Detect Related Bugs from Source Code Using Bug Information
Open source projects often maintain open bug repositories during development and maintenance, and the reporters often point out straightly or implicitly the reasons why bugs occur when they submit them. The comments about a bug are very valuable for developers to locate and fix the bug. Meanwhile, it is very common in large software for programmers to override or overload some methods according to the same logic. If one method causes a bug, it is obvious that other overridden or overloaded methods maybe cause related or similar bugs. In this paper, we propose and implement a tool Rebug- Detector, which detects related bugs using bug information and code features. Firstly, it extracts bug features from bug information in bug repositories; secondly, it locates bug methods from source code, and then extracts code features of bug methods; thirdly, it calculates similarities between each overridden or overloaded method and bug methods; lastly, it determines which method maybe causes potential related or similar bugs. We evaluate Rebug-Detector on an open source project: Apache Lucene-Java. Our tool totally detects 61 related bugs, including 21 real bugs and 10 suspected bugs, and it costs us about 15.5 minutes. The results show that bug features and code features extracted by our tool are useful to find real bugs in existing projects.
💡 Research Summary
The paper presents Rebug‑Detector, a novel tool that automatically discovers bugs related to a known defect by leveraging information from bug reports and source code features, particularly focusing on overridden or overloaded methods that share the same logical implementation. The authors observe that in large Java projects, many methods are duplicated across class hierarchies through polymorphism; when a bug exists in one implementation, other implementations are likely to suffer the same flaw. Traditional static analysis tools mainly target copy‑paste patterns, API misuse, or rule violations, but they do not systematically identify such “logic‑consistency” bugs.
Rebug‑Detector operates in four main stages. First, it parses XML bug reports from an issue‑tracking system and applies natural‑language processing (NLP) techniques to extract key tokens: class names, method names, domain‑specific terms (e.g., “collator”, “null”), and relevant code fragments such as conditional statements. Because bug reports are often short, noisy, and contain programming jargon, the authors augment standard NLP with a domain dictionary and weight tokens by frequency using a vector‑space model (VSM).
Second, the tool locates the buggy method in the source tree using the extracted class and method identifiers. Third, it gathers all overridden or overloaded counterparts of that method by traversing the inheritance hierarchy and matching method signatures. For each candidate method, Rebug‑Detector extracts code features: tokenized source lines, keyword frequencies, and structural patterns.
The fourth stage computes a similarity score between the original buggy method and each candidate. The authors adopt a common‑substring based metric, enhanced with keyword weighting, to capture both syntactic overlap and semantic importance. If the similarity exceeds a predefined threshold θ, the candidate is flagged as a potential related bug.
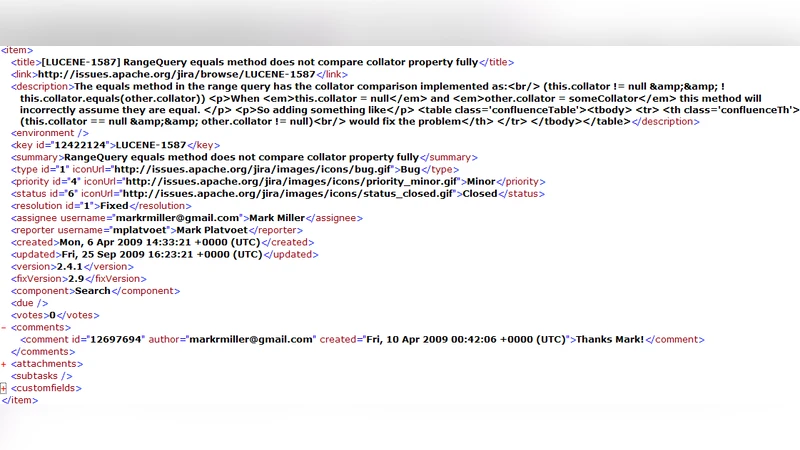
The authors implemented the approach in Java and evaluated it on Apache Lucene‑Java version 2.4.1, a project comprising 330 classes and 106,754 lines of code. The entire detection pipeline—parsing bug XML files, extracting features, enumerating candidates, and calculating similarities—completed in 15.5 minutes. Rebug‑Detector reported 61 related bugs; manual inspection confirmed 21 as genuine defects and identified 10 additional suspicious cases that had not yet been reported. A concrete example is bug LUCENE‑1587, which involves an incomplete null‑check in RangeQuery.equals. The tool automatically discovered the same logical omission in RangeFilter.equals, leading to the new bug report LUCENE‑2131, which was accepted by the Lucene developers.
The paper discusses three primary challenges. (1) Bug reports are short, often ungrammatical, and intermix natural language with code tokens, making reliable NLP extraction difficult. (2) Determining whether an overridden/overloaded method is likely to share the same fault requires a similarity metric that balances syntactic overlap with semantic relevance. (3) The system must be accurate enough to avoid overwhelming developers with false positives, usable without deep configuration, and scalable to large codebases.
Key contributions are: (i) a general method for extracting both bug‑level features from issue reports and code‑level features from Java source, and (ii) an efficient algorithm that matches these feature sets to detect related bugs across polymorphic method families. The authors compare their work with prior research on mining requirements, comments, API documentation, and source code using data‑mining and NLP, noting that Rebug‑Detector is the first to combine bug‑report semantics with code similarity for this specific purpose.
Limitations are acknowledged. The similarity measure relies heavily on method name equality; methods with identical names but different semantics (e.g., overloads with distinct parameter types) may generate false positives. The common‑substring metric does not capture deeper structural differences, potentially missing more complex logical divergences. The threshold θ is set empirically and may need tuning per project.
Future work suggested includes adopting abstract syntax tree (AST) based structural similarity, integrating machine‑learning models to learn bug patterns from historical data, and incorporating dynamic execution information (e.g., test coverage) to refine candidate ranking.
In conclusion, Rebug‑Detector demonstrates that integrating bug‑report information with source‑code analysis can effectively uncover hidden, logic‑related defects in large Java systems. The experimental results show a modest runtime and a reasonable true‑positive rate, indicating that the approach can complement existing static analysis tools and aid developers in maintaining software reliability.
Comments & Academic Discussion
Loading comments...
Leave a Comment