Wikipedia information flow analysis reveals the scale-free architecture of the Semantic Space
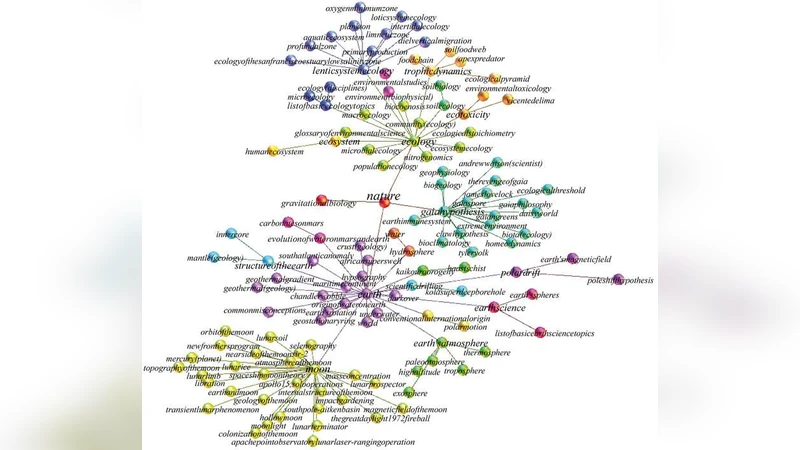
In this paper we extract the topology of the semantic space in its encyclopedic acception, measuring the semantic flow between the different entries of the largest modern encyclopedia, Wikipedia, and thus creating a directed complex network of semantic flows. Notably at the percolation threshold the semantic space is characterised by scale-free behaviour at different levels of complexity and this relates the semantic space to a wide range of biological, social and linguistics phenomena. In particular we find that the cluster size distribution, representing the size of different semantic areas, is scale-free. Moreover the topology of the resulting semantic space is scale-free in the connectivity distribution and displays small-world properties. However its statistical properties do not allow a classical interpretation via a generative model based on a simple multiplicative process. After giving a detailed description and interpretation of the topological properties of the semantic space, we introduce a stochastic model of content-based network, based on a copy and mutation algorithm and on the Heaps’ law, that is able to capture the main statistical properties of the analysed semantic space, including the Zipf’s law for the word frequency distribution.
💡 Research Summary
The paper presents a novel quantitative investigation of the semantic space (SS) by treating each Wikipedia article as a population of “interpretants” (words that define its meaning) and measuring directed semantic flows between articles. Using a June‑2008 snapshot of English Wikipedia (~2 million entries), the authors first clean the text (remove punctuation, stop‑words, and perform lemmatization) to obtain a high‑dimensional lemma‑frequency vector for each page. They then compute pairwise Jensen‑Shannon divergences, which provide an asymmetric distance and a directionality of information flow, following the method introduced in reference
Comments & Academic Discussion
Loading comments...
Leave a Comment