On the apparently fixed dispersion of size distributions
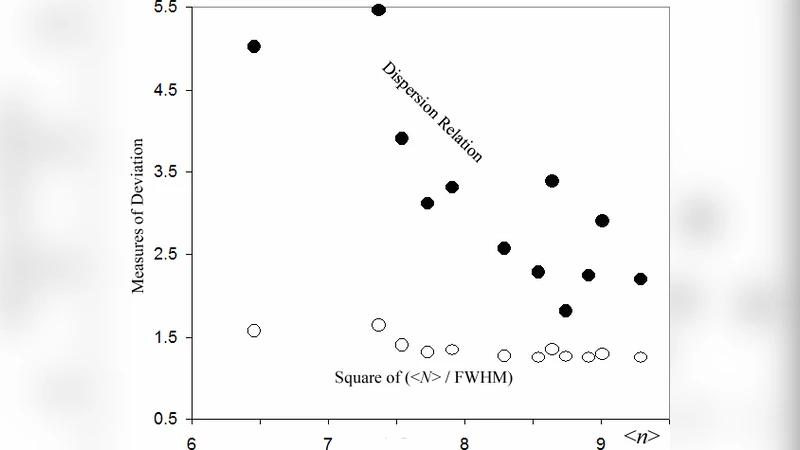
Probability density functions (PDF) of statistical distributions of cluster sizes N, where N is the number of particles in the cluster, often seem to have less freedom than expected from considering the number of degrees of freedom at the clusters’ source. The full width at half maximum appears to be comparable to the average
💡 Research Summary
The paper addresses a puzzling observation in the study of particle clusters: the apparent “fixed” dispersion of size distributions, where the full width at half maximum (FWHM) of the distribution is often comparable to the mean cluster size ⟨N⟩. At first glance this seems to suggest a hidden symmetry that limits the variability of clusters despite the many degrees of freedom present at the source. The authors argue that this impression is largely an artifact of the statistical models traditionally employed to analyse cluster‑size data.
Using helium‑cluster beams as a concrete example, the authors show that experimental size data are routinely fitted with either a log‑normal (LN) or an exponential (EXP) probability density function. In practice the raw data are transformed to logarithmic space (n = ln N) and then a two‑parameter LN (μ, σ) or a single‑parameter EXP (λ) is fitted. Because these parametric forms impose a strict relationship between the mean and the variance—LN through σ and EXP through the equality of mean and variance—the resulting fitted distributions inevitably display a FWHM that scales with the mean. Consequently, the “fixed dispersion” is not a physical property of the clusters but a consequence of the chosen functional form.
The authors re‑examine published helium‑cluster data by performing both the conventional LN/EXP fits in log‑space and a direct analysis in the original N‑space. While the log‑space fits achieve low χ² values, the back‑transformed residuals reveal systematic under‑prediction at small N and over‑prediction at large N, indicating that the assumed functional forms cannot capture the true asymmetry and heavy tails of the distribution. This discrepancy demonstrates that the apparent constraint on dispersion is a fitting artifact rather than a genuine physical constraint.
To overcome this limitation, the paper proposes several alternative statistical approaches. First, non‑parametric kernel density estimation (KDE) avoids any a priori shape assumption and faithfully reproduces the empirical distribution, including skewness and long tails. Second, the maximum‑entropy (MaxEnt) method constructs the least‑biased distribution consistent only with known constraints (e.g., the measured mean and total particle number), thereby preventing the inadvertent imposition of extra variance constraints. Third, mixture‑model techniques—combining multiple LN or EXP components using an Expectation‑Maximization algorithm—allow the data to reveal multiple sub‑populations or multimodal structures that a single LN or EXP cannot represent.
The paper concludes that the perceived “fixed dispersion” in cluster‑size distributions is a statistical illusion arising from the over‑reliance on simple parametric models in log‑space. By adopting more flexible, data‑driven methods, researchers can obtain a more accurate picture of the true variability of clusters, which in turn improves size‑selection strategies, enhances production efficiency, and narrows the gap between theoretical predictions and experimental observations. The insights are broadly applicable to any field dealing with size distributions of aggregates, such as aerosol science, nanoparticle synthesis, and astrophysical dust studies.
Comments & Academic Discussion
Loading comments...
Leave a Comment