Software is a directed multigraph (and so is software process)
For a software system, its architecture is typically defined as the fundamental organization of the system incorporated by its components, their relationships to one another and their environment, and the principles governing their design. If contributed to by the artifacts coresponding to engineering processes that govern the system’s evolution, the definition gets natually extended into the architecture of software and software process. Obviously, as long as there were no software systems, managing their architecture was no problem at all; when there were only small systems, managing their architecture became a mild problem; and now we have gigantic software systems, and managing their architecture has become an equally gigantic problem (to paraphrase Edsger Dijkstra). In this paper we propose a simple, yet we believe effective, model for organizing architecture of software systems. First of all we postulate that only a hollistic approach that supports continuous integration and verification for all software and software process architectural artifacts is the one worth taking. Next we indicate a graph-based model that not only allows collecting and maintaining the architectural knowledge in respect to both software and software process, but allows to conveniently create various quantitive metric to asses their respective quality or maturity. Such model is actually independent of the development methodologies that are currently in-use, that is it could well be applied for projects managed in an adaptive, as well as in a formal approach. Eventually we argue that the model could actually be implemented by already existing tools, in particular graph databases are a convenient implementation of architectural repository.
💡 Research Summary
The paper argues that modern software systems and their development processes have become so large and heterogeneous that traditional list‑ or tree‑based representations of architectural artifacts are no longer sufficient. To address this, the authors propose a unified, graph‑theoretic model in which every artifact produced during a project—source code elements, requirements, test cases, build scripts, documentation, etc.—is represented as a vertex, and every relationship between artifacts (calls, containment, implementation, verification, generation, dependency, and so on) is represented as a directed, labeled edge. The model is a directed multigraph, allowing multiple edges of different types between the same pair of vertices, which captures the richness of real‑world dependencies that cannot be expressed in a simple hierarchy.
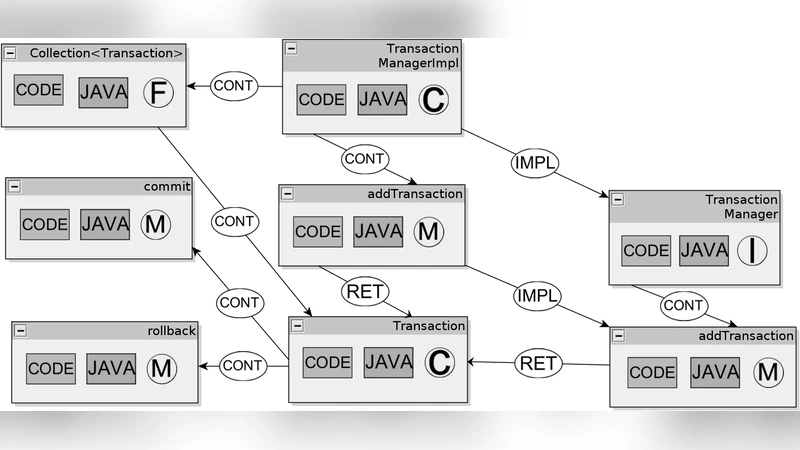
Two auxiliary concepts are introduced: graph views and graph maps. A view selects a subset of artifact types (A₀) and trace types (T₀) and extracts the corresponding subgraph, enabling focused visualisation such as a “class view” that shows only classes, interfaces, methods, fields and the contain/implement/return relationships among them. A map defines a transformation on edge labels (e.g., collapsing a contain‑followed‑by‑return chain into a depend relationship) and computes its transitive closure, thereby producing higher‑level abstractions like traditional UML class diagrams directly from the underlying multigraph.
The authors formalise metrics as functions that take the full set of vertices, edges, and their annotations and return real numbers, computable by standard graph algorithms. Examples include reachability‑based measures for requirement coverage (every requirement should be able to reach all other artifacts), test coverage (each method reachable from at least one unit test), and coupling factors (count of neighbouring vertices of a given type). Because the model integrates both software and process artifacts, it opens the possibility of composite metrics that assess not only code quality but also process maturity (e.g., the ratio of automated build steps that are traceable to specific requirements).
Implementation is envisioned on top of existing graph databases such as Neo4j or JanusGraph. These systems naturally support vertices with arbitrary properties, labeled edges, and declarative query languages (Cypher, Gremlin) that can express the required view extraction, map transformation, and metric calculation efficiently. By embedding the graph update step into continuous‑integration pipelines, the architecture repository can stay synchronized with the evolving code base, enabling real‑time validation of architectural constraints and automatic generation of reports.
The paper also acknowledges several research challenges. Defining a comprehensive yet practical taxonomy of artifact types (A) and trace types (T) is non‑trivial; projects will only use subsets, and automatic classification is needed to avoid prohibitive manual effort. Scalability is another concern: a large industrial system may generate millions of vertices and edges, raising performance issues for real‑time visualisation and metric computation. Techniques such as graph sharding, indexing, and incremental computation are suggested but not explored in depth. Moreover, user‑friendly visualisation of massive graphs, integration with existing tools (issue trackers, static analysers, test frameworks), and the design of a domain‑specific query language tailored to architectural questions remain open problems.
In conclusion, the authors present a compelling vision: by treating software and its development process as a single directed multigraph, one can achieve holistic architecture management, unify disparate metrics, and leverage mature graph‑database technology to support continuous integration and verification. While the model is conceptually straightforward, its practical adoption will require substantial work on taxonomy definition, performance optimisation, tool integration, and empirical validation on real‑world projects. The paper outlines a clear research agenda that, if pursued, could significantly advance the state of software architecture engineering.
Comments & Academic Discussion
Loading comments...
Leave a Comment