Semantic Interlinking of Resources in the Virtual Observatory Era
In the coming era of data-intensive science, it will be increasingly important to be able to seamlessly move between scientific results, the data analyzed in them, and the processes used to produce them. As observations, derived data products, publications, and object metadata are curated by different projects and archived in different locations, establishing the proper linkages between these resources and describing their relationships becomes an essential activity in their curation and preservation. In this paper we describe initial efforts to create a semantic knowledge base allowing easier integration and linking of the body of heterogeneous astronomical resources which we call the Virtual Observatory (VO). The ultimate goal of this effort is the creation of a semantic layer over existing resources, allowing applications to cross boundaries between archives. The proposed approach follows the current best practices in Semantic Computing and the architecture of the web, allowing the use of off-the-shelf technologies and providing a path for VO resources to become part of the global web of linked data.
💡 Research Summary
The paper addresses a fundamental challenge in modern, data‑intensive astronomy: how to seamlessly move among scientific results, the underlying observational data, and the processes that generate them, when these resources are curated by disparate projects and stored in heterogeneous archives. While bibliographic metadata is centrally harvested by the ADS and object metadata by services such as SIMBAD, NED, and Vizier, observational datasets remain fragmented across wavelength‑specific or observatory‑specific repositories, making unified discovery and provenance tracking difficult.
To solve this, the authors propose building a semantic knowledge base that overlays the existing Virtual Observatory (VO) resources. The approach follows best practices in semantic computing: each resource (Observation, DataProduct, Publication, AstronomicalObject) is assigned a unique URI, and the relationships among them are modeled using OWL ontologies. Three layered ontologies are defined: VAOBase (core scientific‑process concepts), VAOObsv (observations and associated data products), and VAOBib (publications). These ontologies reuse established vocabularies—IVOA ObsCore and CAOM for observation metadata, FRBR‑based FABIO and CiTO for bibliographic entities, and domain‑specific vocabularies for astronomical objects—ensuring interoperability with existing standards.
The research lifecycle is captured in a graph of RDF triples. For example, an Observation may have the property asAResultOfProposal linking it to an ObservationProposal; a DataProduct is linked to its originating Observation via hasDataProduct; a Publication is linked to the underlying data and objects through properties such as aboutScienceProcess and aboutScienceProduct. By storing only the relationships that are known, the system can be incrementally enriched, and inference engines can derive implicit links (e.g., datasets that share overlapping footprints).
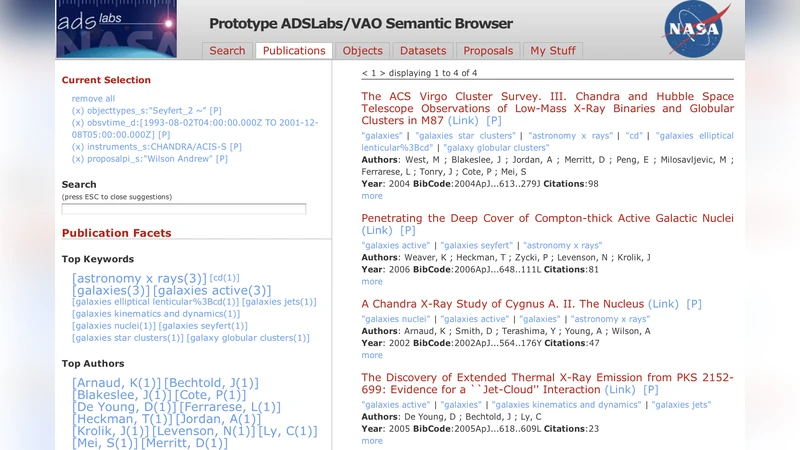
Implementation relies on open‑source triple stores and indexing engines to expose a Linked Data endpoint, enable SPARQL querying, and provide fast faceted search over key attributes (position, wavelength, instrument, etc.). Bibliographic metadata is harvested from ADS, object metadata from NED/SIMBAD, and observational metadata from participating archives, all mapped to the common ontology. The authors also envision using text‑mining techniques to extract hidden provenance information (grant numbers, program identifiers) from full‑text articles, further populating the knowledge base.
The resulting infrastructure supports several applications: cross‑archive discovery of datasets related to a given object or paper, automated generation of data‑publication linkages for bibliographic groups, and enhanced reproducibility by exposing the full provenance chain from proposal to final publication. Because the system is built on widely adopted Semantic Web standards, it can evolve as new data types, services, or community standards emerge, offering a scalable path for the VO to become part of the global web of linked data.
In summary, the paper demonstrates how a semantic layer—implemented with RDF, OWL, and existing astronomical vocabularies—can integrate heterogeneous VO resources, enable sophisticated queries and inference, and ultimately improve data discovery, provenance tracking, and scientific reproducibility across the astronomical community.
Comments & Academic Discussion
Loading comments...
Leave a Comment