Named Entity Recognition Using Web Document Corpus
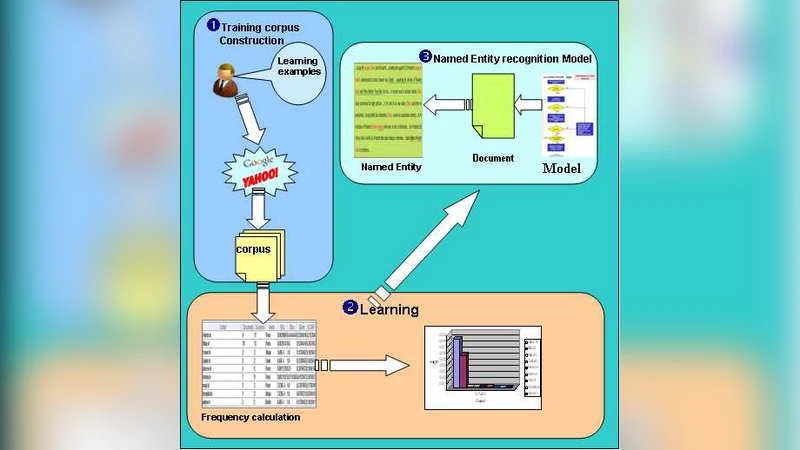
This paper introduces a named entity recognition approach in textual corpus. This Named Entity (NE) can be a named: location, person, organization, date, time, etc., characterized by instances. A NE is found in texts accompanied by contexts: words that are left or right of the NE. The work mainly aims at identifying contexts inducing the NE’s nature. As such, The occurrence of the word “President” in a text, means that this word or context may be followed by the name of a president as President “Obama”. Likewise, a word preceded by the string “footballer” induces that this is the name of a footballer. NE recognition may be viewed as a classification method, where every word is assigned to a NE class, regarding the context. The aim of this study is then to identify and classify the contexts that are most relevant to recognize a NE, those which are frequently found with the NE. A learning approach using training corpus: web documents, constructed from learning examples is then suggested. Frequency representations and modified tf-idf representations are used to calculate the context weights associated to context frequency, learning example frequency, and document frequency in the corpus.
💡 Research Summary
The paper proposes a novel approach to Named Entity Recognition (NER) that leverages a corpus of web documents as a learning resource. Instead of relying on extensive handcrafted rules, gazetteers, or fully supervised training data, the authors adopt a semi‑supervised framework that starts from a small set of positive examples for each target entity class (e.g., disease names, football players, presidents, capitals). These examples are used as queries to major web search engines (Yahoo, Google, etc.) via their APIs. The search results provide URLs, which are then fetched and stored as raw text documents, forming a “learning corpus” without any manual annotation.
From each retrieved document the algorithm extracts “context candidates”: words that appear immediately to the left (and optionally to the right) of the target entity instance. The authors argue that left‑hand contexts are often more informative (e.g., “President Obama” where “President” signals a political leader). Each context is represented by a set of four frequency‑based statistics:
- Context Frequency (cf) – the proportion of occurrences of the context within the whole corpus.
- Learning‑Example Frequency (lef) – the proportion of times the context appears together with a positive example.
- Document Frequency (df) – the proportion of distinct documents that contain the context.
- Inverse Context Frequency (icf) – the inverse of the proportion of documents where the context co‑occurs with other, unrelated phrases.
These four measures are multiplied to obtain a context weight (w) (Equation 8). A high weight indicates that the context is both frequent with the target entity and relatively specific to it.
The weighted contexts are then fed into a C4.5 decision‑tree classifier. Each node corresponds to a particular context; when the context is observed in a new sentence, a “vote” value is increased by the context’s weight. Once the accumulated vote for a class exceeds a predefined threshold, the system assigns that class to the token. This voting mechanism allows the same context to contribute to multiple classes (e.g., “Mr.” can precede both a president’s name and a footballer’s name) while still enabling a final disambiguation based on the strongest evidence.
The authors evaluate the method on three entity types. For the “capital” class they collected 65 URLs, extracted 2,398 two‑word left contexts for 13 capital names, and computed the weights. The context “Hotels in” received the highest weight, demonstrating that even seemingly unrelated phrases can become strong discriminators when they co‑occur frequently with the target entities. For the “president” class, 89 variations of president names were used as examples; the experiments showed that increasing the number of contexts and the size of the document set stabilizes the weight distribution and improves recognition accuracy. A similar pattern was observed for the “football player” class, where the context “footballer” obtained a high weight.
Key contributions of the work include:
- Cost‑effective data acquisition – By harvesting web pages automatically, the approach eliminates the need for expensive gazetteer construction or large manually annotated corpora.
- Modified tf‑idf weighting – The four‑component weight captures both frequency and specificity of contexts, allowing the system to filter out noisy co‑occurrences typical of web data.
- Flexible classification – The decision‑tree with vote accumulation handles multi‑class ambiguity and can be extended to new entity types with minimal effort.
Limitations are also acknowledged. The current implementation only exploits left‑hand contexts, ignoring potentially useful right‑hand information. The reliance on a limited set of positive examples may lead to sparsity issues for rare entities, and the absence of explicitly modeled negative examples could cause over‑generalization.
Future work suggested by the authors includes integrating bidirectional contexts, employing deep neural networks to learn context representations, and devising automatic negative‑example generation to improve robustness. The authors also envision extending the framework to multilingual settings, given that the context‑weighting scheme is language‑agnostic.
In summary, the paper demonstrates that a web‑derived corpus combined with a carefully designed context‑weighting scheme can serve as a practical and scalable foundation for NER, achieving competitive performance without the heavy annotation overhead traditionally associated with the task.
Comments & Academic Discussion
Loading comments...
Leave a Comment