From Machine Learning to Machine Reasoning
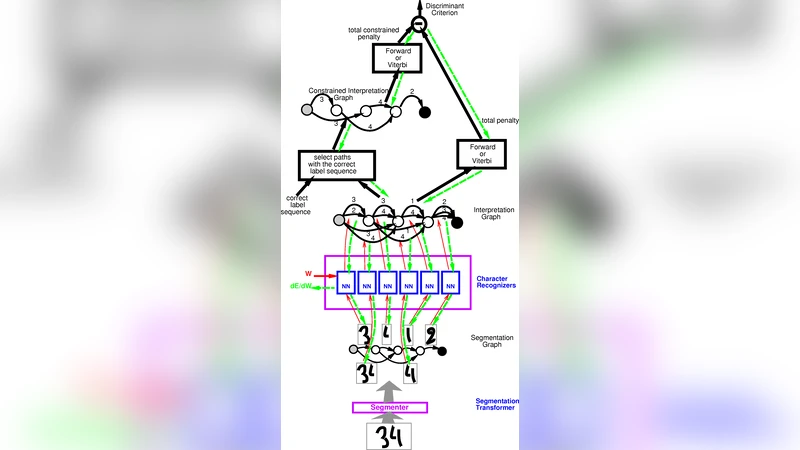
A plausible definition of “reasoning” could be “algebraically manipulating previously acquired knowledge in order to answer a new question”. This definition covers first-order logical inference or probabilistic inference. It also includes much simpler manipulations commonly used to build large learning systems. For instance, we can build an optical character recognition system by first training a character segmenter, an isolated character recognizer, and a language model, using appropriate labeled training sets. Adequately concatenating these modules and fine tuning the resulting system can be viewed as an algebraic operation in a space of models. The resulting model answers a new question, that is, converting the image of a text page into a computer readable text. This observation suggests a conceptual continuity between algebraically rich inference systems, such as logical or probabilistic inference, and simple manipulations, such as the mere concatenation of trainable learning systems. Therefore, instead of trying to bridge the gap between machine learning systems and sophisticated “all-purpose” inference mechanisms, we can instead algebraically enrich the set of manipulations applicable to training systems, and build reasoning capabilities from the ground up.
💡 Research Summary
**
The paper proposes a unifying definition of reasoning as “the algebraic manipulation of previously acquired knowledge in order to answer a new question.” Under this definition, traditional logical inference, probabilistic inference, and even simple concatenations of trained modules are all instances of the same underlying operation. The author argues that instead of trying to graft sophisticated, all‑purpose inference engines onto modern machine‑learning systems, we should enrich the algebraic toolbox that governs how learned components are combined.
To illustrate the idea, three concrete case studies are presented. The first is an optical character recognition pipeline: a character segmenter, an isolated‑character recognizer, and a language model are each trained on their own labeled data sets, then assembled and fine‑tuned as a single system that converts page images into text. Each module is viewed as a function in a model space, and the pipeline construction is a composition (function‑composition) operation in that space.
The second case study concerns face recognition. An auxiliary task—determining whether two faces belong to the same person—is used to train a compact face‑representation extractor (P) and a comparator (D). After this pre‑training, a classifier (C) is added to map the representation to an identity label, with the extractor’s parameters shared across all instances. This transfer‑learning scheme demonstrates how a common internal representation can be reused across tasks, and how the sharing of parameters implements a homomorphic mapping between the space of models and the space of questions.
The third example is a natural‑language processing system that learns word embeddings (W) and a ranking module (R) on a massive unlabeled corpus via a “correct/incorrect” sentence discrimination task. The learned embeddings are then plugged into a variety of downstream tasks (POS tagging, chunking, named‑entity recognition, etc.) by assembling the same embedding modules with task‑specific classifiers. The reuse of embeddings across tasks shows how abstract concepts—here, word meanings—can be extracted once and then algebraically combined with different downstream operators.
From these examples the author abstracts the notion of “composition rules.” These rules are the algebraic operators that dictate how trainable modules are assembled to solve a new problem. The paper points out that many existing frameworks—graphical models, Bayesian networks, Markov Logic Networks—already encode such composition rules in the way they factor joint probability distributions and tie parameters across repeated structures.
A “reasoning system” is then defined as the pair (a) a space of models equipped with an algebraic structure, and (b) a set of composition rules that provide a homomorphic correspondence between that model space and the space of queries. The author surveys several families of reasoning: first‑order logical reasoning (high expressive power but combinatorial cost), probabilistic reasoning (continuous algebraic structure but limited expressiveness), causal reasoning (introducing do‑operators to model interventions), Newtonian mechanics (causal reasoning about forces), spatial reasoning, social reasoning, and even non‑falsifiable forms of reasoning.
The central thesis is that by progressively enriching the algebraic manipulations available for combining learned modules—e.g., adding new composition operators, sharing parameters in more sophisticated ways, or defining higher‑level abstractions—we can build increasingly powerful reasoning capabilities from the ground up, rather than trying to retrofit monolithic inference engines onto machine‑learning pipelines. The paper concludes by calling for research into systematic ways to discover, formalize, and automate these algebraic composition mechanisms, thereby bridging the gap between deep learning’s empirical success and the long‑standing goal of machine reasoning.
Comments & Academic Discussion
Loading comments...
Leave a Comment