A High Speed Networked Signal Processing Platform for Multi-element Radio Telescopes
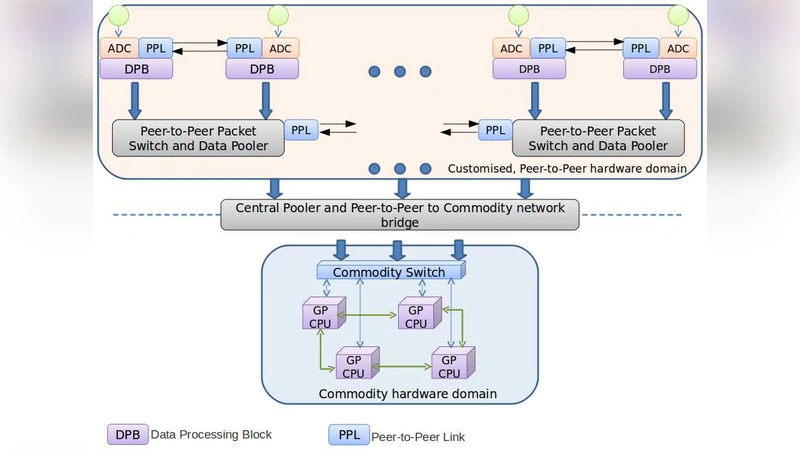
A new architecture is presented for a Networked Signal Processing System (NSPS) suitable for handling the real-time signal processing of multi-element radio telescopes. In this system, a multi-element radio telescope is viewed as an application of a multi-sensor, data fusion problem which can be decomposed into a general set of computing and network components for which a practical and scalable architecture is enabled by current technology. The need for such a system arose in the context of an ongoing program for reconfiguring the Ooty Radio Telescope (ORT) as a programmable 264-element array, which will enable several new observing capabilities for large scale surveys on this mature telescope. For this application, it is necessary to manage, route and combine large volumes of data whose real-time collation requires large I/O bandwidths to be sustained. Since these are general requirements of many multi-sensor fusion applications, we first describe the basic architecture of the NSPS in terms of a Fusion Tree before elaborating on its application for the ORT. The paper addresses issues relating to high speed distributed data acquisition, Field Programmable Gate Array (FPGA) based peer-to-peer networks supporting significant on-the fly processing while routing, and providing a last mile interface to a typical commodity network like Gigabit Ethernet. The system is fundamentally a pair of two co-operative networks, among which one is part of a commodity high performance computer cluster and the other is based on Commercial-Off The-Shelf (COTS) technology with support from software/firmware components in the public domain.
💡 Research Summary
The paper introduces a novel architecture called the Networked Signal Processing System (NSPS) designed to meet the demanding real‑time data‑processing needs of modern multi‑element radio telescopes. By reframing the telescope as a multi‑sensor data‑fusion problem, the authors propose a hierarchical “Fusion Tree” that separates the system into two cooperating networks: a custom peer‑to‑peer network built around FPGA boards and a commodity high‑performance computing (HPC) cluster that communicates via standard Gigabit Ethernet.
In the custom segment, each antenna’s analog signal is digitized (e.g., 8‑bit ADC at 80 MS/s for the Ooty Radio Telescope upgrade) and fed into FPGA nodes that perform on‑the‑fly operations such as spectral decomposition (FFT or polyphase filter banks), radio‑frequency interference (RFI) detection, data compression, and traffic shaping. Large DRAM buffers attached to the FPGAs enable selective routing and “traffic shaping” – the ability to tag, segregate, and prioritize data streams based on side‑information generated during processing. This side‑information (metadata) is fed back to the network to guide subsequent routing decisions, effectively creating a dynamic, feedback‑driven data‑fusion pipeline.
The commodity segment consists of a conventional HPC cluster that receives the pre‑processed streams over UDP/IP. Because the FPGA layer has already reduced data volume and performed latency‑critical tasks, the cluster can focus on computationally intensive, latency‑tolerant operations such as O(N²) cross‑correlation, self‑calibration, imaging, and archival storage. The authors introduce the concept of a “Transaction Unit” – a time‑slice (ranging from tens of milliseconds to seconds) that is treated as a logical packet. This abstraction relaxes strict timing constraints, simplifies OS scheduling, and tolerates occasional packet loss without degrading scientific output.
A key hardware element is the “Data Pooler” node, which aggregates multiple input streams, performs multi‑pass processing on stored data, and generates side‑information that can be used to dynamically re‑route or further process subsets of the data. By embedding such intelligence in the network, the system achieves hierarchical computation: lower‑level FPGA nodes handle deterministic, high‑throughput tasks, while higher‑level commodity nodes execute more flexible, algorithm‑rich workloads.
The paper demonstrates feasibility through the Ooty Radio Telescope (ORT) re‑configuration: 264 antenna elements, each sampled at 80 MS/s, produce 21 GS/s (≈80 TB per hour). FPGA boards equipped with 4–8 high‑speed links (10 GbE or Aurora) compress the data to 4‑bit complex samples, encapsulate them in UDP packets, and stream them to the HPC cluster. The cluster, using MPI, distributes the O(N²) correlation across many nodes, producing calibrated visibilities for downstream imaging.
Compared with traditional ASIC‑based correlators, NSPS offers several advantages: (1) hardware re‑configurability via FPGA firmware, allowing rapid deployment of new algorithms (e.g., real‑time transient detection); (2) cost‑effectiveness by leveraging commercial‑off‑the‑shelf (COTS) components and open‑source IP; (3) scalability, as additional antenna elements or higher bandwidths can be accommodated by adding more FPGA nodes and expanding the Ethernet fabric; and (4) enhanced data quality through early RFI flagging and metadata‑driven routing, reducing irreversible biases in the final correlations.
In summary, the NSPS architecture provides a flexible, scalable, and cost‑efficient solution for the massive data‑throughput and processing requirements of next‑generation radio interferometers, while also being applicable to other multi‑sensor fusion domains such as radar, medical imaging, and defense tracking systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment