not yet manually optimized, already demonstrate a favorable area‑vs‑throughput trade‑off: reducing the output flow (i.e., allowing deeper pipelines) significantly cuts required resources. The authors argue that because the recursive data structure is simple and regular, further hand‑tuning or tool‑level optimizations can yield high‑performance, low‑area arithmetic cores suitable for cryptographic accelerators.
In summary, RecInt offers a unified framework that bridges software and hardware implementations of fixed‑precision arithmetic. Its recursive representation enables efficient divide‑and‑conquer algorithms for multiplication, division, and modular reduction, while the template‑based C++ design ensures that the same code base can be compiled for CPUs (leveraging GMP’s optimized limb routines) or synthesized into FPGA logic with minimal changes. The work demonstrates that, for cryptographic workloads requiring deterministic, fixed‑size operands, RecInt can achieve performance on par with state‑of‑the‑art libraries and provides a promising path toward secure, reconfigurable arithmetic accelerators. Future work includes extending the approach to larger sizes (1024 bits and beyond), exploring ASIC synthesis, and integrating side‑channel countermeasures directly into the recursive arithmetic primitives.
Comments & Academic Discussion
Loading comments...
Leave a Comment