High-Throughput Transaction Executions on Graphics Processors
OLTP (On-Line Transaction Processing) is an important business system sector in various traditional and emerging online services. Due to the increasing number of users, OLTP systems require high throughput for executing tens of thousands of transactions in a short time period. Encouraged by the recent success of GPGPU (General-Purpose computation on Graphics Processors), we propose GPUTx, an OLTP engine performing high-throughput transaction executions on the GPU for in-memory databases. Compared with existing GPGPU studies usually optimizing a single task, transaction executions require handling many small tasks concurrently. Specifically, we propose the bulk execution model to group multiple transactions into a bulk and to execute the bulk on the GPU as a single task. The transactions within the bulk are executed concurrently on the GPU. We study three basic execution strategies (one with locks and the other two lock-free), and optimize them with the GPU features including the hardware support of atomic operations, the massive thread parallelism and the SPMD (Single Program Multiple Data) execution. We evaluate GPUTx on a recent NVIDIA GPU in comparison with its counterpart on a quad-core CPU. Our experimental results show that optimizations on GPUTx significantly improve the throughput, and the optimized GPUTx achieves 4-10 times higher throughput than its CPU-based counterpart on public transaction processing benchmarks.
💡 Research Summary
The paper addresses the growing demand for high‑throughput online transaction processing (OLTP) in modern web services, where tens of thousands of short transactions must be completed within milliseconds. While general‑purpose GPU (GPGPU) research has demonstrated impressive speedups for single, large‑scale kernels, it has not adequately tackled workloads composed of many tiny, independent tasks such as OLTP. To fill this gap, the authors introduce GPUTx, an OLTP engine that executes transactions on a modern NVIDIA GPU for in‑memory databases.
Core Concept – Bulk Execution Model
Instead of launching a separate GPU kernel for each transaction, GPUTx groups a set of transactions into a bulk. The bulk is transferred to the GPU once and processed by a single kernel, where each transaction is mapped to a distinct thread or warp. This model leverages the massive parallelism of GPUs (thousands of cores) while minimizing kernel launch overhead and host‑device synchronization.
Three Execution Strategies
- Lock‑Based Strategy – Implements a classic two‑phase locking (2PL) protocol on the GPU. Each data item holds a mutex implemented with an atomic compare‑and‑swap (CAS). Threads acquire locks before reading or writing, spin‑waiting on contention. The GPU’s native atomic operations make deadlock avoidance feasible, but the spin loops can cause warp stalls and reduce overall efficiency.
- Optimistic Lock‑Free Strategy A – Splits a transaction into a read‑only phase and a write‑phase. During the read phase, no synchronization is performed. In the write phase, each thread atomically increments a version counter (fetch‑and‑add) for the items it updates. After the write, the thread validates that the versions observed during the read have not changed; if they have, the transaction is aborted and retried. This approach works well when conflicts are rare, delivering high throughput with minimal synchronization cost.
- Optimistic Lock‑Free Strategy B (Hybrid) – Further reduces contention by pre‑sorting write‑sets and assigning transactions that modify the same data items to the same warp. Because all threads in a warp access contiguous memory locations, memory coalescing is maximized and the number of required atomic operations is lowered. Conflict detection is performed at the warp level, allowing a single atomic check to validate many transactions simultaneously.
GPU‑Specific Optimizations
- Data Layout: Records are stored in a Structure‑of‑Arrays (SOA) format, enabling contiguous global‑memory accesses and better cache utilization.
- Shared‑Memory Caching: Frequently accessed tuples and version tables are staged in per‑block shared memory, reducing latency of global memory reads/writes.
- SPMD Execution: All threads execute the same kernel code; divergence is minimized by branching on transaction type only once per warp.
- Coalesced Writes: The hybrid strategy aligns write operations so that each warp writes to a single memory segment, exploiting the GPU’s wide memory bus.
- Atomic Support: The design relies on NVIDIA’s hardware‑accelerated atomic primitives (CAS, fetch‑and‑add) for lock acquisition and version updates, avoiding software‑emulated synchronization.
Experimental Evaluation
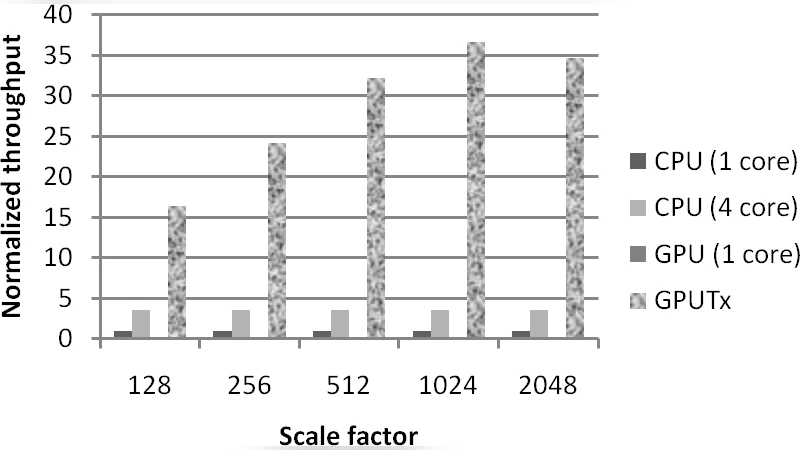
The authors benchmark GPUTx on a recent NVIDIA GPU (e.g., GTX 1080 Ti) against a highly tuned CPU implementation running on a quad‑core Intel Xeon processor. Two widely used OLTP benchmarks are employed: TPC‑C (transaction processing performance council) and YCSB (Yahoo! Cloud Serving Benchmark). Experiments vary bulk size, read/write ratios, and contention levels. Key findings include:
- The hybrid lock‑free strategy consistently outperforms the other two, achieving 4–10× higher throughput than the CPU baseline.
- For read‑heavy workloads (≈80 % reads), speedups approach the upper bound (≈10×) because contention is minimal and memory coalescing dominates performance.
- In write‑intensive scenarios (≈50 % writes) with moderate contention, the lock‑based approach suffers from warp stalls, while the optimistic strategies retain a 4–6× advantage.
- Scaling bulk size shows diminishing returns beyond a certain point due to GPU memory bandwidth saturation, but the optimal bulk size (≈10 K transactions) yields the best trade‑off between latency and throughput.
Limitations and Future Work
The study acknowledges several constraints:
- GPU Memory Capacity – The entire database must fit in GPU DRAM; otherwise, paging to host memory introduces prohibitive latency.
- High Contention – When many transactions target the same hot items, abort‑retry loops increase, eroding the benefits of lock‑free designs.
- Single‑GPU Scope – The current prototype runs on a single GPU; extending to multi‑GPU or heterogeneous CPU‑GPU scheduling remains an open challenge.
- Durability & Recovery – The paper focuses on in‑memory execution and does not integrate logging, checkpointing, or crash recovery mechanisms, which are essential for production OLTP systems.
Future directions suggested include dynamic data partitioning to keep hot subsets on the GPU, adaptive bulk sizing based on runtime contention metrics, and a hybrid execution engine that offloads only contention‑free transactions to the GPU while the CPU handles the rest.
Conclusion
GPUTx demonstrates that GPUs, traditionally viewed as accelerators for compute‑intensive kernels, can be repurposed to handle high‑concurrency transaction processing when the workload is carefully reorganized into bulk executions and when lock‑free synchronization techniques are employed. The experimental results validate the concept, showing order‑of‑magnitude throughput improvements over a state‑of‑the‑art CPU OLTP engine on standard benchmarks. By exposing both the opportunities and the practical challenges (memory limits, contention handling, durability), the paper paves the way for future research into GPU‑centric database architectures and hybrid CPU‑GPU transaction processing platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment