Computing an Aggregate Edge-Weight Function for Clustering Graphs with Multiple Edge Types
We investigate the community detection problem on graphs in the existence of multiple edge types. Our main motivation is that similarity between objects can be defined by many different metrics and aggregation of these metrics into a single one poses several important challenges, such as recovering this aggregation function from ground-truth, investigating the space of different clusterings, etc. In this paper, we address how to find an aggregation function to generate a composite metric that best resonates with the ground-truth. We describe two approaches: solving an inverse problem where we try to find parameters that generate a graph whose clustering gives the ground-truth clustering, and choosing parameters to maximize the quality of the ground-truth clustering. We present experimental results on real and synthetic benchmarks.
💡 Research Summary
The paper tackles community detection in graphs where each edge carries multiple similarity measurements (multiple edge types). Instead of discarding or arbitrarily merging these measurements, the authors aim to learn a linear aggregation function that best reproduces a known ground‑truth clustering. Formally, each edge i is represented by a K‑dimensional weight vector (w_i = (w_i^1,\dots,w_i^K)). A linear combination with coefficients (\alpha = (\alpha_1,\dots,\alpha_K)) yields a scalar weight (w_i(\alpha)=\sum_{j=1}^K \alpha_j w_i^j). The central problem is: given a graph with such multi‑type edges and a ground‑truth partition (C^), find (\alpha) such that (C^) is “optimal” for the graph weighted by (w_i(\alpha)).
Two complementary strategies are proposed.
-
Inverse‑problem approach – Treat the clustering algorithm as a forward model. Starting from a random (\alpha), compute the scalar‑weighted graph, run a standard single‑edge clustering method (the authors use Graclus), and measure the distance between the resulting partition and the ground truth using Variation of Information (VI). The VI distance becomes the objective to minimize over (\alpha). This creates a black‑box optimization loop: each evaluation requires a full clustering run, making the process computationally expensive and sensitive to the quality of the clustering algorithm.
-
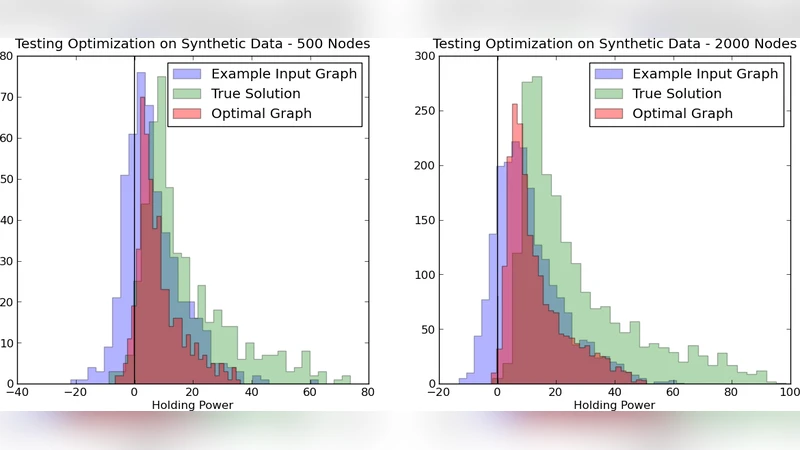
Quality‑maximization approach – Directly optimize a composite objective that reflects (i) the local “holding power” of each vertex and (ii) a global clustering quality metric. For a vertex v, the pull toward a cluster (C_k) is defined as the sum of edge weights (under (\alpha)) connecting v to vertices in (C_k). The holding power (H_\alpha(v)) is the difference between the pull toward v’s true cluster and the strongest pull toward any other cluster. Positive holding power indicates that v is correctly placed. Because the indicator (H_\alpha(v)>0) is discrete, the authors smooth it with an arctangent function (\arctan(\beta H_\alpha(v))), which provides gradients for optimization while still encouraging positivity. The second component of the objective is modularity, a widely used global quality measure that compares the observed intra‑cluster edge weight to a null model based on the degree distribution. The final objective is a weighted sum of the smoothed holding powers over all vertices and the modularity score.
Both objectives are non‑differentiable with respect to (\alpha); therefore the authors employ HOPSPACK, a derivative‑free global optimization package, to search the parameter space.
Experiments are conducted on synthetic benchmarks (Lancichinetti‑Fortunato graphs) and a real file‑system dataset. In the synthetic case, graphs of 500 to 4000 nodes are generated with known community structure, then each edge weight is perturbed by additive and multiplicative noise, producing ten noisy similarity metrics. Individually, none of these noisy metrics preserve the original clustering (many vertices obtain negative holding power). After optimization, the linear combination of the ten metrics yields a composite weight in which >99% of vertices have positive holding power, and the VI distance to the ground truth drops dramatically. Table 1 reports the fraction of vertices with positive holding power for the ground truth, perturbed, and optimized cases across different graph sizes.
In the file‑system experiment, 300 files are manually labeled into three project‑based clusters. Four similarity measures are considered: filename similarity, modification/creation time similarity, directory‑tree distance, and parent‑child adjacency. Optimization identifies that time similarity, ancestry, and parenthood contribute most, while filename similarity is largely ignored. The results are sensitive to the arctangent steepness parameter (\beta), illustrating the trade‑off between strict classification and smooth gradient information.
Key contributions of the work include: (a) formalizing the problem of learning a linear aggregation function for multi‑type edge graphs from ground‑truth partitions; (b) proposing two distinct optimization frameworks—one based on inverse clustering and another on direct quality maximization with a novel “holding power” concept; (c) demonstrating that a suitable linear blend can recover high‑quality clusterings even when each individual metric is heavily corrupted; and (d) providing empirical evidence on both synthetic and real data.
Limitations are acknowledged: the linear aggregation assumption cannot capture complex non‑linear interactions among metrics; derivative‑free optimization scales poorly with graph size; and reliance on a known ground‑truth restricts applicability to supervised scenarios. Future directions suggested include exploring non‑linear aggregation functions (e.g., kernel methods or neural networks), developing scalable gradient‑based or stochastic optimization schemes, and extending the framework to handle noisy or partially known ground‑truth partitions.
Overall, the paper offers a practical methodology for integrating heterogeneous similarity information into a single edge weight that aligns with desired community structures, thereby enabling the reuse of mature single‑edge clustering algorithms in richer, multi‑modal network settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment