Diagonal Based Feature Extraction for Handwritten Alphabets Recognition System using Neural Network
An off-line handwritten alphabetical character recognition system using multilayer feed forward neural network is described in the paper. A new method, called, diagonal based feature extraction is introduced for extracting the features of the handwritten alphabets. Fifty data sets, each containing 26 alphabets written by various people, are used for training the neural network and 570 different handwritten alphabetical characters are used for testing. The proposed recognition system performs quite well yielding higher levels of recognition accuracy compared to the systems employing the conventional horizontal and vertical methods of feature extraction. This system will be suitable for converting handwritten documents into structural text form and recognizing handwritten names.
💡 Research Summary
**
The paper presents an offline handwritten English alphabet recognition system that introduces a novel diagonal‑based feature extraction method and evaluates its performance using a multilayer feed‑forward neural network (MLP). The overall pipeline follows the conventional stages of image acquisition, preprocessing, segmentation, feature extraction, classification, and post‑processing, but the authors focus on improving the feature extraction stage, which they argue is the most critical factor for achieving high recognition rates.
Image acquisition and preprocessing
Scanned images (JPEG, BMP, etc.) are binarized using a global threshold, edges are detected with the Sobel operator, and morphological dilation followed by hole‑filling is applied to produce clean binary character images suitable for segmentation.
Segmentation
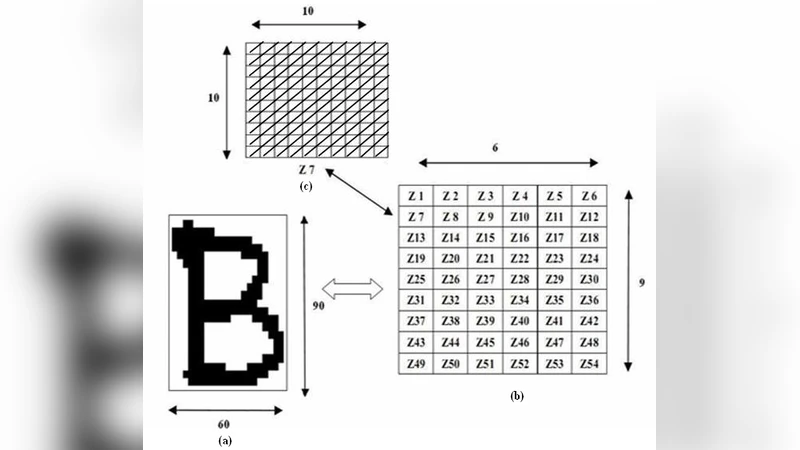
Connected‑component labeling isolates individual characters, each of which is resized to a fixed 90 × 60 pixel grid. This uniform size ensures that subsequent feature extraction operates on a consistent spatial layout.
Diagonal‑based feature extraction
The resized character is divided into 54 non‑overlapping zones of 10 × 10 pixels (6 rows × 9 columns). Within each zone, the authors compute the sum of foreground pixels along each of the 19 possible diagonal lines. The 19 sums are averaged to produce a single scalar value for that zone. Consequently, a 54‑dimensional feature vector is obtained. To enrich the representation, the authors also calculate row‑wise and column‑wise averages across zones, yielding 9 additional row features and 6 column features. The final descriptor thus contains 69 dimensions (54 zone features + 15 aggregated features).
Neural network classifier
A feed‑forward back‑propagation network with two hidden layers (each containing 100 neurons) is employed. The input layer size matches the feature vector length (either 54 or 69). Hidden neurons use a log‑sigmoid activation function; the output layer is a competitive layer with 26 neurons, one for each alphabet letter. Training uses gradient descent with momentum (0.9) and an adaptive learning rate, minimizing mean‑square error (MSE) to a goal of 1 × 10⁻⁶. Training stops when the error goal is reached or after a maximum of 1,000,000 epochs.
Experimental setup
The authors collected 50 training sets, each containing the 26 letters written by different individuals, and 570 test samples. Three feature extraction orientations—vertical, horizontal, and diagonal—are evaluated under two configurations: (i) using only the 54 zone features, and (ii) using the full 69‑dimensional vector. Six neural networks are trained (three orientations × two feature‑vector sizes).
Results
When only the 54 zone features are used, the diagonal orientation achieves a recognition rate of 97.80 %, compared with 92.69 % (vertical) and 93.68 % (horizontal). With the full 69‑dimensional vector, diagonal extraction reaches 98.54 % accuracy, while vertical and horizontal achieve 92.69 % and 94.73 %, respectively. Moreover, the diagonal‑based networks converge faster: the 54‑feature diagonal network reaches the MSE goal after 923 epochs, and the 69‑feature version after 854 epochs, both fewer than the epochs required for the other orientations.
Implementation
A MATLAB‑based graphical user interface (GUI) allows users to load images, select the preprocessing steps, choose the feature extraction orientation, train the network, and perform recognition. The GUI displays the recognized character in a text window, making the system accessible without command‑line interaction.
Conclusions and future work
The diagonal feature extraction method captures structural information along slanted strokes that are poorly represented by purely horizontal or vertical projections. This leads to higher recognition accuracy and faster training convergence. The authors claim that the system, with near‑99 % accuracy, is suitable for applications such as postal address reading, bank cheque processing, and document digitization.
However, the study has limitations. The dataset is confined to English uppercase letters and may not reflect the variability found in real‑world documents (different fonts, cursive writing, noise, rotation, scaling). The handling of empty diagonals (assigning a zero value) could be sensitive to noise. Future research directions suggested include testing on larger, more diverse datasets (including lowercase letters, other scripts, and multilingual text), comparing the diagonal approach with deep‑learning feature learners such as convolutional neural networks, and incorporating invariance to rotation and scale. Extending the method to online handwriting, where temporal stroke information is available, could also be explored.
In summary, the paper contributes a simple yet effective diagonal‑based feature extraction scheme that, when coupled with a modest‑size MLP, yields state‑of‑the‑art performance on a benchmark handwritten alphabet task, while maintaining low computational complexity and ease of implementation.
Comments & Academic Discussion
Loading comments...
Leave a Comment