Learning Networks of Stochastic Differential Equations
We consider linear models for stochastic dynamics. To any such model can be associated a network (namely a directed graph) describing which degrees of freedom interact under the dynamics. We tackle the problem of learning such a network from observat…
Authors: Jose Bento, Morteza Ibrahimi, Andrea Montanari
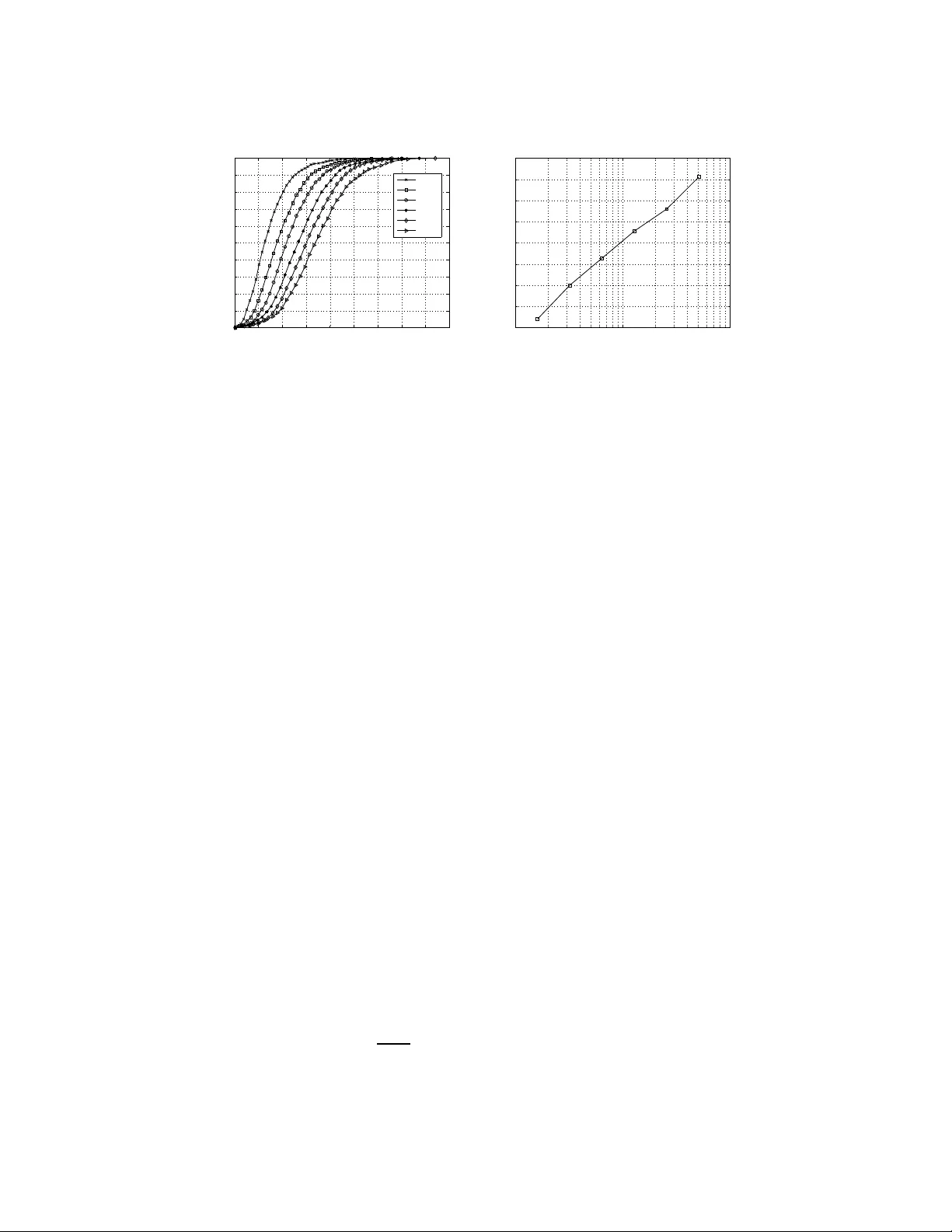
Learning Networks of Stochastic Differential Equat ions Jos ´ e Bento Departmen t of Electrical Engineer ing Stanford Uni versity Stanford, CA 94305 jbento@stanf ord.edu Morteza Ibrahimi Departmen t of Electrical Engineer ing Stanford Uni versity Stanford, CA 94305 ibrahimi@sta nford.edu Andrea Montanari Departmen t of Electrical Engineer ing and Statistics Stanford University Stanford, CA 9430 5 montanari@st anford.edu Abstract W e consider linear models for stochastic dynamics. T o any such model can be as- sociated a network (nam ely a d irected gra ph) describing which degrees of fr eedom interact u nder the dynamics. W e tackle the prob lem of learning such a network from observation of the system trajector y over a time interv al T . W e analyze the ℓ 1 -regularized least squares algorithm and, in the setting in which the underlyin g network is sparse, we prove perfor mance guar antees that are uni- form in the sampling rate as long as this is sufficiently high . This resu lt substan- tiates the no tion of a well defin ed ‘time comp lexity’ for the network infer ence problem . keywords: Gaussian pro cesses, model selection and stru cture learning, graphical models, sparsity and feature selection. 1 Intr oduction and main results Let G = ( V , E ) be a directed graph with weight A 0 ij ∈ R ass ociated to the directed edge ( j, i ) from j ∈ V to i ∈ V . T o each nod e i ∈ V in th is network is associated an indepen dent standar d Brownian motion b i and a variable x i taking values in R and e volving accordin g to d x i ( t ) = X j ∈ ∂ + i A 0 ij x j ( t ) d t + d b i ( t ) , where ∂ + i = { j ∈ V : ( j, i ) ∈ E } is the set of ‘p arents’ of i . W ithout loss of g enerality we shall take V = [ p ] ≡ { 1 , . . . , p } . In words, the r ate of change of x i is given by a weighted sum of the current values of its neig hbors, corrup ted by white noise. In matrix no tation, the same system is then represented by d x ( t ) = A 0 x ( t ) d t + d b ( t ) , (1) with x ( t ) ∈ R p , b ( t ) a p -dimen sional standar d Brownian motion and A 0 ∈ R p × p a matrix with entries { A 0 ij } i,j ∈ [ p ] whose sparsity pattern is given by th e graph G . W e assume that the linear system ˙ x ( t ) = A 0 x ( t ) is stable (i.e. that the spectrum of A 0 is co ntained in { z ∈ C : Re( z ) < 0 } ). Fur ther, we assume that x ( t = 0) is in its stationary state. More p recisely , x (0) is a Gau ssian ran dom variable 1 indepen dent of b ( t ) , distributed accordin g to the in variant measure. Und er the stability assump tion, this a mild restriction, since the system con verges exponentially to stationarity . A p ortion of time length T of the system trajectory { x ( t ) } t ∈ [0 ,T ] is ob served and we ask under which condition s these data ar e sufficient to reconstruct th e grap h G (i.e ., the sparsity p attern of A 0 ). W e are particu larly interested in co mputatio nally ef ficient procedu res, and in ch aracterizing the scaling of the lear ning time for large networks. Can the netw ork structure be learnt in a time scaling linearly with the numb er of it s degrees of freedom? As an exam ple app lication, ch emical reactio ns ca n b e co nv eniently modeled by systems o f n on- linear stochastic differential equatio ns, whose variables encod e the densities of various chemical species [1, 2]. Complex biological networks might inv olve hund reds of such species [ 3], and learn- ing s tochastic models from data is an important (and challenging) computatio nal task [4]. Consider- ing one such ch emical reactio n network in p roximity of an equilibrium poin t, the mo del (1) can be used to trace fluctu ations of the species cou nts with respect to th e equilib rium values. The network G would represent in this case the interaction s between different chemical factors. W ork in this area focused so-far on low-dimensional ne tworks, i. e. on m ethods th at are guaran teed to be cor rect fo r fixed p , as T → ∞ , while we will tackle her e the regime in which both p and T diverge. Before stating o ur results, it is useful to stress a few important d ifferences with resp ect to c lassical graphica l model learning pro blems: ( i ) S amples are not indepen dent. This can ( and does) increase the sample complexity . ( ii ) On the other h and, infinitely ma ny samples are given as data ( in fact a co llection in dexed by the continuou s par ameter t ∈ [0 , T ] ). Of course one can select a finite su bsample, for instance at regularly spaced times { x ( i η ) } i =0 , 1 ,... . This raises the q uestion as to wh ether the learning perfor mances depend on the choice of the spacing η . ( iii ) In particular , one expects that choosing η sufficiently large as to make th e configurations in the subsamp le approxim ately i ndepen dent can be har mful. Indeed , the matrix A 0 contains more in formatio n tha n the stationary distribution of the above p rocess (1), and only the latter can be learned from indepen dent samples. ( iv ) On the o ther h and, le tting η → 0 , one can prod uce an arbitrarily large n umber of distinct samples. Howe ver, samp les become more dependent, and intuiti vely one e x pects that there is limited informatio n t o be harnessed from a giv en time interv al T . Our results confirm in a detailed and quantitative way these intuitions. 1.1 Results: Regularized least squares Regularized least squar es is an efficient an d well-studied me thod for support recovery . W e will discuss relations with existing literature in Section 1.3. In the present case, the alg orithm recon structs independ ently eac h row of the m atrix A 0 . Th e r th row , A 0 r , is estimated by solving the following conv ex optimization problem for A r ∈ R p minimize L ( A r ; { x ( t ) } t ∈ [0 ,T ] ) + λ k A r k 1 , (2) where the likelihood function L is d efined by L ( A r ; { x ( t ) } t ∈ [0 ,T ] ) = 1 2 T Z T 0 ( A ∗ r x ( t )) 2 d t − 1 T Z T 0 ( A ∗ r x ( t )) d x r ( t ) . (3) (Here and below M ∗ denotes the transpose of matrix/vector M .) T o see that th is li kelihood functio n is indeed related to least squares, o ne can formally write ˙ x r ( t ) = d x r ( t ) / d t and complete the square for the right h and side of Eq . (3), thus getting the in tegral R ( A ∗ r x ( t ) − ˙ x r ( t )) 2 d t − R ˙ x r ( t ) 2 d t . The first term is a sum of squ are residu als, and the seco nd is independ ent of A . Finally the ℓ 1 regularization ter m in E q. (2) h as the role of shrinking to 0 a subset of the en tries A ij thus effecti vely selecting the structure. Let S 0 be the support of row A 0 r , an d assume | S 0 | ≤ k . W e will ref er to the vector sign( A 0 r ) as to the signed support of A 0 r (where sign(0) = 0 b y con ventio n). Let λ max ( M ) an d λ min ( M ) stand for 2 the maximum and minimum eigenv alu e of a square matrix M respec ti vely . Furth er , denote by A min the smallest absolute value amon g the non-zero entries of ro w A 0 r . When stable, the diffusion process (1) has a u nique station ary measure which is Ga ussian with covariance Q 0 ∈ R p × p giv en by the solution of L yap unov’ s equation [5] A 0 Q 0 + Q 0 ( A 0 ) ∗ + I = 0 . (4) Our guarantee for regularized least squares is stated in terms of two properties of the covariance Q 0 and on e assumption o n ρ min ( A 0 ) (given a matrix M , we deno te b y M L,R its sub matrix M L,R ≡ ( M ij ) i ∈ L,j ∈ R ): ( a ) W e denote b y C min ≡ λ min ( Q 0 S 0 ,S 0 ) the minimu m eig en value of the restriction of Q 0 to the support S 0 and assume C min > 0 . ( b ) W e defin e the incohe rence parameter α by letting | | | Q 0 ( S 0 ) C ,S 0 Q 0 S 0 ,S 0 − 1 | | | ∞ = 1 − α , and assume α > 0 . (Here | | | · | | | ∞ is the oper ator s up norm. ) ( c ) W e define ρ min ( A 0 ) = − λ max (( A 0 + A 0 ∗ ) / 2) and a ssume ρ min ( A 0 ) > 0 . Note th is is a stronger form of stability assumption. Our main result is to show that there exists a well defined time complexity , i.e. a minimum time interval T such that, ob serving the system for time T ena bles us to reco nstruct the network with high probability . This result is stated in the following t heorem. Theorem 1.1. Consider the pr o blem of lea rning the suppo rt S 0 of r ow A 0 r of the matrix A 0 fr om a sample trajectory { x ( t ) } t ∈ [0 ,T ] distributed accor ding to the model (1). If T > 10 4 k 2 ( k ρ min ( A 0 ) − 2 + A − 2 min ) α 2 ρ min ( A 0 ) C 2 min log 4 pk δ , (5) then there exists λ su ch that ℓ 1 -r egularized least squares recover s the sign ed support o f A 0 r with pr oba bility lar ger than 1 − δ . This is achieved by taking λ = p 36 log(4 p/ δ ) / ( T α 2 ρ min ( A 0 )) . The time comp lexity is logarithm ic in the numb er of variables and polyn omial in the suppor t size. Further, it is r ough ly inv ersely propo rtional to ρ min ( A 0 ) , which is quite satisfying con ceptually , since ρ min ( A 0 ) − 1 controls the relaxation time of the mixes. 1.2 Overview of other r esults So far we focused o n co ntinuo us-time dynamics. While, this is useful in order to obtain elegant state- ments, muc h of the paper is in fact d ev ote d to the analysis of the f ollowing discrete-time dynamics, with parameter η > 0 : x ( t ) = x ( t − 1) + ηA 0 x ( t − 1) + w ( t ) , t ∈ N 0 . (6) Here x ( t ) ∈ R p is the vector collecting the dynamical variables, A 0 ∈ R p × p specifies the dynamics as above, and { w ( t ) } t ≥ 0 is a sequence of i.i.d. normal vectors with covariance η I p × p (i.e. with indepen dent compo nents of variance η ). W e assum e that consecutive samples { x ( t ) } 0 ≤ t ≤ n are giv en and will ask under which conditions regularized least squares recon structs the support of A 0 . The param eter η has the mean ing of a time-step size. The contin uous-time mo del ( 1) is recovered, in a sense made precise below , by letting η → 0 . Ind eed we will prove reco nstruction g uarantees that are un iform in this limit as lo ng as the pr oduct nη (which corre sponds to the time in terval T in the pre vious section) is kept constant. For a formal statement we refer to Theorem 3.1. Theo rem 1.1 is ind eed proved by carefully co ntrolling this limit. T he math ematical challeng e in this p roblem is related to the fundamental fact th at the samples { x ( t ) } 0 ≤ t ≤ n are dependen t (an d strongly depen dent as η → 0 ) . Discrete time mo dels of the fo rm ( 6) can arise eithe r becau se the sy stem und er stud y ev olves by discrete step s, or because we are subsampling a con tinuous time system mo deled as in Eq . (1). Notice that in the latter case the matrices A 0 appearin g in Eq. (6) and (1) coincide only to the zeroth order in η . Neglecting th is tec hnical comp lication, the un iformity of our recon struction guar antees as η → 0 has an ap pealing interp retation already men tioned above. Whenever the samples spacin g is not too large, the time comp lexity (i.e. the pro duct nη ) is rough ly in depend ent of the spacing itself. 3 1.3 Related work A sub stantial amo unt of work has been devoted to the an alysis of ℓ 1 regularized least squares, and its v a riants [6, 7, 8, 9, 10]. Th e most closely related results are the one concernin g h igh-dim ensional consistency f or sup port recovery [ 11, 12]. Our p roof fo llows indeed th e line of work developed in these pape rs, with two imp ortant challenges. First, the desig n matrix is in ou r case prod uced by a stoch astic diffusion, and it d oes no t necessarily satisfies the irrepresen tability con ditions used by these works. Second, the ob servations are not corr upted by i.i.d. noise (since successive configura- tions are correlated) and therefore elementary concentratio n i nequalities are not sufficient. Learning sparse graphical m odels via ℓ 1 regularization is also a top ic with significant literature . In the Gaussian case, the gr a phical LASSO was proposed to reconstruct the model from i.i.d. samples [13]. In th e co ntext o f binary pa irwise graph ical m odels, Ref. [11] p roves h igh-dim ensional con - sistency of regular ized logistic regression for struc tural learnin g, und er a suitab le irr epresentability condition s on a modified covariance. Also this paper focuses on i.i.d. samples. Most of th ese pro ofs builds on the techn ique of [ 12]. A n aiv e adaptation to the pr esent ca se allows to pr ove som e perfo rmance guarantee for the discrete-time setting. However th e resu lting bound s are n ot u niform as η → 0 fo r nη = T fixed. In p articular, they do no t allow to pr ove an analogo us of our co ntinuou s time result, Theo rem 1.1. A large p art of our effort is dev oted to pro ducing more accurate probab ility estimates that capture the corr ect scaling for small η . Similar issues were explored in the study of stochastic differential e quations, whereb y o ne is often interested in tracking some slow degrees of f reedom wh ile ‘av eraging ou t’ the fast ones [14]. T he relev an ce of this time-scale sep aration for lear ning was addre ssed in [15]. L et us howe ver emp hasize that these works focus once more on system with a fixed (small) number of dimensions p . Finally , the related topic of lear ning gra phical m odels fo r auto regressiv e processes was studied re- cently in [16, 17]. The convex relaxation proposed in these pap ers is different fr om the o ne devel- oped here. Furth er , no model selection guaran tee w as proved in [16, 17]. 2 Illustration of the main r esults It might be d ifficult to get a clear intuition of T heorem 1 .1, mainly because of conditions ( a ) and ( b ) , which intro duce parameters C min and α . The same d ifficulty arises w ith analogo us results on the high-d imensional consistency of the LASSO [11, 12]. In this section we provide c oncrete illustration both via numer ical simulations, and by checkin g the condition on specific class es of grap hs. 2.1 Learning the laplacian of graphs with bounded degree Giv en a simple gra ph G = ( V , E ) o n vertex set V = [ p ] , its laplacian ∆ G is the symm etric p × p matrix which is equ al to the adjacen cy matrix of G o utside the diagon al, and with en tries ∆ G ii = − deg( i ) on the diagonal [18]. (Here deg( i ) deno tes the degree of vertex i .) It is well known that ∆ G is negative semidefinite, with one eigen value equal to 0 , whose multiplicity is equa l to the n umber of conne cted com ponen ts o f G . The matrix A 0 = − m I + ∆ G fits into the setting o f Theorem 1 .1 for m > 0 . T he correspon ding m odel ( 1.1) describes the over-damped dynamics o f a network of masses co nnected by sprin gs o f u nit streng th, a nd conn ected by a spr ing of strength m to the origin. W e ob tain the following result. Theorem 2.1 . Let G be a simple conn ected graph o f maximum v erte x degr ee k a nd c onsider the model (1.1) with A 0 = − m I + ∆ G wher e ∆ G is the laplacian of G and m > 0 . If T ≥ 2 · 10 5 k 2 k + m m 5 ( k + m 2 ) log 4 pk δ , (7) then there exists λ su ch that ℓ 1 -r egularized least squares recover s the sign ed support o f A 0 r with pr oba bility lar ger than 1 − δ . This is achieved by taking λ = p 36( k + m ) 2 log(4 p/δ ) / ( T m 3 ) . In other word s, for m bound ed away from 0 an d ∞ , regularized least squar es regre ssion corr ectly reconstruc ts the gra ph G fr om a trajector y of time len gth wh ich is poly nomial in the degree and logarithm ic in th e sy stem size. Notice th at o nce the graph is known, the lap lacian ∆ G is uniquely determined . Also, the proof technique used for this examp le is generalizab le to other graphs as well. 4 0 50 100 150 200 250 300 350 400 450 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 T = n η Probability of success p = 16 p = 32 p = 64 p = 128 p = 256 p = 512 10 1 10 2 10 3 1200 1400 1600 1800 2000 2200 2400 2600 2800 p Min. # of samples for success prob. = 0.9 Figure 1: ( left) Probability of success vs. length of the observation interval nη . (right) Sample complexity for 90% probability of success vs. p. 2.2 Numerical illustrations In th is section we present numerical validation o f the pro posed meth od on synthetic data. T he resu lts confirm our observations in Theo rems 1.1 and 3. 1, b elow , na mely that the time com plexity scales logarithm ically with th e number of n odes in th e network p , g iv en a con stant ma ximum d egree. Also, the time comp lexity is roughly indepen dent of the samp ling rate. In Fig. 1 and 2 we co nsider the d iscrete-time setting, generating data as follows. W e dr aw A 0 as a ran dom sparse m atrix in { 0 , 1 } p × p with elements chosen indepen dently at rando m with P ( A 0 ij = 1) = k /p , k = 5 . Th e process x n 0 ≡ { x ( t ) } 0 ≤ t ≤ n is then gener ated accordin g to Eq. (6). W e solve the r egularized least square pr oblem (the cost function is gi ven explicitly in Eq. (8) for th e discre te-time case) for different values of n , the number of observations, and record if the corr ect support is recovered for a random row r using the optimum value of the p arameter λ . An estimate of the pr obability of succ essful recovery is o btained by repeating this experiment. Note th at we ar e estimatin g here an av erage probab ility of success over randomly generated matrices. The left p lot in Fig .1 depicts the pro bability of success vs. nη for η = 0 . 1 and d ifferent values of p . Ea ch cur ve is o btained using 2 11 instances, and eac h instance is gene rated using a n ew rando m matrix A 0 . The righ t plot in Fig.1 is the cor respond ing curve of the samp le comp lexity vs. p where sample co mplexity is defined a s the minimum value of nη with pro bability of success o f 90 %. As predicted by Theorem 2.1 the curve shows the logarithm ic scaling of the sample complexity with p . In Fig. 2 we turn to the contin uous-time mode l (1). T rajectories are generated by discretizing this stochastic dif ferential equation with step δ much s maller than the sampling rate η . W e draw random matrices A 0 as abov e and plot the probability of success for p = 16 , k = 4 an d dif fer ent values o f η , as a fun ction of T . W e used 2 11 instances for each cu rve. As pre dicted by Theor em 1.1, fo r a fixed observation interval T , the prob ability of success con verges to some limiting value as η → 0 . 3 Discre te-time model: Statement o f the re sults Consider a system evolving in discrete time accor ding to the m odel (6), an d let x n 0 ≡ { x ( t ) } 0 ≤ t ≤ n be the o bserved portion o f th e trajectory . The r th row A 0 r is estimated by so lving th e following conv ex optimization problem for A r ∈ R p minimize L ( A r ; x n 0 ) + λ k A r k 1 , (8) where L ( A r ; x n 0 ) ≡ 1 2 η 2 n n − 1 X t =0 { x r ( t + 1) − x r ( t ) − η A ∗ r x ( t ) } 2 . (9) Apart f rom an ad ditive constan t, the η → 0 limit of this co st fun ction can be shown to coincide with the cost function in the continuou s tim e case, cf. Eq. (3). Indeed the proof of Theorem 1.1 will amount to a mo re precise version of this statement. Further more, L ( A r ; x n 0 ) is easily seen to be the log-likelihood of A r within model (6). 5 0 50 100 150 200 250 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 T = n η Probability of success η = 0.04 η = 0.06 η = 0.08 η = 0.1 η = 0.14 η = 0.18 η = 0.22 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2 0.22 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1 η Probability of success Figure 2: (right)Pr obability of success vs. len gth of the ob servation interval nη fo r different values of η . (left) Probability o f success vs. η for a fixed len gth of the observation inter val, ( nη = 150 ) . The process is generated for a small value of η an d sampled at different rates. As before, we let S 0 be the suppo rt of row A 0 r , and assum e | S 0 | ≤ k . Under the mo del (6) x ( t ) has a Gaussian stationary state distribution with covariance Q 0 determined by the following m odified L yapun ov equation A 0 Q 0 + Q 0 ( A 0 ) ∗ + η A 0 Q 0 ( A 0 ) ∗ + I = 0 . (10) It will be clear from the co ntext wheth er A 0 / Q 0 refers to the dy namics/stationary m atrix from the continuo us or discrete tim e system. W e assume co nditions ( a ) and ( b ) introdu ced in Section 1.1, an d adopt the notations alrea dy introdu ced there. W e use as a shorthand notatio n σ max ≡ σ max ( I + η A 0 ) where σ max ( . ) is the maxim um singular value. Also define D ≡ 1 − σ max /η . W e will assume D > 0 . As in the previous section, we assume the mode l (6) is initiated in the stationary state. Theorem 3 .1. Consider th e pr ob lem of learning the suppo rt S 0 of r o w A 0 r fr om th e discrete-time trajectory { x ( t ) } 0 ≤ t ≤ n . If nη > 10 4 k 2 ( k D − 2 + A − 2 min ) α 2 D C 2 min log 4 pk δ , (11) then there exists λ su ch that ℓ 1 -r egularized least squares recover s the sign ed support o f A 0 r with pr oba bility lar ger than 1 − δ . This is achieved by taking λ = p (36 lo g(4 p/δ )) / ( Dα 2 nη ) . In other words the discrete-time sample complexity , n , is logarithmic in the model dimension, poly- nomial in the maximu m n etwork degree and inversely p ropo rtional to the time sp acing between samples. The last point is par ticularly imp ortant. It enables us to derive th e bound on the c ontinuo us- time sample comp lexity as the limit η → 0 of the discrete-time sample comp lexity . It also confir ms our intuition m entioned in the Introd uction: although one can prod uce an a rbitrary large number of sample s by sampling the continu ous p rocess with finer resolution s, ther e is limited a mount of informa tion that can be harnessed from a given time interval [0 , T ] . 4 Pr oofs In th e fo llowing we denote by X ∈ R n × p the ma trix whose ( t + 1) th column c orrespon ds to the configur ation x ( t ) , i.e. X = [ x (0) , x (1) , . . . , x ( n − 1 )] . Fu rther ∆ X ∈ R n × p is the matrix contain - ing config uration ch anges, na mely ∆ X = [ x (1) − x (0) , . . . , x ( n ) − x ( n − 1)] . Finally we write W = [ w (1) , . . . , w ( n − 1)] fo r the matrix containing the Gaussian noise realization. Equivalently , W = ∆ X − η A X . The r th row of W is deno ted by W r . In or der to lighten th e no tation, we will omit th e refer ence to x n 0 in the likelihood fun ction (9) an d simply write L ( A r ) . W e de fine its normalized gradient and Hessian by b G = − ∇ L ( A 0 r ) = 1 nη X W ∗ r , b Q = ∇ 2 L ( A 0 r ) = 1 n X X ∗ . (12) 6 4.1 Discrete time In this Sec tion we ou tline our prove fo r our main result for discrete-time dyn amics, i.e., Theorem 3.1. W e start by stating a set of su fficient conditions for regularized least squares to work. Then we present a series of concentratio n lemm as to be used to prove the validity o f these conditio ns, an d finally we sketch the outline of the proof. As mentioned, the proo f strategy , and in particular the following prop osition which provides a com- pact set o f sufficient con ditions fo r th e sup port to be recovered correctly is an alogou s to the on e in [12]. A pr oof of this proposition can be found in the supplementary material. Proposition 4.1. Let α, C min > 0 be be defi ned by λ min ( Q 0 S 0 ,S 0 ) ≡ C min , | | | Q 0 ( S 0 ) C ,S 0 Q 0 S 0 ,S 0 − 1 | | | ∞ ≡ 1 − α . (13) If the following c ondition s ho ld the n th e r e g ularized least squ ar e solu tion (8) co rr ectly r ecover the signed suppo rt sign( A 0 r ) : k b G k ∞ ≤ λα 3 , k b G S 0 k ∞ ≤ A min C min 4 k − λ, (14) | | | b Q ( S 0 ) C ,S 0 − Q 0 ( S 0 ) C ,S 0 | | | ∞ ≤ α 12 C min √ k , | | | b Q S 0 ,S 0 − Q 0 S 0 ,S 0 | | | ∞ ≤ α 12 C min √ k . (15) Further the same stateme nt holds for the co ntinuou s model 3, pr ovided b G and b Q ar e the gradient and the hessian of the likelihood (3). The proo f of Theorem 3.1 co nsists in check ing that, unde r the hypo thesis (11) on the nu mber of consecutive configuration s, conditions ( 14) to (15) will h old with high pro bability . Chec king th ese condition s can be regarded in turn as concentratio n-of- measure statements. Ind eed, if expectation is taken with respect to a stationary trajectory , we ha ve E { b G } = 0 , E { b Q } = Q 0 . 4.1.1 T echnical lemmas In th is section we will state the necessary co ncentra tion lemmas for proving Theorem 3. 1. These are n on-trivial b ecause b G , b Q are quad ratic functio ns of dep enden t random variables the samp les { x ( t ) } 0 ≤ t ≤ n . The pro ofs of Proposition 4.2, of Proposition 4.3, and Corollary 4.4 can be f ound in the supplementa ry material provided. Our first Proposition implies concen tration of b G aroun d 0 . Proposition 4.2. Let S ⊆ [ p ] b e a ny set of vertices and ǫ < 1 / 2 . If σ max ≡ σ max ( I + η A 0 ) < 1 , then P k b G S k ∞ > ǫ ≤ 2 | S | e − n (1 − σ max ) ǫ 2 / 4 . (16) W e furtherm ore nee d to bo und the matrix no rms as per (15) in pr oposition 4.1. First we relate bound s on | | | b Q J S − Q 0 J S | | | ∞ with boun ds on | b Q ij − Q 0 ij | , ( i ∈ J, i ∈ S ) wh ere J and S are any subsets of { 1 , ..., p } . W e have, P ( | | | b Q J S − Q 0 J S ) | | | ∞ > ǫ ) ≤ | J || S | max i,j ∈ J P ( | b Q ij − Q 0 ij | > ǫ / | S | ) . (17) Then, we boun d | b Q ij − Q 0 ij | using the following proposition Proposition 4.3. Let i, j ∈ { 1 , ..., p } , σ max ≡ σ max ( I + η A 0 ) < 1 , T = η n > 3 /D a nd 0 < ǫ < 2 /D where D = (1 − σ max ) /η then, P ( | b Q ij − Q 0 ij ) | > ǫ ) ≤ 2 e − n 32 η 2 (1 − σ max ) 3 ǫ 2 . (18) Finally , the next corollary follo ws from Propo sition 4.3 and Eq. (17). Corollary 4.4. Let J , S ( | S | ≤ k ) be any two subsets of { 1 , ..., p } and σ max ≡ σ max ( I + η A 0 ) < 1 , ǫ < 2 k /D a nd nη > 3 / D (wher e D = (1 − σ max ) /η ) the n, P ( | | | b Q J S − Q 0 J S | | | ∞ > ǫ ) ≤ 2 | J | ke − n 32 k 2 η 2 (1 − σ max ) 3 ǫ 2 . (19) 7 4.1.2 Outline of the proof of Theorem 3.1 W ith these concentratio n bou nds we ca n now easily p rove Theorem 3.1. All we need to do is to co mpute the prob ability that the co nditions g i ven by Proposition 4 .1 hold . Fro m the statement of the th eorem we have that th e first two condition s ( α, C min > 0 ) o f Propo sition 4.1 hold. In order to make th e first condition on b G im ply the second condition on b G we assume that λα/ 3 ≤ ( A min C min ) / (4 k ) − λ which is guarante ed to ho ld if λ ≤ A min C min / 8 k . (20) W e also comb ine the tw o last conditions on b Q , thus obtaining the following | | | b Q [ p ] ,S 0 − Q 0 [ p ] ,S 0 | | | ∞ ≤ α 12 C min √ k , (21) since [ p ] = S 0 ∪ ( S 0 ) C . W e th en impose that both the probability of the condition on b Q failing and the p robability of the condition on b G failing are upper bo unded by δ / 2 using Prop osition 4.2 and Corollary 4.4. It is shown in the supplem entary material that this is satisfied if condition (11) holds. 4.2 Outline of the proof of Theorem 1.1 T o prove Theore m 1.1 we recall that Proposition 4.1 holds provided the appropr iate con tinuou s time expressions are used for b G and b Q , namely b G = −∇L ( A 0 r ) = 1 T Z T 0 x ( t ) d b r ( t ) , b Q = ∇ 2 L ( A 0 r ) = 1 T Z T 0 x ( t ) x ( t ) ∗ d t . (22) These are of co urse rando m variables. In order to distinguish these from th e discrete time version, we will adopt the notation b G n , b Q n for the latter . W e claim th at these r andom variables can be coupled (i.e. defined on the same p robability space) in such a way th at b G n → b G and b Q n → b Q almost surely as n → ∞ fo r fixed T . Und er assumption (5), it is easy to show that (11) holds for all n > n 0 with n 0 a sufficiently large con stant (for a pr oof see the provided sup plementar y material). Therefo re, by the pro of of Th eorem 3.1, the cond itions in Propo sition 4.1 hold for grad ient b G n and hessian b Q n for any n ≥ n 0 , with prob ability larger tha n 1 − δ . But by the claimed conv ergence b G n → b G an d b Q n → b Q , they hold also for b G and b Q with pro bability at least 1 − δ which proves the theorem. W e are left with the task of showing that the discrete and continuo us time processes can be coupled in such a way that b G n → b G and b Q n → b Q . With slight abuse of no tation, th e state of the discrete time system (6) will be denoted by x ( i ) wh ere i ∈ N an d the state of continu ous time system (1) by x ( t ) where t ∈ R . W e deno te by Q 0 the solution of (4) and by Q 0 ( η ) the solution of (10). It is easy to check that Q 0 ( η ) → Q 0 as η → 0 by the uniqu eness of stationary state distrib u tion. The initial state of the c ontinuo us time system x ( t = 0) is a N (0 , Q 0 ) random variable inde- penden t of b ( t ) and the in itial state of the discrete time system is defined to be x ( i = 0) = ( Q 0 ( η )) 1 / 2 ( Q 0 ) − 1 / 2 x ( t = 0) . At subsequen t times, x ( i ) and x ( t ) are assumed are genera ted by the respective dynam ical systems using the same matrix A 0 using common randomness provided b y the standard Brownian motion { b ( t ) } 0 ≤ t ≤ T in R p . In order to couple x ( t ) and x ( i ) , we con struct w ( i ) , the noise driving the discrete ti me system, by letting w ( i ) ≡ ( b ( T i/n ) − b ( T ( i − 1) /n )) . The almost sure conver gence b G n → b G and b Q n → b Q follows then fr om standard convergence of random walk to Bro wnian motion. Acknowledgmen ts This w ork w as partially suppor ted by a T erman fellowship, the NSF CAREER award CCF-0743978 and the NSF grant DMS-0806 211 and by a Portugu ese Doctoral FC T fellowship. 8 Refer ences [1] D.T . Gillespie. Stochastic simulation of c hemical kin etics. Annual Review of Phy sical Chem- istry , 58:35– 55, 2007 . [2] D. Higham . Mod eling and Simulating Chemical Reactions. S IAM Review , 50:34 7–368 , 2 008. [3] N.D.L awrence et al., e ditor . Lea rning and I nfer ence in Comp utationa l Systems Biology . MIT Press, 2010 . [4] T . T on i, D. W elch, N. Strelkova, A. Ipsen, and M.P .H. Stump f. Modeling and Simulating Chemical Reactions. J. R. Soc. Interface , 6:187 –202 , 2009. [5] K. Zho u, J.C. Doyle, and K. Glov er . Robust and optimal contr ol . Prentice Hall, 1996. [6] R. T ibshirani. Regression shrinkage a nd selection via the lasso. Journal of the Royal Statistical Society . Series B (Methodo logical) , 58(1):26 7–28 8, 199 6. [7] D.L. Don oho. For mo st la rge under determin ed systems of equ ations, the m inimal l1-no rm near-solution app roximates th e sparsest n ear-solution. Communica tions on Pur e and Ap plied Mathematics , 59(7):9 07–93 4, 200 6. [8] D.L. Do noho . For most large und erdeterm ined systems of linear equation s th e minim al l1- norm solution is als o the sparsest solution . Communica tions on Pure and Applied Mathe matics , 59(6) :797–8 29, 20 06. [9] T . Zhang. Som e sharp performan ce bo unds for least squares regression with L1 regularization. Annals of Statistics , 37:210 9–21 44, 20 09. [10] M .J. W ainwright. Sharp threshold s for high-dime nsional and noisy sparsity recovery using l1- constrained quadratic prog ramming (Lasso). IEEE T rans. Information Theory , 55:21 83–22 02, 2009. [11] M .J. W ainwright, P . Ra vikumar, and J.D. Laf f erty . High-Dimension al Graphical Model Selec- tion Using l-1- Regularized Logistic Regression. Adv ances in Neural Information Pr ocessing Systems , 19:1465 , 2007 . [12] P . Zhao an d B. Y u. On model selectio n consistency of Lasso. The J ou rnal of Machine Learn ing Resear ch , 7:254 1–25 63, 2006. [13] J. Friedman, T . Hastie, and R. T ib shirani. Sp arse inv erse c ovariance estimation with th e graph - ical lasso. B iostatistics , 9(3) :432, 2008 . [14] K. Ball, T . G. Kurtz, L . Popovic, an d G. Rempala. Modeling an d Simulating Chem ical Reac- tions. Ann. Appl. Pr ob. , 16:19 25–1 961, 2 006. [15] G. A. Pa vliotis and A.M. Stua rt. Parameter estimation f or multiscale diffusions. J. Stat. Phys. , 127:74 1–78 1, 2 007. [16] J. Songsiri, J. Dahl, and L. V andenberghe. Graphical m odels o f au toregressiv e pr ocesses. pages 89–11 6, 2010. [17] J. Songsiri and L. V andenberghe. T o polog y selection in g raphical mo dels of autoregressive processes. Journal of M achine Learning Resear ch , 2010. sub mitted. [18] F .R.K. Chung. Spec tral Graph Theory . CBMS Regional Conferen ce Ser ies in M athematics, 1997. [19] P . Ravikumar , M. J. W ainwright, and J. Lafferty . High- dimension al Ising model selectio n using l1-regularized logistic re gression. A nnals of Statistics , 2008. 9 A Learning netw o rks of stochastic differe ntial equations: Supplementary materials In order to prove Proposition 4.1 we first introdu ce two technical lemmas. Lemma A.1. F or any subset S ⊆ [ p ] the following decomp osition holds, b Q S C ,S b Q S,S − 1 = T 1 + T 2 + T 3 + Q 0 S C ,S Q 0 S,S − 1 , (23) wher e, T 1 = Q 0 S C ,S b Q S,S − 1 − Q 0 S,S − 1 , (24) T 2 = ( b Q S C ,S − Q 0 S C ,S ) Q 0 S,S − 1 , (25) T 3 = ( b Q S C ,S − Q 0 S C ,S ) b Q S,S − 1 − Q 0 S,S − 1 . ( 26) (27) In addition , if | | | Q 0 S C ,S Q 0 S,S − 1 | | | ∞ < 1 an d λ min ( b Q S,S ) ≥ C min / 2 > 0 the fo llowing relations hold, | | | T 1 | | | ∞ ≤ 2 √ k C min | | | b Q S,S − Q 0 S,S | | | ∞ , (28) | | | T 2 | | | ∞ ≤ √ k C min | | | b Q S C ,S − Q 0 S C ,S | | | ∞ , (29) | | | T 3 | | | ∞ ≤ 2 √ k C 2 min | | | b Q S C ,S − Q 0 S C ,S | | | ∞ | | | b Q S,S − Q 0 S,S | | | ∞ . (30) The following lem ma taken fr om the proo fs of Pro position 1 in [19] and Pro position 1 in [12] respectively is the crux to guarantee ing correct signed-supp ort reconstruction of A 0 r . Lemma A. 2. If b Q S 0 ,S 0 > 0 , then the dual vector ˆ z fr om the KKT condition s of the optimization pr oblem (8) satisfies the following ineq uality , k ˆ z ( S 0 ) C k ∞ ≤ | | | b Q ( S 0 ) C ,S 0 b Q S 0 ,S 0 − 1 | | | ∞ 1 + k b G S 0 k ∞ λ ! + k b G ( S 0 ) C k ∞ λ . (31) In addition , if k b G S 0 k ∞ ≤ A min λ min ( b Q S 0 ,S 0 ) 2 k − λ (32) then k A 0 r − ˆ A r k ∞ ≤ A min / 2 . The same r e sult holds for pr oblem (2) . Proof o f Proposition 4. 1: T o guarantee tha t o ur estimated suppor t is at least con tained in the true support we need to impose that k ˆ z S C k ∞ < 1 . T o guarantee that we do not introduce e xtra elements in estimating the sup port and also to determine the correct sign of the solution we need to impose that k A 0 r − ˆ A r k ∞ ≤ A min / 2 . Now notice that since λ min ( Q 0 S 0 ,S 0 ) = C min the relation λ min ( b Q S 0 ,S 0 ) ≥ C min / 2 is g uarantee d as lon g as | | | b Q S 0 ,S 0 − Q 0 S 0 ,S 0 | | | ∞ ≤ C min / 2 . Using Lemm a A.1 it is easy to see that the boun ds of Propo sition 4.1 lead to the conditions of Lem ma A.2 b eing verified. Thu s, these lead to a correct recovery of the signed structure of A 0 r . Lemma A.3. Let r , j ∈ [ p ] and let ρ ( τ ) r epr e sent a p × p matrix with all r ows eq ual to zer o except the r th r ow which eq uals the j th r ow of ( I + η A 0 ) τ (the τ th power of I + η A 0 ). Let 10 ˜ R ( j ) ∈ R ( n + m +1) × ( n + m +1) be defined as, ˜ R = 0 0 . . . 0 0 0 . . . 0 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . 0 0 . . . 0 0 0 . . . 0 0 ρ ( m ) ρ ( m − 1) . . . ρ (1) ρ (0) 0 . . . 0 0 ρ ( m + 1) ρ ( m ) . . . ρ (2) ρ (1) ρ (0) . . . 0 0 . . . . . . . . . . . . . . . . . . . . . 0 0 ρ ( m + n − 1) ρ ( m + n − 2) . . . ρ ( n ) ρ ( n − 1) ρ ( n − 2) . . . ρ (0) 0 . (33) Define R ( j ) = 1 / 2( ˜ R + ˜ R ∗ ) and let ν i denote its i th eigen va lue a nd assume σ max ≡ σ max ( I + η A 0 ) < 1 . Then, p ( n + m +1) X i =1 ν i = 0 , (34) max i | ν i | ≤ 1 1 − σ max , (35) p ( n + m +1) X i =1 ν 2 i ≤ 1 2 n 1 − σ max . (36) Pr oof. First it is immed iate to see that P p ( n + m +1) i =1 ν i = T r ( R ) = 0 . Let I 1 τ represent a p × p matrix with zer os everywhere and ones in the blo ck-position where ρ ( τ ) ap pears and I 2 τ represent a similar matrix but with ones in the block-p osition where ρ ( τ ) ∗ appears. Then R can be written as, R = 1 2 m + n − 1 X τ =0 I 1 τ ⊗ ρ ( τ ) + I 2 τ ⊗ ρ ( τ ) ∗ ! , (37) where ⊗ denotes th e Kronecker prod uct of matric es. This expression can be used to c ompute an upper boun d on | ν i | . Namely , max i | ν i | = σ max ( R ) ≤ ∞ X τ =0 σ max ( I 1 τ ⊗ ρ ( τ )) ≤ ∞ X τ =0 σ max ( I 1 τ ) σ max ( ρ ( τ )) (38) ≤ ∞ X τ =0 σ max ( ρ ( τ )) ≤ ∞ X τ =0 σ τ max = 1 1 − σ max ( ϕ ∗ ) . (39) For the other bound we do, ( n + m +1) p X i =1 ν 2 i = T r ( R 2 ) ≤ 1 4 n 2 ∞ X τ =0 T r ( ρ ( τ ) ρ ( τ ) ∗ ) (40) = 1 2 n ∞ X τ =0 k ρ ( τ ) k 2 2 (41) ≤ 1 2 n ∞ X τ =0 σ 2 τ max ≤ 1 2 n 1 − σ max , (42) where in the last step we used the fact that 0 ≤ σ max < 1 . Lemma A. 4. Let j ∈ [ p ] . Define ρ ( τ ) ∈ R 1 × p to be the j th r ow of ( I + η A 0 ) τ . Let Φ j ∈ R n × ( n + m ) be defined as, Φ j = ρ ( m ) ρ ( m − 1) . . . ρ (1) ρ (0) 0 . . . 0 ρ ( m + 1) ρ ( m ) . . . ρ (2) ρ (1) ρ (0) . . . 0 . . . . . . . . . . . . . . . . . . . . . 0 ρ ( m + n − 1 ) ρ ( m + n − 2) . . . ρ ( n ) ρ ( n − 1) ρ ( n − 2) . . . ρ (0) , (43) 11 Let ν l denote the l th eigen va lue o f the matrix R ( i, j ) = 1 / 2(Φ ∗ j Φ i + Φ ∗ i Φ j ) ∈ R ( n + m ) × ( n + m ) (wher e i ∈ [ p ] ) an d assume σ max ≡ σ max ( I + η A 0 ) < 1 then, | ν l | ≤ 1 (1 − σ max ) 2 , (44) 1 n ( n + m ) p X l =1 ν 2 l ≤ 2 (1 − σ max ) 3 1 + 3 2 n 1 1 − σ max . (45) Pr oof. The first bou nd can be pr oved in a trivial man ner . In fact, since fo r any matrix A and B we have σ max ( A + B ) ≤ σ max ( A ) + σ max ( B ) and σ max ( AB ) ≤ σ max ( A ) σ max ( B ) we can write max l | ν l | = σ max (1 / 2(Φ ∗ j Φ i + Φ ∗ i Φ j )) ≤ 1 / 2( σ max (Φ ∗ j Φ i ) + σ max (Φ ∗ i Φ j )) ( 46) ≤ σ max (Φ ∗ i Φ j ) ≤ σ max (Φ i ) σ max (Φ j ) ≤ 1 (1 − σ max ) 2 , (47) where in the last ineq uality we used the fact σ max (Φ j ) ≤ 1 / (1 − σ max ) . The pr oof of th is is just a copy of the proof of the bound (35) in Lemma A.3. Before we prove the secon d bou nd let us introdu ce some no tation to differentiate ρ ( τ ) associated with Φ j from ρ ( τ ) associated with Φ i . Let us call them ρ ( τ , j ) and ρ ( τ , i ) r espectively . Now notice that Φ ∗ i Φ j can be written as a block matrix ˜ A ˜ D ˜ C ˜ B (48) where ˜ A, ˜ B , ˜ C and ˜ D are matrix b locks wh ere each block is a p by p matrix. ˜ A has p × p block s, ˜ B has n × n blocks, ˜ C has n × m block s and ˜ D h as m × n block s. If we ind ex the blocks of each matrix with the indices x, y these can be describe d in the following way ˜ A xy = m X s =1 ρ ( m − x + s, i ) ∗ ρ ( m − y + s, j ) (49) ˜ B xy = n − x X s =0 ρ ( s, i ) ∗ ρ ( s + x − y , j ) , x ≥ y (50) ˜ B xy = n − y X s =0 ρ ( s + y − x, i ) ∗ ρ ( s, j ) , x ≤ y (51) ˜ C xy = n − x X s =0 ρ ( s, i ) ∗ ρ ( m − y + x + s, j ) (52) ˜ D xy = n − y X s =0 ρ ( m − x + y + s, i ) ∗ ρ ( s, j ) . (53) W ith this in mind and d enoting by A, B , C and D the symme trized versions of these same matrices (e.g.: A = 1 / 2( ˜ A + ˜ A ∗ ) ) we can write, ( n + m ) p X l =1 ν 2 l = T r ( R ( i, j ) 2 ) = T r ( A 2 ) + T r ( B 2 ) + 2 T r ( C D ) . (54) W e now co mpute a boun d f or each one of the terms. W e exemplify in detail th e c alculation of the first bound only . First write, T r ( A 2 ) = m X x =1 m X y =1 T r ( A xy A ∗ xy ) . (55) 12 Now notice that each T r ( A xy A ∗ xy ) is a sum over τ 1 , τ 2 ∈ [ p ] of term s of the type, ( ρ ( m − x + τ 1 , i ) ∗ ρ ( m − y + τ 1 , j ) + ρ ( m − x + τ 1 , j ) ∗ ρ ( m − y + τ 1 , i )) × (56) × ( ρ ( m − y + τ 2 , j ) ∗ ρ ( m − x + τ 2 , i ) + ρ ( m − y + τ 2 , i ) ∗ ρ ( m − x + τ 2 , j )) . (57) The trace of a matrix of this type can be easily upper boun ded by ( σ max ) m − x + τ 1 + m − y + τ 1 + m − y + τ 2 + m − x + τ 2 = ( σ max ) 2( m − x )+2( m − y )+2 τ 1 +2 τ 2 (58) which finally leads to T r ( A 2 ) ≤ 1 (1 − σ max ) 4 . (59) Doing a similar thing to the other terms leads to T r ( B 2 ) ≤ n,n X x,y X τ 1 ,τ 2 σ 2 τ 1 +2 τ 2 +2 | x − y | max ≤ 2 n (1 − σ max ) 3 (60) T r ( D C ) = m X x =1 n X y =1 T r ( C xy D y x ) ≤ m,n,n − y ,n − y X x,y ,τ 1 ,τ 2 σ 2( m − x )+2 y +2 τ 1 +2 τ 2 max ≤ 1 (1 − σ max ) 4 . (61) Putting all these together leads to the desired bound . Proof of Proposition 4 .2: W e will start b y provin g th at this exact same b ound holds wh en th e probab ility of the e vent {k b G S k ∞ > ǫ } is c omputed with respect to a trajecto ry { x ( t ) } n t =0 that is initiated at in stant t = − m with the value w ( − m ) . In oth er words, x ( − m ) = w ( − m ) . Assume we have do ne so. Now no tice that as m → ∞ , X conver ges in distribution to n consecutive samples fr om the mo del (6) wh en this is initiated from stationary state. Since k b G S k ∞ is a continuo us function o f X = [ x (0) , ..., x ( n − 1)] , b y the Continu ous Map ping Theo rem, k b G S k ∞ conv erges in distribution to the co rrespon ding rando m variable in the case when the tra jectory { x ( i ) } n i =0 is initiated fro m stationary state. Since the p robab ility bound does no t depen d on m we have that this same bound holds for stationary trajectories too. W e n ow prove our claim. Recall that b G j = ( X j W ∗ r ) / ( nη ) . Since X is a lin ear fu nction o f th e in- depend ent gaussian rand om variables W we can write X j W ∗ r = η z ∗ R ( j ) z , where z ∈ R p ( n + m +1) is a vector of i.i.d. N (0 , 1) ra ndom variables and R ( j ) ∈ R p ( n + m +1) × p ( n + m +1) is the sy mmetric matrix defined in Lemma A.3. Now apply the standar d Bernstein method. First b y union bound we have P k b G S k ∞ > ǫ ≤ 2 | S | max j ∈ S P z ∗ R ( j ) z > nǫ . Next denoting by { ν i } 1 ≤ i ≤ p ( n + m +1) the eigenv alues of R ( j ) , we hav e, for any γ > 0 , P z ∗ R ( j ) z > nǫ = P n p ( n + m +1) X i =1 ν i z 2 i > nǫ o ≤ e − nγ ǫ p ( n + m +1) Y i =1 E e γ ν i z 2 i = exp − n γ ǫ + 1 2 n ( n + m +1) p X i =1 log(1 − 2 ν i γ ) . Let γ = 1 2 (1 − σ max ) ǫ . Using the bou nd obtained for | max i ν i | in Eq. (35), Lemma A.3, | 2 ν i γ | ≤ ǫ . Now notice tha t if | x | < 1 / 2 then log(1 − x ) > − x − x 2 . Thus, if we assum e ǫ < 1 / 2 and given 13 that P ( n + m +1) p i =1 ν i = 0 (see Eq. (3 4)) we can continue the chain of inequalities, P ( k b G S k ∞ > ǫ ) ≤ 2 | S | ma x j exp − n ( γ ǫ − 2 γ 2 1 n ( n + m +1) p X i =1 ν 2 i ) (62) ≤ 2 | S | exp − n ( 1 2 (1 − σ max ) ǫ 2 − 1 4 (1 − σ max ) 2 ǫ 2 (1 − σ max ) − 1 ) (63) ≤ 2 | S | exp − n 4 (1 − σ max ) ǫ 2 . (64) where the second inequality is obtained using the boun d i n Eq. (36). Proof of Proposition 4.3: T he proo f is very similar to that of pro position 4.2. W e will fir st show that the bound P ( | b Q ij − E ( b Q ij ) | > ǫ ) ≤ 2 e − n 32 η 2 (1 − σ max ) 3 ǫ 2 , (65) holds in the case wh ere the probability measure and expectation are taken with respect to trajectories { x ( i ) } n i =0 that started at time instant t = − m with x ( − m ) = w ( − m ) . Assume we have do ne so. Now notice that as m → ∞ , X conv erges in distribution to n co nsecutive samples from the mo del 6 when this is initiated from stationary state. In addition , as m → ∞ , we have from lemma A.5 that E ( b Q ij ) → Q 0 ij . Since b Q ij is a continuous functio n o f X = [ x (0) , ..., x ( n − 1)] , a simple application of the Con tinuous Map ping Th eorem plus th e fact that the upp er bou nd is continu ous in ǫ leads u s to conclude that the bound also holds when the system is initiated from stationary state. T o prove our pre v ious statement first recall the definition of b Q and notice that we can write, b Q ij = η n z ∗ R ( i, j ) z , (66) where z ∈ R m + n is a vector of i.i.d. N (0 , 1) an d R ( i, j ) ∈ R ( n + m ) × ( n + m ) is defined has in l emma A.4. Letting ν l denote the l th eigenv alue of the symmetric matrix R ( i, j ) we can fur ther write, b Q ij − E ( b Q ij ) = η n ( n + m ) p X l =1 ν l ( z 2 l − 1) . (6 7) By Lemma A.4 we know that, | ν l | ≤ 1 (1 − σ max ) 2 , (68) 1 n ( n + m ) p X l =1 ν 2 l ≤ 2 (1 − σ max ) 3 1 + 3 2 n 1 1 − σ max ≤ 3 (1 − σ max ) 3 , (69) where we applied T > 3 /D in the last line. Now we ar e do ne since a pplying Bernstein trick, this time with γ = 1 / 8 (1 − σ max ) 3 ǫ/η , and m aking again use of the fact that log(1 − x ) > − x − x 2 for | x | < 1 / 2 we get, P ( b Q ij − E ( b Q ij ) > ǫ ) = P ( ( n + m ) p X l =1 ν l ( z 2 l − 1) > ǫn / η ) (70) ≤ e − γ ǫn η e − γ P ( n + m ) p l =1 ν l + e − 1 / 2 P ( m + n ) p l =1 log(1 − 2 γ ν l ) (71) ≤ e − γ ǫn η − γ P ( n + m ) p l =1 ν l + γ P ( n + m ) p l =1 ν l +2 γ 2 P ( n + m ) p l =1 ν 2 l (72) ≤ e − n 32 η 2 (1 − σ max ) 3 ǫ 2 , (73) where had to assume that ǫ < 2 /D in orde r to apply the boun d on log(1 − x ) . An analogo us reasoning leads us to, P ( b Q ij − E ( b Q ij ) < − ǫ ) ≤ e − n 32 η 2 (1 − σ max ) 3 ǫ 2 (74) and the results follows. 14 Lemma A.5. As b efor e, assume σ max ≡ σ max ( I + η A 0 ) < 1 and consider that model (6) was initiated at time − m with w ( − m ) , tha t is, x ( − m ) = w ( − m ) then | E ( b Q ij ) − Q 0 ij | ≤ 1 n + m η (1 − σ max ) 2 . (75) Pr oof. Let ρ = I + η A 0 . Since, Q 0 ij = η ∞ X l =0 ( ρ l ρ ∗ l ) ij , ( 76) and E ( b Q ij ) = η n + m − 1 X l =0 m + n − l n + m ( ρ l ρ ∗ l ) ij , (77) we can write, Q 0 ij − E ( b Q ij ) = η ∞ X l = m + n ( ρ l ρ ∗ l ) ij + n + m − 1 X l =1 l m + n ( ρ l ρ ∗ l ) ij ! . (78) Using th e fact that for any matrix A and B max ij ( A ij ) ≤ σ max ( A ) , σ max ( AB ) ≤ σ max ( A ) σ max ( B ) and σ max ( A + B ) ≤ σ max ( A ) + σ max ( B ) and intro ducing the no tation ζ = ρ 2 we can write, | E ( b Q ij ) − Q 0 ij | ≤ η ζ n + m 1 − ζ + ζ n + m m + n − 2 X l =0 ζ l ! = η ( ζ 2 + ζ n + m − 2 ζ m + n +1 ) ( m + n )(1 − ζ ) 2 (79) ≤ η ( m + n )(1 − σ max ) 2 , (80) where we used the fact that for ζ ∈ [0 , 1] and n ∈ N we hav e 1 − ζ ≥ 1 − √ ζ and ζ 2 + ζ n − 2 ζ 1+ n ≤ 1 . Proof of T heorem 3.1: In ord er to p rove Theorem 3. 1 we need to co mpute th e p robability that the condition s given by Proposition 4.1 ho ld. From th e statement of the theorem we have that the first two co nditions ( α, C min > 0 ) of Proposition 4.1 h old. In order to make the fir st co ndition o n b G imp ly th e second condition on b G we assume that λα 3 ≤ A min C min 4 k − λ (81) which is guaran teed to hold if λ ≤ A min C min / 8 k . (82) W e also comb ine the tw o last conditions on b Q to | | | b Q [ p ] ,S 0 − Q 0 [ p ] ,S 0 | | | ∞ ≤ α 12 C min √ k . (83) Where [ p ] = S 0 ∪ ( S 0 ) c . W e then impo se that both the prob ability of the con dition on b Q failing and the pro bability o f th e con dition o n b G failing ar e upp er bo unded by δ / 2 . Using Prop osition 4. 2 we see th at the con dition on b G fails with pro bability smaller than δ / 2 given th at the following is satisfied λ 2 = 36 α − 2 ( nη D ) − 1 log(4 p/δ ) . (84) But we also want ( 82) to b e satisfied a nd so substituting λ fr om the previous expression in (82) we conclud e that n must satisfy n ≥ 2304 k 2 C min − 2 A min − 2 α − 2 ( D η ) − 1 log(4 p/δ ) . (85) 15 In addition, the application of the prob ability bound in Proposition 4.2 requ ires that λ 2 α 2 9 < 1 / 4 (86) so we need to impose furthe r that, n ≥ 1 6( D η ) − 1 log(4 p/δ ) . (87) T o use Corollar y 4.4 for computing the probability that the condition on b Q holds we need, nη > 3 /D , (88) and αC min 12 √ k < 2 k D − 1 . (89) The last expression imposes the following conditions on k , k 3 / 2 > 24 − 1 αC min D . (90) The proba bility of the cond ition on b Q will be up per bounded by δ/ 2 if n > 4608 η − 1 k 3 α − 2 C min − 2 D − 3 log 4 pk /δ . (91) The restriction ( 90) on k loo ks un fortun ate but since k ≥ 1 we can actually show it always hold s. Just notice α < 1 a nd that σ max ( Q 0 S 0 ,S 0 ) ≤ σ max ( Q 0 ) ≤ η 1 − σ max ⇔ D ≤ σ − 1 max ( Q 0 S 0 ,S 0 ) (92) therefor e C min D ≤ σ min ( Q 0 S 0 ,S 0 ) /σ max ( Q 0 S 0 ,S 0 ) ≤ 1 . This last expression also allows us to simplify the four re strictions on n in to a single one that do minates them. I n fact, sin ce C min D ≤ 1 we also hav e C − 2 min D − 2 ≥ C − 1 min D − 1 ≥ 1 and t his allo ws us to conclude that the o nly two con ditions on n that we actually need to im pose are the one at Equations (85), and (91). A little more of alg ebra shows that these two inequalities are satisfied if nη > 10 4 k 2 ( k D − 2 + A − 2 min ) α 2 D C 2 min log(4 pk /δ ) . (93) This conclude the proof of Theor em 3.1. Lemma A.6. Let σ max ≡ σ max ( I + η A 0 ) and ρ min ( A 0 ) = − λ max (( A 0 + ( A 0 ) ∗ ) / 2) > 0 then, − λ min A 0 + ( A 0 ) ∗ 2 ≥ lim sup η → 0 1 − σ max η , (94) lim inf η → 0 1 − σ max η ≥ − λ max A 0 + ( A 0 ) ∗ 2 . (95) Pr oof. 1 − σ max η = 1 − λ 1 / 2 max (( I + η A 0 ) ∗ ( I + η A 0 )) η (96) = 1 − λ 1 / 2 max ( I + η ( A 0 + ( A 0 ) ∗ ) + η 2 ( A 0 ) ∗ A 0 ) η (97) = 1 − (1 + η u ∗ ( A 0 + ( A 0 ) ∗ + η ( A 0 ) ∗ A 0 ) u ) 1 / 2 η , (98) where u is some unit vector that depends on η . Thus, since √ 1 + x = 1 + x/ 2 + O ( x 2 ) , lim inf η → 0 1 − σ max η = − lim sup η → 0 u ∗ A 0 + ( A 0 ) ∗ 2 u ≥ − λ max A 0 + ( A 0 ) ∗ 2 . (99) The other inequality is proved in a similar way . 16 Proof of T heorem 2.1: In order to prove Theorem 2.1 we first state and prove the following lemma, Lemma A.7. Let G be a simple connec ted graph of vertex degr ee bound ed above by k . Let ˜ A be its adjacenc y matrix and A 0 = − hI + ˜ A with h > k then for this A 0 the system in (1) has Q 0 = − (1 / 2)( A 0 ) − 1 and, | | | Q 0 ( S 0 ) C ,S 0 ( Q 0 S 0 ,S 0 ) − 1 | | | ∞ = | | | ( A 0 ( S 0 ) C , ( S 0 ) C ) − 1 A 0 ( S 0 ) C ,S 0 | | | ∞ ≤ k / h. (100) Pr oof. ˜ A is sym metric so A 0 is symmetr ic. Since ˜ A is ir reducible and n on-negative, Per ron- Frobenio us theor em te lls that λ max ( ˜ A ) ≤ k and co nsequen tly λ max ( A 0 ) ≤ − h + λ max ( ˜ A ) ≤ − h + k . Thu s h > k implies that A 0 is negative definite and using e quation (4) we can com pute Q 0 = − (1 / 2)( A 0 ) − 1 . Now notice that, by the block matrix in verse formula, we ha ve ( Q 0 S 0 ,S 0 ) − 1 = − 2 C − 1 , (101) Q 0 ( S 0 ) C ,S 0 = 1 2 (( A 0 ( S 0 ) C , ( S 0 ) C ) − 1 A 0 ( S 0 ) C ,S 0 C ) , (102) where C = A 0 S 0 ,S 0 − A 0 S 0 , ( S 0 ) C ( A 0 ( S 0 ) C , ( S 0 ) C ) − 1 A 0 ( S 0 ) C ,S 0 and thus | | | Q 0 ( S 0 ) C ,S 0 ( Q 0 S 0 ,S 0 ) − 1 | | | ∞ = | | | ( A 0 ( S 0 ) C , ( S 0 ) C ) − 1 A 0 ( S 0 ) C ,S 0 | | | ∞ . (103) Recall the definition of | | | B | | | ∞ , | | | B | | | ∞ = max i X j | B ij | . (104) Let z = h − 1 and write, ( A 0 ( S 0 ) C , ( S 0 ) C ) − 1 = − z ( I − z ˜ A ( S 0 ) C , ( S 0 ) C ) − 1 = − z ∞ X n =0 ( z ˜ A ( S 0 ) C , ( S 0 ) C ) n , (105) A 0 ( S 0 ) C ,S 0 = z − 1 z ˜ A ( S 0 ) C ,S 0 . (106) This allows us to conclu de that | | | ( A 0 ( S 0 ) C , ( S 0 ) C ) − 1 A 0 ( S 0 ) C ,S 0 | | | ∞ is in fact th e ma ximum over all path gen erating func tions of pa ths starting fro m a n ode i ∈ ( S 0 ) C and hitting S 0 for a first time . Let Ω i denote this set of path s, ω a ge neral path in G and | ω | its length. Let k 1 , ..., k | ω | denote the degree o f each vertex visited by ω an d no te that k m ≤ k , ∀ m . Then each o f these path gene rating function s can be written in the following form, X ω ∈ Ω i z | ω | ≤ X ω ∈ Ω i 1 k 1 ...k | ω | ( k z ) | ω | = E G (( k z ) T i,S 0 ) , (107) where T i,S 0 is th e first h itting time of the set S 0 by a r andom walk th at starts at nod e i ∈ S 0 C and moves with equal pr obability to each neigh borin g node. But T i,S 0 ≥ 1 and k z < 1 so the pr evious expression is upper bounded by kz . Now what r emains to co mplete th e pr oof o f Theo rem 2 .1 is to compute the quan tities α , A min , ρ min ( A 0 ) an d C min in Theorem 1.1 . From Lemma A.7 we kno w that α = 1 − k / ( k + m ) . Clearly , A min = 1 . W e also have that ρ min ( A 0 ) = σ min ( A 0 ) ≥ k + m − σ max ( ˜ A ) ≥ m + k − k = m . Finally , λ min ( Q 0 S 0 ,S 0 ) = 1 2 λ min ( − ( A 0 ) − 1 ) = 1 2 1 λ max ( − A 0 ) ≥ 1 2 1 m + k + k ≥ 1 4( m + k ) (108) where in the last step we m ade use of the fact that m + k > k . Substituting th ese values in the inequality from Theorem 1.1 giv es the desired result. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment