Autoregressive Kernels For Time Series
We propose in this work a new family of kernels for variable-length time series. Our work builds upon the vector autoregressive (VAR) model for multivariate stochastic processes: given a multivariate time series x, we consider the likelihood function…
Authors: Marco Cuturi, Arnaud Doucet
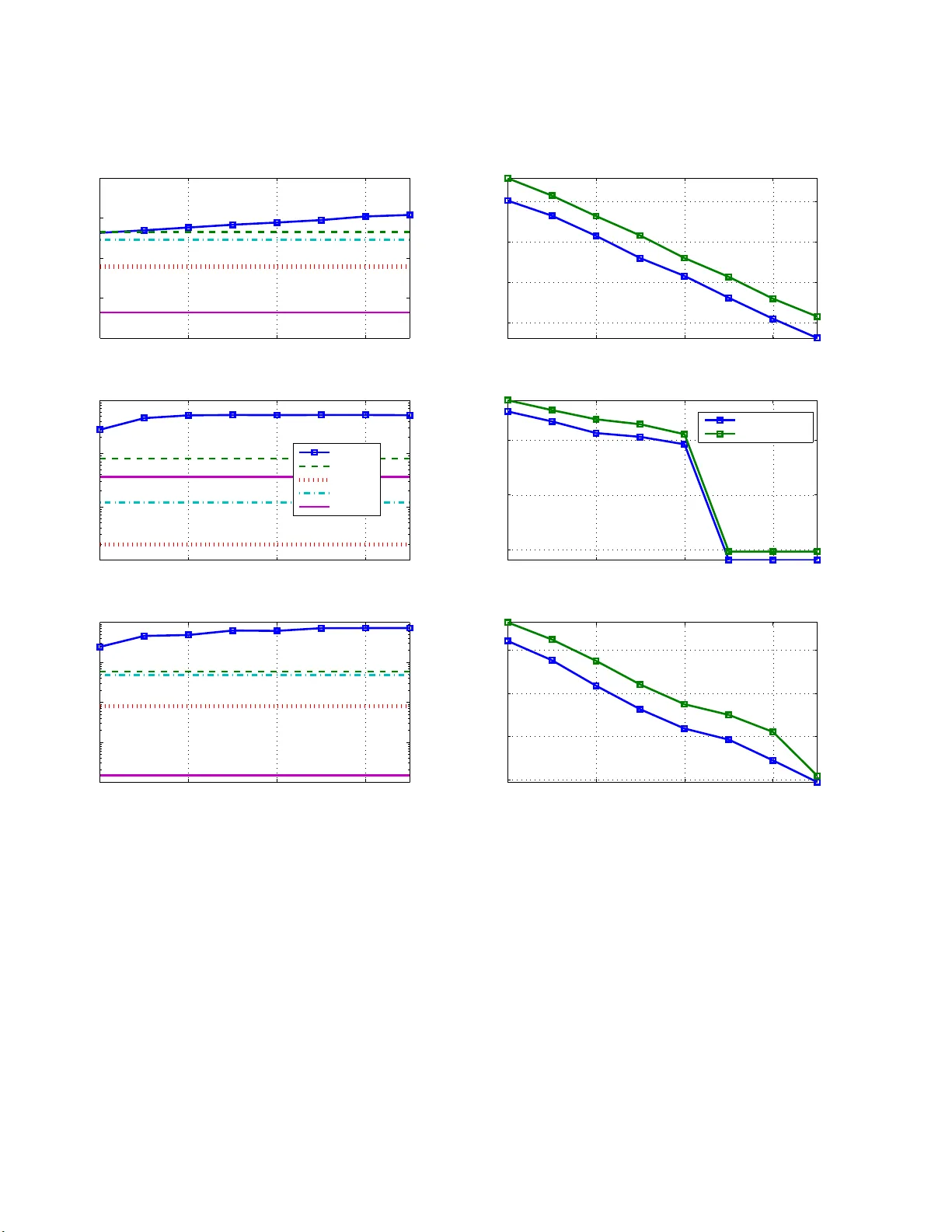
Autoregressive Kernels for Time Series Marco Cuturi Graduate School of Informatics Ky oto Unive rsit y mcuturi@i.k yoto-u.ac.jp Arnaud Doucet Departmen t of Computer Science & Departmen t of Statistics Univ ersit y o f British Columbia arnaud@cs.u bc.ca No v em b er 26, 2024 Abstract W e prop ose in this work a new family of k ernels for v ariable-length time series. Our work builds up on the vector auto regres s ive (V AR) mo del for multiv aria te sto chastic pro- cesses: given a m ultiv ariate time serie s x , we consider the likeliho o d function p θ ( x ) of different parameters θ in the V AR mo del as features to descr ib e x . T o co mpa re tw o time series x a nd x ′ , we form the pro duct of their features p θ ( x ) · p θ ( x ′ ) which is integrated out w .r .t θ using a matr ix normal-inverse Wishart pr ior. Among other pr op erties, this kernel can be ea sily co mputed when the dimension d of the time series is muc h larger than the lengths of the considered time series x and x ′ . It can also b e generaliz ed to time series tak ing v alues in a rbitrary state spaces, as long as the state space itself is endowed with a kernel κ . In that case, the kernel b etw een x and x ′ is a a function o f the Gram matrices pr o duced b y κ on observ ations and subsequences o f observ ations enumerated in x and x ′ . W e describ e a computatio na lly efficient implementation o f this genera lization that uses low-rank matrix fac torization tec hniques. These kernels are compar ed to other known kernels using a set of benchmark classification tasks carried out with s upp o r t vector ma chines. 1 In tro duction Kernel method s [Hofmann et al., 2008] ha v e prov ed useful to handle and analyze struc- tured data. A non-exhaustiv e list of such data typ es includes images [Ch ap elle et al., 1999, Grauman and Darrell, 2005, Cuturi and F uku m izu, 2007, Harc haoui and Bac h, 2007], grap h s [Kashima et al., 2003, Mahe et al. , 20 05, Vishw anathan et al., 20 08 , Sherv a shidze and Borgw ardt, 2009], te xts [Joac hims , 2002, Mosc hitti and Zanzotto, 2007] and strings on finite alphab ets [Leslie et al., 2002, Cortes et al., 2004, V ert et al., 2004, Cuturi and V ert, 2005, Sonnen burg et al., 200 7 ], which hav e all dr a wn m uc h atten tion in r ecen t yea rs. Tim e series, although ubiquitous in science and engineering, ha v e b een comparativ ely the s ub ject of less researc h in the k ernel literature. Numerous similarit y measures and distances for time s eries ha v e b een pr op osed in the past decades [Sc hreib er and Sc hmitz, 199 7 ]. These similarities are not, ho we ve r, alwa ys w ell su ited to the kernel method s framew ork. First, most av ailable similarit y m easur es are not p ositiv e definite [Haasdonk and Bahlmann , 2004 ]. Lik ewise, m ost d istances are not negativ e defin ite. 1 The p ositiv e defin iteness of similarit y m easures (alternativ ely the n egativ e d efiniteness of distances) is needed to use the con v ex optimization algorithms that un derly most kernel ma- c hines. P ositiv e d efi niteness is also the cornerstone of the repro ducing kernel Hilb ert space (RKHS) framework whic h supp orts these tec hniques [Berlinet and T homas-Agnan, 2003]. Second, most similarities measures are only defin ed for ‘stand ard’ multiv ariate time series, that is time s er ies of fin ite dimensional ve ctors. Y et, some of the main application fields of k ernel metho d s include bioinformatics, natur al language p ro cessing and computer vision, where the analysis of time ser ies of stru ctured ob jects (images, texts, graph s) remains a very promising field of study . Ideally , a useful kernel f or time series should b e b oth p ositiv e definite and able to hand le time series of structured data. An oft-quoted example [Bahlmann et al., 2002, Sh im o daira et al., 2002] of a n on-p ositiv e definite s im ilarity for time series is the Dy- namic T ime W arping (DTW) score [S ak o ei and Chiba, 1978], arguably the most p opular similarit y score for v ariable-l ength multiv ariate time series [Rabiner and Juang, 1993, § 4.7]. Hence the DTW can only b e used in a ke rnel mac hine if it is altered through ad ho c mo difica- tions suc h as diagonal regularizations [Zhou et al. , 2010]. Some extensions of th e DTW score ha v e add ressed this issue: Ha y ashi et al. [2005] p r op ose to em b ed time series in Euclidean spaces such that th e distance of such r epresen tations appr o ximates the distance ind uced b y the DTW score. C u turi et al. [2007] consider th e soft-max of the alignmen t scores of all p os- sible alignmen ts to compute a p ositive defin ite k ernel for t w o time series. This kernel can also b e used on t wo time ser ies x = ( x 1 , · · · , x n ) and x ′ = ( x ′ 1 , · · · , x ′ n ′ ) of structured ob- jects since the k ernel b et we en x and x ′ can b e expr essed as a fu nction of the Gr am m atrix K = h κ ( x i , x ′ j ) i i ≤ n,j ≤ n ′ where κ is a giv en kernel on the structured ob jects of in terest. A few alternativ e k ernels ha v e b een prop osed for multi v ariate time series. Kumara et al. [2008] consider a non-parametric approac h to in terp olate time series using splines, and define directly k ernels on these in terp olated repr esentati ons. In a p aragraph of th eir br oad work on p r obabilit y pr o duct kernels, Jebara et al. [20 04 , § 4.5] briefly menti on the id ea of using the Bhattac haryy a distance on suitable rep r esen tations as normal d en sities of tw o time series using state-space mo dels. Vish w anathan et al. [2007] as well as Borgw ardt et al. [2006] use the family of Binet-Cauc h y kernels [Vish w anathan and Sm ola, 2004], originally defined by the co efficien ts of the charac teristic p olynomial of k ernel matrices suc h as the matrix K describ ed ab o v e (when n = n ′ ). Unlik e other tec hniques listed ab o v e, these tw o p rop osals rely on a pr obabilistic mo deling of the time series to defin e a kernel. Namely , in b oth the probabilit y p ro du ct and Binet-Cauc h y approac hes the kernel v a lue is the result of a t wo step computation: eac h time series is fi rst mapp ed onto a set of parameters that summarizes their dynamic b ehavio r; the k ernel is then defined as a kernel b et we en these t wo sets of parameters. The k ernels w e prop ose in this pap er also rely on a probabilistic mo deling of time series to define ke rnels but do a w a y with the tw o step approac h detailed ab ov e. This distinction is discussed later in the p ap er in Remark 2. Our cont ribu tion builds up on the the c ovar ianc e kernel framewo rk prop osed b y Seeger [2002], and w hose approac h can b e traced bac k to the wo rk of Haussler [1999] and Jaakk ola et al. [1999], who advocate the use of pr obabilistic mo dels to ext ract features from structured ob jects. Giv en a measurable space X and a mod el, that is a parameterized f amily of probabilit y distribu tions on X of the form { p θ , θ ∈ Θ } , a k ernel for t w o ob jects x , x ′ ∈ X can b e defined as k ( x , x ′ ) = ˆ θ ∈ Θ p θ ( x ) p θ ( x ′ ) ω ( dθ ) , where ω is a pr ior on the parameter space. Ou r wo rk can b e broadly charac terized as the implemen tation of this idea for time series d ata, using the V AR mo del to define the sp ace 2 of densities p θ and a sp ecific prior for ω , th e m atrix-normal inv erse-W ishart prior. This conjugate prior allo ws us to obtain a closed-form exp ression for the k ernel which admits useful p rop erties. The rest of this pap er is organized as follo ws. Section 2 starts with a brief review of the Ba y esian app roac h to dynamic linear mo deling for multi v ariate sto c hastic p ro cesses, wh ic h pro vides the main to ol to d efine autoregressiv e ke rn els on m ultiv aria te time series. W e follo w b y d etailing a few of the app ealing p rop erties of autoregressiv e k ernels for multiv ariate time series, namely their infin ite d ivisibilit y and their abilit y to h andle high-d imensional time series of short length. W e show in S ection 3 that autoregressiv e kernels can not only b e used on m ultiv aria te time series but also on time series taking v alues in an y set endo we d with a k ernel. Th e kernel is then compu ted as a fun ction of the Gram matrices of s u bsets of shorter time series found in x and x ′ . This computation requ ires itself the computation of large Gram matrices in add ition to a large num b er of op erations that gro ws cubicly w ith the lengths of x and x ′ . W e p r op ose in Section 3.2 to circumv en t this computational b urden by using lo w-rank matrix f actorization of these Gram matrices. W e present in Section 4 differen t exp erimenta l results usin g to y and real-life datasets. 2 Autoregressiv e Kernels W e in tro duce in this sectio n the crux of our con tribution, that is a family of ke rnels that can h an d le v ariable-length m ultiv ariate time s er ies. Sections 2.1, 2.2 and 2.3 detail the construction of suc h k ernels, w hile Sections 2.4 and 2.5 highligh t some of th eir p rop erties. 2.1 Autoregressiv e Kernels as an Instance of Co v a riance Kernels A v ector autoregressiv e mo del of order p henceforth abbreviated as V AR( p ) is a f amily of densities for R d -v alued sto c hastic pr o cesses parameterized by p matrices A i of size d × d and a p ositiv e d efinite matrix V . Given a parameter θ = ( A 1 , · · · , A p , V ) the cond itional probabilit y densit y that an observ ed time series x = ( x 1 , x 2 , . . . , x n ) h as b een d ra wn from mo del θ giv en the p fi rst observ atio ns ( x 1 , . . . , x p ), assum in g p < n , is equal to p θ ( x | x 1 , · · · , x p ) = 1 (2 π | V | ) d ( n − p ) 2 n Y i = p +1 exp − 1 2 x i − p X i =1 A i x t − i 2 V , where for a v ector x and a p ositiv e d efinite matrix V the Mahalanobis n orm k x k 2 V is equal to x T V − 1 x . W e write | x | for the length of the time series x , n in the example ab o v e. W e abbreviate the conditional probabilit y p θ ( x | x 1 , · · · , x p ) as p θ ( x ) and tak e for gran ted that the p first ob s erv at ions of the time s eries are not tak en into accoun t to compute the p robabilit y of x . W e consider the set of parameters Θ = R d × d × · · · × R d × d | {z } p × S ++ d , where S ++ d is the cone of p ositiv e defin ite matrices of size d × d , to d efine a k ernel k that computes a w eigh ted sum of the pr o duct of features of t w o time series x and x ′ as θ v aries in Θ, k ( x , x ′ ) = ˆ θ ∈ Θ p θ ( x ) c ( | x | ) p θ ( x ′ ) c ( | x ′ | ) ω ( dθ ) , (1) 3 where the exp onent ial w eigh t factor c ( | x | ) is used to norm alize the probabilities p θ ( x ) by th e length of the considered time series x . Remark 1. The fe atur e map x → { p θ ( x ) } θ ∈ Θ pr o duc es strictly p ositive fe atur es. F e atur es wil l b e natur al ly closer to 0 for longer time series. We fol low in this work the c ommo n pr actic e in the kernel metho d s liter atur e, as wel l as the signal pr o c essing liter atur e, to normalize to some extent these fe atur es so that their magnitude is indep endent of the size of the input obje ct, namely the length of the input time series. We pr op ose to do so by normalizing the pr ob abilities p θ ( x ) by the lengths of the c onsider e d series. The weight c ( | x | ) intr o duc e d in Equation 1 is define d to this effe ct in se ction 2.3. Remark 2. The formulation of E quation (1) is somehow ortho gonal to ke rnels that map structur e d obje cts, in this c ase time series, to a single density in a given mo del and c om- p ar e dir e ctly these densities u si ng a kernel b etwe en densities, su c h as pr ob ability pr o duct kernels [J eb ar a et al., 2004], Binet-Cauchy kernels [Vishwanatha n et al., 2007], structur al kernels [H ein and Bousquet, 2005] or information diffusion kernels [L eb anon , 2006]. Inde e d, such kernels r ely first on the estimatio n of a p ar ameter ˆ θ x in a p ar ameterize d mo del class to summarize the pr op erties of an obje ct x , and then c omp ar e two obje cts x and x ′ by using a pr oxy kernel on ˆ θ x and ˆ θ x ′ . These appr o ach es do r e qu ir e that the mo d el class, the V AR mo del in the c ont ext of this p ap er, pr op erly mo dels the c onsider e d obje cts, namely that x is wel l summarize d by ˆ θ x . The ke rnels we pr op ose do not suffer fr om this key r estriction: the V AR mo del c ons ider e d in this work is never use d to infer likely p ar ameters for a time series x but is use d inste ad to gener ate an infinite family of fe atur es. The ke rnel k is mainly defined by the prior ω on the parameter space. W e p resen t in the next section a p ossible c hoice for this prior, the matrix-normal inv erse-Wishart prior, whic h has b een extensivel y s tu died in the framew ork of Ba y esian lin ear regression applied to dynamic linear mo dels. 2.2 The Matrix-Normal In v erse-Wishart Pr ior in the Ba y esian Linear R e- gression F ramew ork Consider the regression mo d el b etw ee n a vect or of explanatory v ariables x of R m , and an output v ariable y ∈ R d , y = Ax + ε, where A is a d × m co efficient matrix and ε is a cen tered Gaussian noise w ith d × d co v ariance matrix V . Accordingly , y f ollo ws conditionally to x a normal density y | ( x, A, V ) ∼ N ( Ax, V ) . Giv en n p airs of explanatory and resp onse v ectors ( x i , y i ) 1 ≤ i ≤ n w eigh ted b y n nonnegativ e co efficien ts t = ( t 1 , . . . , t n ) ≥ 0 such that P n i =1 t i = 1, the w eigh ted lik elihoo d of this sample of n ob s erv at ions is d efined by th e expression ρ ( Y | X, A, V , ∆) = n Y i =1 p ( y j | x j , A, V ) t j , = 1 | 2 π V | 1 / 2 exp − 1 2 tr ∆( Y − AX ) T V − 1 ( Y − AX ) , = 1 | 2 π V | 1 / 2 exp − 1 2 tr V − 1 ( Y − AX )∆( Y − AX ) T . 4 where the matrices ∆ , Y and X stand resp ectiv ely for diag ( t 1 , . . . , t n ) ∈ R n × n , [ y 1 , · · · , y n ] ∈ R d × n and [ x 1 , . . . , x n ] ∈ R m × n . The matrix-normal inv erse Wishart joint distrib u tion W est and Harrison [1997, § 16.4. 3] is a natural c hoice to mo del the randomness for ( A, V ). The prior assumes that the d × m matrix A is d istributed follo wing a cen tered matrix-normal dens ity w ith left v ariance matrix parameter V and righ t v ariance matrix p arameter Ω, p ( A ) = MN ( A ; 0 , V , K ) = 1 | 2 π V | m/ 2 | Ω | d/ 2 exp − 1 2 tr A T V − 1 A Ω − 1 where Ω is a m × m p ositiv e d efinite matrix. Using the f ollo wing notations, S xx = X ∆ X T + Ω − 1 , S y x = Y ∆ X T , S y y = Y ∆ Y T , S y | x = S y y − S y x S − 1 xx S T y x . w e can int egrate out A in ρ ( Y | X , A, V , ∆) to obtain ρ ( Y | X, V ) = 1 | Ω | d/ 2 | S xx | d/ 2 | 2 π V | 1 / 2 exp − 1 2 tr( V − 1 S y | x ) . (2) The matrix-normal inv erse Wishart prior for ( A, V ) also assumes that V is distribu ted with in v erse-Wishart density W − 1 λ (Σ) of in ve rse scale matrix Σ and d egrees of freedom λ > 0. The p osterior obtained b y multiplying this p rior by Equation (2) is itself p rop ortional to an in v erse-Wishart d ensit y with p arameters W − 1 (Σ + S y | x , 1 + λ ) whic h can b e in tegrated to obtain the marginal we ight ed lik eliho o d , ρ ( Y | X ) = n Y i =1 Γ( λ +2 − i 2 ) Γ( λ +1 − i 2 ) 1 | Ω | d/ 2 | S xx | d/ 2 | Σ | λ/ 2 | S y | x + Σ | 1+ λ 2 Using for Σ the prior I d , f or Ω the matrix I m , an d discarding all constant s indep endent of X and Y yields the expression ρ ( Y | X ) ∝ 1 | X ∆ X T + I m | d/ 2 | Y (∆ − ∆ X T ( X ∆ X T + I m ) − 1 X ∆) Y T + I d | 1+ λ 2 , Note that the matrix H ∆ def = ∆ X T X ∆ X T + I m − 1 X ∆ in the denomin ator is known as th e hat-matrix of the orthogonal least-squares regression of Y v ersus X . T he righ t term in the denominator can b e in terpreted as the determinan t of th e w eigh ted cross-co v ariance matrix of Y with the residues (∆ − H ∆ ) Y regularized b y the iden tit y matrix. 2.3 Ba y esian Averagi ng ov er V AR Mo dels Giv en a V AR( p ) mo del, w e represen t a time series x = ( x 1 , · · · , x n ) as a sample X of n − p pai rs of explanatory v aria bles in R pd and resp onse v a riables in R d , namely { ([ x i , · · · , x p + i − 1 ] , x p + i ) , i = 1 , · · · , n − p } . F ollo wing a standard practice in the study of V AR mo dels [L ¨ utk ep ohl, 2005, 5 § 3], this set is b etter su mmarized by matrices X = . . . x 1 . . . · · · . . . x n − p +1 . . . . . . · · · . . . . . . x p . . . · · · . . . x n − 1 . . . ∈ R pd × n − p , an d Y = . . . · · · . . . x p +1 · · · x n . . . · · · . . . ∈ R d × n − p . Analogously , we us e th e corresp ondin g n otations X ′ , Y ′ for a second time series x ′ of length n ′ . Using the n otation N def = n + n ′ − 2 p, these samp les are aggregated in the R N × N , R pd × N and R d × N matrices ∆ = dia g 1 2 1 n − p , · · · , 1 n − p | {z } n − p times , 1 n ′ − p , · · · , 1 n ′ − p | {z } n ′ − p times , X = X X ′ , Y = Y Y ′ . (3) Note that b y setting A = [ A 1 , · · · , A p ] and θ = ( A, V ), the integ rand that app ears in Equation (1) can b e cast as the follo wing prob ab ility , p θ ( x ) 1 2( n − p ) p θ ( x ′ ) 1 2( n ′ − p ) = ρ ( Y | X , A, V , ∆) . In tegrating out θ using the matrix-normal inv erse Wishart prior MW − 1 λ ( I d , I pd ) for ( A, V ) yields th e follo wing definition: Definition 1. Given two time series x , x ′ and using the notations intr o duc e d i n Equation (3 ) , the autor e gr essive kernel k of or d er p and de gr e es of fr e e do m λ is define d as k ( x , x ’) = 1 | X ∆ X T + I pd | d 2 | Y (∆ − ∆ X T ( X ∆ X T + I pd ) − 1 X ∆) Y T + I d | 1+ λ 2 . (4) 2.4 V ariance and Gram Based F ormu lations W e sho w in this section that k can b e reform ulated in terms of Gram matrices of subsequ ences of x and x ′ rather than v a riance-co v ariance matrices. F or t w o square matrices C ∈ R q × q and D ∈ R r × r w e write C ∽ D when th e sp ectrums of C and D coincide, taking into accoun t m ultiplicit y , except for the v alue 0. Recall fir st the f ollo wing trivial lemma. Lemma 1. F or two matric es A and B in R q × r and R r × q r e sp e ctively, AB ∽ B A , and as a c on se quenc e | AB + I q | = | B A + I r | Based on this lemma, it is p ossible to establish the follo wing r esult. Prop osition 1. L et α def = 1+ λ d then the auto gr essive kernel k of or der p and de gr e es of fr e e dom λ given in Eq uation (4 ) is e qual to k ( x , x ′ ) = | X T X ∆ + I N | 1 − α | X T X ∆ + Y T Y ∆ + I N | α − d 2 , (5) 6 Pr o of. W e use Lemma 1 to rewrite the first term of the d enominator of Equ ation (4) usin g the Gram matrix X T X , | X ∆ X T + I pd | = | X T X ∆ + I N | . T aking a closer lo ok at the d enominator, the matrix inv ersion lemma 1 yields th e equalit y (∆ − ∆ X T X ∆ X T + I pd − 1 X ∆) = ( X T X + ∆ − 1 ) − 1 . Using again Lemma 1 th e d en ominator of E quation (4) can b e reform ulated as Y (∆ − ∆ X T X ∆ X T + I pd − 1 X ∆) Y T + I d = | X T X + ∆ − 1 + Y T Y | | X T X + ∆ − 1 | . F actoring in these t wo r esults, we obtain Equ ation (5). W e call E q u ation (4) the V ariance formulati on and Equation (5) the Gram form ulation of the autoregressiv e ke rnel k as it only dep end s on the Gram matrices of X and Y . Although b oth the V ariance and Gram formulations of k are equal, th eir computational cost is different as d etailed in the remark b elo w. Remark 3. In a high N -low d setting , the c omp utation of k r e quir es O ( N ( pd ) 2 ) op er ations to c omp ute the denominator’s matric es and O ( p 3 d 3 + d 3 ) to c omp ute their inverse, which yields an over a l l c o st of the or der of O ( N p 2 d 2 + ( p 3 + 1) d 3 ) . This may se em r e asonable for applic ations wher e the cumulate d time series lengths’ N is much lar ger than the dimension d of these time series, such as sp e e ch signals or EEG data. In a low N -high d setting , which fr e quently app e ars in bioinformatics or vide o pr o c essing applic ations, autor e gr essive kernels c an b e c ompute d using Equation (5) in O (( p + 1) dN 2 + N 3 ) op e r ations. 2.5 Infinite Divisibilit y of Autoregressive Kernels W e recall that a p ositiv e definite ke rnel function k is infinitely divisible if for all n ∈ N , k 1 /n is also p ositive defin ite [Berg et al. , 1984 , § 3.2.6]. W e p ro v e in this section that un der certain conditions on λ , the degrees-of-freedom p arameter of th e in v erse Wishart la w, the autore- gressiv e ke rnel is in fi nitely d ivisible. T his resu lt builds u p on [Cuturi et al., 2005, Prop osition 3]. Pro ving the infi nite divisibilit y of k is usefu l for the follo wing tw o reasons: First, follo wing a w ell-kno wn result Berg et al. [1984, § 3.2.7], the infin ite divisibility of k imp lies the negativ e definiteness of − log k . Using Berg et al. [1984, § 3.3.2] for instance, there exists a mapping Φ of X N on to a Hilb ert space such that k Φ( x ) − Φ( x ’ ) k 2 = log k ( x , x ) + log k ( x ’, x ’ ) 2 − log k ( x , x ’) . and hence k d efi nes a Hilb ertian metric for time series w hic h can b e used with distance-based to ols su c h as nearest-neigh b ors. Second, on a more practical note, the exp onent d/ 2 in E quation (5) is numerically prob- lematic when d is large. In such a situation, the k ernel matrices pro d uced by k wo uld b e diagonally d ominan t. This is an alogous to selecting a b an d width parameter σ whic h is to o small when usin g the Gaussian k ernel on h igh-dimensional d ata. By pro ving th e infinite divisibilit y of k , the exp onen t d can b e remov e d and substituted by an y arb itrary exp onen t. 1 ( A + U C V ) − 1 = A − 1 − A − 1 U C − 1 + V A − 1 U − 1 V A − 1 7 T o establish the infinite divisibilit y r esult, we need a few additional notation. Let M ( R d ) b e the set of p ositiv e measures on R d with fin ite second-moment µ [ xx T ] def = E µ [ xx T ] ∈ R d × d . This set is a semigroup [Berg et al., 1984] wh en endo w ed with the u sual addition of measures. Lemma 2. F or two me asur es µ and µ ′ of M ( R d ) , the kernel τ : ( µ, µ ′ ) 7→ 1 p | ( µ + µ ′ )[ xx T ] + I d | , is an infinitely divisible p ositive definite kernel. Pr o of. Th e follo wing ident it y is v alid for an y d × d p ositiv e-definite matrix Σ 1 p | Σ + I d | = 1 p (2 π ) d ˆ R d e − 1 2 y T (Σ+ I d ) y dy Giv en a measure µ with fin ite second-moment on R d , we thus ha ve 1 p | µ [ xx T ] + I d | = ˆ R d e − 1 2 h µ [ xx T ] , y y T i p N (0 ,I d ) ( dy ) (6) where h , i stands for the F rob enius dot-pro duct betw een matrices and p N (0 ,I d ) is the s tand ard m ultiv ariat e n ormal densit y . In th e formalism of [Berg et al. , 1984] the in tegral of Equa- tion (6) is an inte gral of b ounded semic haracters on the semigroup ( M ( R d ) , +) equipp ed with autoinv o lution. Eac h semic haracter ρ y is indexed b y a v ector y ∈ R d as ρ y : µ 7→ e − 1 2 h µ [ xx T ] , y y T i . T o verify that ρ y is a semic haracter n otice that ρ y (0) = 1, where 0 is the zero measur e, and ρ y ( µ + µ ′ ) = ρ y ( µ ) ρ y ( µ ′ ) for t wo m easures of M ( R d ). No w, using th e fact that the m ultiv ariat e normal densit y is a stable distribution, one has that for an y t ∈ N , 1 p | µ [ xx T ] + I d | = ˆ R d e − 1 2 t h µ [ xx T ] , yy T i t p ⊗ t N (0 ,I d /t ) ( dy ) , = ˆ R d e − 1 2 t h µ [ xx T ] , y y T i p N (0 ,I d /t ) ( dy ) t , where p ⊗ t is th e t -th conv olutio n of densit y p , w h ic h pr o v es th e result. Theorem 2. F or 0 ≤ α ≤ 1 , e quivalently for 0 < λ ≤ d − 1 , ϕ def = − 2 d log k is a ne gative definite kernel Pr o of. k is infin itely divisible as the p ro du ct of t w o infin itely divisible k ernels, τ d (1 − α ) and τ dα computed on t wo different r epresen tations of x and x ′ : first as empirical measur es on R pd with lo cations en umerated in th e columns of X and X ′ resp ectiv ely , and as empirical measures on R pd + d with lo cations en umerated in the columns of the stac k ed matrices [ X ; Y ] and [ X ′ ; Y ′ ]. Th e set of weigh ts for b oth representati ons are th e uniform weigh ts 1 2( n − p ) and 1 2( n ′ − p ) . Th e negativ e definiteness of ϕ follo ws fr om, and is equiv alen t to, the infi nite divisibilit y of k Berg et al. [1984, § 3.2 .7]. 8 Remark 4. The infinite divisibility of the joint distribution matrix normal-inverse Wishart distribution would b e a suffici e nt c ondition to obtain dir e ctly the infinite divisibility of k using for instanc e Ber g et al. [1984, § 3.3.7]. Unfortunately we have neither b e en able to pr ove this pr op erty nor found it in the liter a tur e. The inverse Wishart distribution alone is known to b e not infinitely divisible i n the gener al c ase [L ´ evy, 1948]. We do not know either whether k c an b e pr ove d to b e infinitely divisible when λ > d − 1 . The c onditio n 0 < λ ≤ d − 1 , and henc e 0 ≤ α ≤ 1 also plays an imp orta nt r ole in Pr op osition 4. In the next sections, w e will usually r efer to th e (negativ e defin ite) autoregressiv e k ernel ϕ ( x , x ′ ) = C n,n ′ + (1 − α ) log | X T X + ∆ − 1 | + α log | X T X + Y T Y + ∆ − 1 | (7) where th e constant C n,n ′ = ( n − p ) log(2( n − p )) + ( n ′ − p ) log(2( n ′ − p )), rather than considering k itself. 3 Extension to Time Series V alued in a Set Endo w ed with a Kernel W e sho w in Section that autoregressiv e kernels can b e extended qu ite simp ly to time series v a lued in arbitrary spaces by considering Gram matrices. This extension is inte resting but can b e v ery computationally exp ensiv e. W e prop ose a w a y to mitigate this computational cost by using low-rank matrix factorization tec hniques in Section 3.2 3.1 Autoregressiv e Kernels Defined Through Arbitr ary Gram Matrices Using again notation int ro d uced in Equation (3), we write K X = X T X for the N × N Gram matrix of all explanatory v aria bles con tained in the join t sample X and K Y = Y T Y f or the Gram m atrix of all ou tp uts of the lo cal regression formulatio ns. As s tated in Equ ation (7) ab o v e, ϕ an d k by extension can b e d efi ned as a fu nction of the Gram matrices K X and K Y . T o allevia te notations, w e introdu ce t w o functions g and f defined resp ectiv ely on the cone of p ositiv e semid efi nite matrices S + N and on ( S + N ) 2 : g : Q 7→ log | Q + ∆ − 1 | , f : ( Q, R ) 7→ (1 − α ) g ( Q ) + αg ( R ) . (8) Using these notations, we ha v e ϕ ( x , x ′ ) = C n,n ′ + f ( K X , K X + K Y ) , whic h highlights the connection b et w een ϕ ( x , x ′ ) and the Gram matrices K X and K X + K Y . In the con text of k ernel metho ds , the natural question brought forwa rd by this reformulati on is whether the linear dot-pro duct matrices K X and K Y in ϕ or k can b e replaced by arbitrary k ernel matrices K X and K Y b et wee n the vecto rs in R pd and R d en umerated in X and Y , and the resulting quan tit y still b e a v a lid p ositive definite k ernel b et we en x and x ′ . More generally , sup p ose that x and x ′ are time series of structured ob jects, graph s for instance. In suc h a case, can Equation (7) b e used to defin e a kernel b et w een time series of graphs x and x ′ b y u sing d irectly Gram matrices that measure the similarities b etw een graphs observed in x and x ′ ? W e pro ve h ere this is p ossible. 9 Let u s redefine and introdu ce some n otations to establish this r esult. Given a k -u ple of p oints u = ( u 1 , · · · , u k ) take n in an arbitrary set U , and a p ositiv e kernel κ on U × U w e write K κ ( u ) for the k × k Gram matrix K κ ( u ) def = κ ( u i , u j ) 1 ≤ i,j ≤ k . F or t w o lists u and u ′ , w e write u · u ′ for the concatenation of u and u ′ . Recall that an empirical measure µ on a measurable set X is a finite sum of weigh ted Dirac masses, µ = P n i =1 t i δ u i , where the u i ∈ X are the lo cations and the t i ∈ R + the weig hts of suc h masses. Lemma 3. F or two empiric al me asur es µ and µ ′ define d on a set X by lo c ations u = ( u 1 , · · · , u k ) and u ′ = ( u ′ 1 , · · · , u ′ l ) and weig hts t = ( t 1 , · · · , t k ) ∈ R k + and t ′ = ( t ′ 1 , . . . , t ′ l ) ∈ R l + r e sp e ctively, the function ξ : ( µ, µ ′ ) 7→ log | K κ ( u · u ′ ) diag ( t · t ′ ) + I k + l | is a ne gative definite kernel. Pr o of. W e follo w the app roac h of the pr o of of Cutu ri et al. [2005, Th eorem 7]. Consider m measures µ 1 , · · · , µ m and m real weigh ts c 1 , · · · , c m suc h that P m i =1 c i = 0. W e pro ve that the qu an tit y m X i,j =1 c i c j ξ ( µ i , µ j ) , (9) is necessarily non-p ositiv e. Consider the fi n ite set S of all lo cations in X enumerate d in all measures µ i . F or eac h p oint u in S , we consider the fu nction κ ( u, · ) in the r ep ro ducing k ernel Hilb ert space H of functions defined by κ . Let H S def = sp an { κ ( u ) , u ∈ S } b e the fin ite dimensional s u bspace of H sp anned by all images in H of elements of S b y th is mapp in g. F or eac h empirical measures µ i w e consider its counte rp art ν i , th e emp irical measure in H S with the same w eigh ts and lo cations d efined as the mapp ed lo cations of µ i in H S . Since f or t w o p oints u 1 , u 2 in S we ha v e b y the r epro du cing prop ert y that h κ ( u 1 , · ) , κ ( u 2 , · ) i = κ ( u 1 , u 2 ), w e obtain that ξ ( µ i , µ j ) = − 1 2 log τ ( ν i , ν j ) w h ere τ is in this case cast as a p ositiv e definite k ernel on the Eu clidean space H S . Hence th e left hand side of Equation (9) is nonnegativ e b y n egativ e definiteness of − 1 2 log τ . W e no w consider t w o time s er ies x and x ′ taking v alues in an arbitrary space X . F or any sequence x = ( x 1 , · · · , x n ) we write x j i where 1 ≤ i < j ≤ n for th e sequence ( x i , x i +1 , · · · , x j ). T o summ arize the transitions en umerated in x and x ′ w e consider the sequen ces of sub se- quences X = ( x p 1 , x p +1 2 , · · · , x n − 1 n − p +1 ) , X ′ = ( x ′ p 1 , x ′ p +1 2 , · · · , x ′ n ′ − 1 n ′ − p +1 ) , and Y = ( x p +1 , · · · , x n ) , Y ′ = ( x ′ p +1 , · · · , x ′ n ′ ) . Considering n o w a p.d. k ernel κ 1 on X p and κ 2 on X we can bu ild Gram matrices, K 1 = K κ 1 ( X · X ′ ) , K 2 = K κ 2 ( Y · Y ′ ) . 10 Theorem 3. Given two time series x , x ′ in X N , the autor e gr essive ne gative definite kernel ϕ κ of or d er p , p a r ameter 0 < α ≤ 1 and b ase kernels κ 1 and κ 2 define d as ϕ κ ( x , x ’) = C n,n ′ + f ( K 1 , K 1 + K 2 ) , is ne gative definite. Pr o of. ϕ κ is negativ e defin ite as the sum of three n egativ e definite ke rnels: C n,n ′ is an additiv e function in n an d n ′ and is thus trivially negativ e defi n ite. T he term (1 − α ) log | K X + ∆ − 1 | can b e cast as (1 − α ) times the negativ e definite k ernel ξ defined on m easures of X p with k ernel κ 1 while the term α log | K X + K Y + ∆ − 1 | is α times the negativ e defin ite k ernel ξ defined on measures of X p × X w ith k ernel κ 1 + κ 2 . 3.2 Appro ximations Using Lo w-Rank F actor izations W e consider in this section matrix factorizat ion tec hniques to approximat e the k ernel matrices K 1 and K 1 + K 2 used to compu te ϕ κ ( x , x ′ ) by low ran k matrices. Th eorem 5 p ro vides a useful to ol to cont rol the tr ad eoff b et wee n the accuracy and the computational sp eed of this appro ximation. 3.2.1 Computing f using low-rank matrices Consider an N × m 1 matrix g 1 and an N × m 2 matrix g 2 suc h that G 1 def = g 1 g T 1 appro ximates K 1 and G 2 def = g 2 g T 2 appro ximates K 1 + K 2 . Namely , suc h that the F rob enius norms of the differences ε 1 def = K 1 − G 1 , ε 2 def = K 1 + K 2 − G 2 , are small, where the F rob en iu s norm of a matrix M is k M k def = √ tr M T M . Computing f ( G 1 , G 2 ) requires an ord er of O ( N ( m 1 + m 2 ) 2 + m 3 1 + m 3 2 ) op erations. T ec h- niques to obtain such matric es g 1 and g 2 range from standard tru n cated eige nv alue decomp o- sitions, s uc h as the p o wer metho d, to incomplete Cholesky decomp ositions [Fine and S chein b erg, 2002, Bac h and Jordan, 2005] and Nystrm metho ds [Williams and S eeger, 2001, Drineas and Mahoney, 2005] whic h are arguably the most p opu lar in the kernel metho ds literature. The analysis we prop ose b elo w is v al id for an y factorizat ion m etho d. Prop osition 4. L et 0 ≤ α ≤ 1 , then f define d in E quation (8) is a strictly c o nc ave f unction of ( S + N ) 2 which is strictly incr e asing in the sense that f ( Q 1 , R 1 ) < f ( Q 2 , R 2 ) if Q 2 ≻ Q 1 and R 2 ≻ R 1 . Pr o of. Th e gradien t of g : Q 7→ log | Q + ∆ − 1 | is ∇ g ( Q ) = ( Q + ∆ − 1 ) − 1 whic h is thus a p ositiv e definite matrix. As a consequence, f is a strictly incr easing function. The Jacobian of this gradien t ev aluated at Q is the linear map ε ∈ S + n 7→ − tr( Q + ∆ − 1) − 1 ε ( Q + ∆ − 1 ) − 1 . F or an y matrix C ≻ 0 the Hessian of g computed at Q is th us the quadratic form ∇ 2 g ( Q ) : ( ε, ν ) → − tr( Q + ∆ − 1 ) − 1 ε ( Q + ∆ − 1 ) − 1 ν Since tr U V U V = tr(( √ U V √ U ) 2 ) > 0 for any tw o matrices U, V ≻ 0, ∇ 2 g ( Q )( ε, ε ) is n egativ e for any p ositiv e definite matrix ε . Hence the Hessian of f is min us a p ositiv e definite qu adratic form on ( S + N ) 2 and thus f is strictly conca v e. 11 W e use a fi rst ord er argumen t to b ound the difference b et wee n the approxima tion and the tru e v alue of f ( K 1 , K 1 + K 2 ) u s ing terms in k ε 1 k and k ε 2 k : f ( K 1 , K 1 + K 2 ) − (1 − α ) h∇ g ( G 1 ) , ε 1 i − α h∇ g ( G 2 ) , ε 2 i ≤ f ( G 1 , G 2 ) ≤ f ( K 1 , K 1 + K 2 ) . Theorem 5. Given two time series x , x ’ , for any low r an k appr oximations G 1 and G 2 in S + N such that G 1 K 1 and G 2 K 1 + K 2 we have that e − ϕ κ ( x , x ’) ≤ e − C n,n ′ − f ( G 1 , G 2 ) ≤ (1 + ρ ) e − ϕ κ ( x , x ’) , wher e ρ def = exp ( (1 − α ) k∇ g ( G 1 ) kk ε 1 k + α k∇ g ( G 2 ) kk ε 2 k ) − 1 . Pr o of. Immed iate giv en that f is conca v e and increasing . 3.2.2 Early stopping criterion Incomplete Cholesky decomp osition and Nystrm metho ds can build iterativ ely a series of matrices g 1 ,t and g 2 ,t ∈ R N × t , 1 ≤ t ≤ N su c h that G 1 ,t def = g 1 ,t g T 1 ,t and G 2 ,t def = g 2 ,t g T 2 ,t increase resp ectiv ely to w ards K 1 and K 1 + K 2 as t go es to N . T he series g 1 ,t and g 2 ,t can b e ob tained without ha ving to compute exp licitly th e whole of K 1 nor K 1 + K 2 except for their diagonal. The iterativ e compu tations of G 1 ,t and G 2 ,t can b e halted whenev er an up p er b oun d for eac h of the norm s k ε 1 ,t k and k ε 2 ,t k of the residues ε 1 ,t def = K 1 − G 1 ,t and ε 2 ,t def = K 1 + K 2 − G 2 ,t go es b elo w an appro ximation thr eshold. Theorem 5 can b e used to pr o duce such a stopping criterion by a rule which com bines an upp er b ound on k ε 1 ,t k and k ε 2 ,t k and the exact norm of the gradien ts of g at G 1 ,t and G 2 ,t . This w ould require computing F rob enius norms of the matrices ( G i,t + ∆ − 1 ) − 1 , i = 1 , 2. These m atrices can b e up dated iterativ ely using rank-one u p dates. A s im p ler alternativ e whic h we consider is to b ound k∇ g ( G i,t ) k un iformly b etw ee n 0 and K us ing the inequ alit y ( G i,t + ∆ − 1 ) − 1 ∆ , i = 1 , 2 . whic h y ields the follo wing b ound: e − ϕ κ ( x , x ′ ) ≤ e − C n,n ′ − f ( G 1 , G 2 ) ≤ e − ϕ κ ( x , x ′ ) e 1 2 q N ( n − p )( n ′ − p ) ((1 − α ) k ε 1 k + α k ε 2 k ) W e consider in the exp erimental s ection the p ositiv e definite kernel e − tϕ κ , that is the scaled exp onentia tion of ϕ κ m ultiplied by a b an d width parameter t > 0. S etting a target tolerance σ > 0 on the ratio b et we en the appr oximati on of e − tϕ κ and its true v alue, namely r equiring that e − tϕ κ ( x , x ′ )) ≤ e − t ( C n,n ′ + f ( G 1 , G 2 ) ) ≤ (1 + σ ) e − tϕ κ ( x , x ′ )) , can b e ensured by stopping the factorizations at an iteratio n t suc h that (1 − α ) k ε 1 ,t k + α k ε 2 ,t k ≤ 2 log(1 + τ ) t r ( n − p )( n ′ − p ) N . 12 whic h w e simplify to p erforming the f actorizat ions separately , and stopping at the lo w est iterations t 1 and t 2 suc h th at k ε 1 ,t 1 k ≤ log(1 + τ ) (1 − α ) t r ( n − p )( n ′ − p ) N , k ε 2 ,t 2 k ≤ log(1 + τ ) αt r ( n − p )( n ′ − p ) N . (10) W e provide in Figure 2 of Section 4.4 an exp erimen tal assessmen t of this sp eed/accuracy tradeoff wh en computing the v alue of ϕ κ . 4 Exp erimen ts W e pro vide in th is section a fair assessmen t of the p erformance and efficiency of auto regressive k ernels on differen t tasks. W e detail in Section 4.1 th e d ifferen t k ernels w e consider in this b enchmark. Section 4.2 and 4.3 in tro du ce the to y and r eal-life datasets of this b enchmark, results are present ed in Section 4.4 b efore reac hing the conclusion of this p ap er. 4.1 Kernels and parameter tuning The kernels w e consider in this exp eriment al section are all of the form K = e − 1 t Φ , w here Φ is a negativ e definite kernel. W e s elect for eac h kernel K the v alue of the bandwid th t as the median v al ue ˆ m Φ of Φ on all pairs of time series observed in th e training fold times 0 . 5, 1 or 2, namely t ∈ { . 5 ˆ m Φ , ˆ m Φ , 2 ˆ m Φ } . The s election is based on the cross v al- idation error on the training fold f or eac h (ke rnel,dataset) p air. Some k ernels describ ed b elo w b ear the sup erscript · κ , whic h means that they are p arameterized b y a base kernel κ . G ive n t w o times series x = ( x 1 , · · · , x n ) and x ′ = ( x ′ 1 , · · · , x ′ n ′ ), this base kernel κ is used to compu ted similarities b et we en single comp onents κ ( x i , x ′ j ) or p-u ples of comp onen ts κ (( x i +1 , · · · , x i + p ) , ( x ′ j +1 , · · · , x ′ j + p )). F or all sup erscripted kernels b elo w, κ is set to b e the Gaussian k ernel b etw een t w o v ectors κ ( x, y ) = e −k x − y k 2 / (2 σ 2 ) , wh ere the dimension is obvious from the context and is either d or pd . The v a riance parameter σ 2 is arbitrarily set to b e the median v alue of all Euclidean distances k x ( r ) i − x ( s ) j k where i ≤ | x ( r ) | , j ≤ | x ( s ) | , ( r , s ) ∈ R 2 , where R is a r andom su b set of { 1 , 2 , · · · , # training p oin ts } Autoregressiv e kernels k ar , k κ ar : W e consider th e k ernels k ar = e − t ar ϕ , k κ ar = e − t κ ar ϕ κ , parameterized by the band widths t ar and t κ ar . W e set parameters α and p as α = 1 / 2 and p = 5 in all exp er im ents. The matrix factorizations used to compute app ro ximations to k κ ar (with τ set to 10 − 4 ) can b e p erformed using the chol _gauss r outine prop osed by Shen et al. [2009]. Since runn in g separately th is routine for K 1 and K 1 + K 2 results in dup licate computations of p ortions of K 1 , we ha ve added our mo difications to this routine in order to cac he v alues of K 1 that can b e reused when ev aluat ing K 1 + K 2 . The r outine TwoCholGa uss is a v ailable on our w ebsite, as w ell as other pieces of co de. W e insist on th e fact that, other than α, p and the temp erature t ar , the autoregressiv e kernel k ar do es n ot require an y parameter tu n ing. 13 Bag of v ectors k ernel k κ BoV : A time series ( x 1 , · · · , x n ) can b e considered as a b ag of v ectors { x 1 , · · · , x n } where the time-dep endent information f rom eac h state’s timestamp is delib erately ignored. Tw o time series x and x ′ can b e compared th rough their r esp ectiv e bags { x 1 , · · · , x n } and { x ′ 1 , · · · , x ′ n ′ } by setting ψ κ ( x , x ′ ) def = 1 nn ′ X i ≤ n,j ≤ n ′ κ ( x i , x ′ j ) , and defining the ke rnel k κ BoV ( x , x ′ ) = exp ( − t BoV ( ψ κ ( x , x ) + ψ κ ( x ′ , x ′ ) − 2 ψ κ ( x , x ′ )) where t BoV > 0, see for instance [Hein and Bousquet, 2005]. This relativ ely simple k ernel will act as the baseline of our exp erimen ts, b oth for p erformance and computational time. Global alignmen t k ernel k κ GA : The global alignment k ernel [Cu turi et al., 2007] is a p ositiv e definite k ernel that builds up on the dynamic time w arping framew ork, by considering the soft-maxim um of the alignmen t score of all p ossible alignment s b et wee n t w o time series. W e use an implemen tation of this k ernel distributed on the w eb, and consider the k ernel k κ GA = exp( − t GA GlobalAlignmen t κ ( x , x ′ )), parameterized by the b andwidth t GA . Note that the global alignment ke rnel has not b een p ro v ed to b e infi nitely divisible. Namely , k κ GA is kno wn to b e p ositiv e definite for t GA = 1, and as a consequence for t GA ∈ N , b ut n ot for all p ositiv e v alues. How ev er, the Gram m atrices that w ere generated in these exp eriment s ha v e b een found to b e p ositiv e definite for all v alues of t GA as discussed earlier in this section. This su ggests that k κ GA migh t in deed b e infinitely divisible. Splines Smo ot hing k ernel k S : Kumara et al. [200 8 ] use spline smoothin g tec hniques to map eac h time ser ies ( x 1 , · · · , x n ) on to a m ultiv ariat e p olynomial fun ction p x defined on [0 , 1]. As a pre-pro cessing s tep, eac h time series is mapp ed on to a m ultiv ariat e time series of arbitrary length ˜ x (set to 200 in our exp eriment s) s u c h that ˜ x T ˜ x ′ corresp onds to a relev an t dot-pro duct for these p olynomials. W e ha ve mo difi ed an implemen tation that we receiv ed from the authors in email corresp ondence. Kumara et al. [2008] consider a linear kernel in their original pap er on suc h repr esen tations. W e h a v e f ound that a Gaussian ke rnel b et w een these tw o vec tor representat ions p erforms b etter and use k S = exp( − t S k ˜ x − ˜ x ′ k 2 ). Remark 5. Although pr o mising, the kernel pr op ose d by Jeb ar a et al. [2004, § 4.5] is e mbry- onic and le aves many op en questions on its pr actic al implementation. A simple i mplementa- tion using V AR mo dels would not work with these exp eriments, sinc e for many datasets the dimension d of the c onsider e d time series is c omp ar able to or lar g e r than their lengths’ and would pr event any estimation of the ( pd 2 + d ( d + 1) / 2) p ar ameters of a V AR ( p ) mo del. A mor e advanc e d implementation not detaile d in the original p ap er would b e b eyond the sc op e of this work. We have also trie d to implement the fairly c omplex families of kernels describ e d by Vishwanathan et al. [2007] , namely Equations (10) and (16) i n that r ef e r e nc e, b u t our implementations p erforme d v ery p o orly on the datasets we c on sider e d, and we henc e de cide d not to r ep ort these r esults out of c onc erns for the v alidity of our c o des. Despite r e p e a te d attempts, we c ould not obtain c om puter c o des for these kernels fr om the authors, a pr oblem also r ep orte d in [Li n et al., 2008]. 4.2 T o y dataset W e s tu dy the p erformance of these k ernels in a simple binary classification to y exp erimen t that illustrates some of the merits of autoregressiv e k ernels. W e consid er high dimensional 14 time series ( d = 1000) dimensional of short length ( n = 10) generated randomly using one of t w o V AR(1) mo dels, x t +1 = A i x t + ε t , i = 1 , 2 , where the pr o cess ε t is a white Gauss ian noise with co v ariance matrix . 1 I 1000 . Eac h time series’ in itial p oin t is a rand om ve ctor wh ose comp on ents are eac h distributed r andomly follo wing the uniform d istribution in [ − 5 , 5]. T he t w o matrices A i , i = 1 , 2, are sp arse (10% of non-zero v alues, that is 100.000 n on zero en tries out of p otentia lly one million) and hav e en tries that are rand omly distrib uted f ollo wing a standard Gaussian la w 2 . T hese matrices are divid ed b y th eir s p ectral r adius to ensur e that th eir largest eigenv alue has n orm smaller than one to ensur e their stationarit y . W e d r a w randomly 10 time series with transition matrix A 1 and 10 times with transition matrix A 2 and u se these 20 time series as a training set to learn an SVM that ca n discriminate b et wee n time series of t yp e 1 or 2. W e d ra w 100 test time series for eac h class i = 1 , 2, th at is a total of 200 time series, and test the p erformance of all k ernels follo wing the proto col outlined ab o v e. The test error is represent ed in the leftmost bar plot of Figure 1. The autoregressiv e kernel k ar ac hiev es a remark able test error of 0, whereas other k ernels, includin g k κ ar , mak e a not-so-surpr isingly larger n umb er of mistake s, giv en the difficult y of this task. One of the strongest app eals of the autoregressive k ernel k ar is that it manages to quantify a dyn amic similarity b et w een tw o time series (something that neither the Kum ara kernel or an y k ernel based on alignmen ts ma y ac hiev e with so few s amp les) without resorting to the actual estimation of a dens ity , whic h wo uld of course b e imp ossib le giv en the samples’ length. 4.3 Real-life datasets W e assess the p erformance of the kernels prop osed in this p ap er using different b en chmark datasets and other kn o wn k ernels for time series. Th e datasets are all tak en from the UCI Mac hine Lea rnin g r ep ository [F rank and Asuncion, 2010], except for the PEMS dataset whic h w e ha v e compiled. The datasets c haracteristic s’ are summarized in T able 1. Japanese V o wels : Th e database r ecords utterances by nine male sp eake rs of tw o Japanese v o we ls ‘a’ and ‘e’ successiv ely . Eac h utterance is describ ed as a time series of LPC cepstrum co efficien ts. Th e length of eac h time series lies within a range of 7 to 29 observ ati ons, eac h observ ation b eing a ve ctor of R 12 . T he task is to guess w hic h of the nine sp eak ers pronounces a n ew utterance of ‘a’ or ‘e’. W e use the original split prop osed b y the authors, namely 270 u tterances for training and 370 for testing. Libras Mo v emen t Data Set : LIBRAS is the acron ym for the b razilian sign language. The observ ations are 2-dimensional time series of length 45. Eac h time series describ es the lo cation of the gravit y cente r of a hand ’s co ord inates in the visual plane. 15 different signs are considered, the training set has 24 in stances of eac h class, for a total 360 = 24 × 15 time series. W e consider another dataset of 585 time series for the test set. Handwritten c haracters : 2858 recordings of a p en tip tra jectory w ere taken fr om the same writer. Eac h tr a jectory , a 3 × n matrix wh er e n v aries b etw een 60 and 182 r ecords the lo cation of the p en and its tip force. E ach tra j ectory b elongs to one out of 20 d ifferen t classes. The data is split into 2 balanced folds of 600 examples for training and 2258 examples for testing. Australian La nguage of Signs : S ensors are set on the t wo hand s of a nativ e signer comm unicating with the A USLAN sign language. T here are 11 sensors on eac h hand and 2 In Matlab notation, A = sprandn(1000,.1) 15 Database d n classes # train #test T oy dataset 1000 10 2 20 200 Japanese V o we ls 12 7-29 9 270 370 Libras 2 45 15 360 585 Handwritten Ch aracters 3 60-18 2 20 60 0 2258 A USLAN 22 45-136 95 600 1 865 PEMS 963 144 7 26 7 173 T able 1: Chara cteristics of the different databa ses considered in the b enchmark test hence 22 co ordinates for eac h observ ation of the time series. Th e length of eac h time series ranges from 45 to 13 6 measurements. A sample of 27 d istinct recordings is p erformed for eac h of th e 95 considered signs, w hic h totals 2565 time series. These are split b et w een balanced train and tests s ets of size 600 and 1865 resp ectiv ely . Eac h time s eries in b oth test and training s ets is cente red in dividually , that is x ( i ) is r eplaced b y x ( i ) − ¯ x ( i ) . Without such a cen tering the p erformance of all k ernels is seriously degraded, except for the autoregressiv e k ernel whic h remains v ery comp etitiv e with an error b elow 10%. PEMS Database : W e hav e do wnloaded 15 mon ths worth of daily d ata from the Cali- fornia Department of T ran s p ortation PEMS website 3 . Th e data describ es measuremen ts at 10 min ute in terv a ls of occup an cy rate, b et wee n 0 and 1, of differen t car lanes of the San F rancisco bay area (D04) freewa y sys tem. The measuremen ts co v er the p erio d from J an uary 1st 2008 to Marc h 30th 2009. W e consider eac h day of measurements as a sin gle time se- ries of dimension 963 (the n umber of sensors whic h fu nctioned consisten tly throughout the studied p erio d) and length 6 × 24 = 144. The task is to classify eac h da y as the correct da y of the week, from Monda y to Sunday , e.g. lab el it with an int eger b et w een 1 and 7. W e remo v e pu b lic h olidays fr om the d ataset, as wel l as t w o d ays w ith anomalies (Marc h 8 2009 and Marc h 9 2008 ) where all sensors ha v e b een seemingly turned off b etw een 2:00 and 3:00 AM. This lea v es 440 time series in total, wh ic h are shuffled and split b etw ee n 267 training observ ati ons and 173 test observ ati ons. W e p lan to donate this dataset to the UCI rep ository , and it should b e av ailable shortly . In the mean time, the dataset can b e accessed in Matla b format on our website. 4.4 Results and computational sp eed The kernels introdu ced in the Section ab ov e are paired with a standard multicl ass S VM implemen tation using a one-v ersus-rest approac h. F or eac h ke rnel and training set pair, the SVM constant C to b e used on th e test set was c hosen as either 1, 10 or 100, whichev er ga v e the lo w est cross-v al idation mean-error on the training fold. W e rep ort th e test errors in Figure 1. The errors on the test sets can b e also compared with th e a ve rage compu tation time p er k ernel ev aluatio n graph disp la y ed for 4 d atasets in Figure2. In terms of p erformance, the autoregressiv e kernels p erform fa v orably w ith resp ect to other k ernels, notably the Global Alignmen t ke rnel, which is u sually v ery difficult to b eat. Th eir computational time offer a diametrically opp osed p ersp ectiv e sin ce for these b enc hmarks datasets the flexibilit y of u sing a ke rnel κ to enco d e the inp uts in a R K HS do es not yield p ractical gains in p erformance but h as a tremendously h igh computational price. On the cont rary , k ar is b oth efficient and usually very fast compared to the other ke rnels. 3 http://pem s.dot.ca.gov 16 Toy Dataset AUSLAN PEMS 0 0.1 0.2 0.3 0.4 0.5 Error on test fold Japanese Vowels Libras Handwritten 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 Error on test fold AR kernel AR kernel using κ Bag−of−Vectors kernel GA kernel Spline Smoothing Kernel Figure 1: T est er ror o f the 5 consider ed kernels on 5 different tasks s plit into t wo panels for b etter leg ibilit y of the er ror r ates (notice the differe nce in scale). The AR kernel has a test-error o f 0 on the toy dataset’s test fold. 4.5 Conclusion and Discussion W e ha v e pr op osed in this w ork t wo infinitely divisible k ernels k ar and k κ ar for time series. T h ese k ernels can b e used within the framew ork of kernel machines, e.g. the SVM or k ernel-PCA, or more generally as Hilb ertian d istances b y using directly their logarithms ϕ v ar and ϕ κ v ar once prop erly normalized. The first kernel k ar computes a similarit y b et w een t w o m ultiv ariat e time series with a lo w compu tational cost. This similarit y is easy to implement, easy to tune giv en its infinite divisib ility , and often p erforms similarly or b etter than m ore costly alternativ es. The second k ernel, k κ ar , is a generalizatio n of k ar that can handle structured data b y considering a lo cal k ernel κ on the structures. Its computation r equires the computation of all or a part of large Gram matrices as well as the determinant of these. Giv en its computational dra wbac ks, the exp erimenta l evidence gathered in this pap er is n ot suffi cien t to advocate its u se on v ectorial data. Moreo v er, El Karoui [2010] has recen tly sho wn th at the sp ectrum of a Gram matrix of high-dimensional p oints using the Gaussian ke rnel ma y , under certain assump tions, b e v ery s im ilar to the sp ectrum of the standard Gram matrix of these same p oints usin g the linear dot-pro du ct. In suc h a case, the soph istication brought forw ard by k κ ar migh t b e gratuitous and yield similar r esults to th e dir ect use of k ar . Ho we ve r, w e b eliev e that k κ ar ma y pro ve particularly useful when considering time series of structured data. F or instance, w e plan to app ly the kernel k κ ar to the classification of video segmen ts, where eac h segmen t wo uld b e represented as a time v arying histogram of features and κ a suitable k ernel on histograms that can take int o accoun t the similarit y of features themselves. Our con tribution follo ws the blu eprint lai d do wn by Seeger [2002] whic h can b e effectiv ely applied to other exp onen tial mo dels. Ho w ev er, w e b eliev e that the infinite divisibilit y of suc h k ernels, whic h is crucial in practical applications, had not b een considered b efore this w ork. Our result in this r esp ect is not as general as we would wish f or, in the sense that we do not kno w w hether k ar remains infinitely divisible when the degrees of freedom λ of the inv erse Wishart p rior exceed d − 1. In s uc h a case, the conca vit y of f in E quation (8) w ould not b e giv en either. Finally , although the prior that we use to d efine k ar is n on informativ e, it migh t b e of in terest to learn the h yp erparameters for these pr iors based on a data corp us of in terest. 17 10 −6 10 −4 10 −2 10 0 10 −8 10 −6 10 −4 10 −2 10 0 Handwritten Dataset 10 −6 10 −4 10 −2 10 0 10 −8 10 −6 10 −4 10 −2 10 −6 10 −4 10 −2 10 0 10 −3 10 −2 10 −1 10 0 AUSLAN Dataset Average Kernel Computation Time (seconds) PEMS Dataset 10 −6 10 −4 10 −2 10 0 10 −15 10 −10 10 −5 Accuracy parameter Norm of difference 10 −6 10 −4 10 −2 10 0 10 −6 10 −5 10 −4 10 −3 10 −2 10 −6 10 −4 10 −2 10 0 10 −8 10 −6 10 −4 10 −2 AR κ DTW Kumara Gaussian AR Maximum norm Frobenius norm Figure 2: Thes e gr aphs provide o n the left side the av erage time needed to c o mpute one ev aluation o f each o f the 5 kernels on the la rgest datasets. The av erage sp eeds (computed ov er a sample of 50 × 5 0 calculations) for eac h k ernel are quan tified in the y-ax is. The x -axis is only effective for the kernel k κ ar and shows the influence of the accuracy para meter τ on that sp eed using the low-rank matr ix factorization expr ession used for ϕ as descr ib e d in Equation (10). This para meter is se t b etw een 10 0 (po o r approximation) to 1 0 − 7 (high accuracy ). The accura cy is measur ed b y the maxim um norm and the F rob enius norm of the difference b e t ween the t w o 50 × 5 0 ϕ -Gram matrices. Note that k κ GA is fully implemen ted in mex -C co de, k κ ar uses mex - C subro utines for Cholesk y deco mpo sition while all other kernels are implemented using s tandard a lgebra in Matla b. Pr epro cessing times ar e not counted in these av era ges. The sim ulations w ere r un using an iMac 2.66 GhZ Intel Cor e with 4Gb o f memory . 18 References F. R . Bac h and M. I. Jordan. Pred ictiv e lo w-rank d ecomp osition for kernel metho ds. I n Pr o c e e dings of ICML ’05: Twenty-se c ond i nternational c onfer enc e on Machine le arning . A CM P ress, 2005. C. Bahlmann, B. Haasdonk, and H. Bur k h ardt. Online handwriting recognition w ith sup- p ort vec tor mac hines-a k ernel approac h. In F r ontiers in Handwriting R e c o gnition, 2002. Pr o c e e dings. Eighth International Workshop on , pages 49–54, 2002 . C. Berg, J. P . R. Ch r istensen, and P . Ressel. Harmonic Analysis on Semigr oups . Number 100 in Graduate T exts in Mathematics. S pringer V erlag, 1984. A. Berlinet and C. Thomas-Agnan. R epr o ducing K e rnel Hilb ert Sp ac es in Pr o b ability and Statistics . Kluw er Academic Pub lish ers, 2003. K. Borgwa rdt, S. Vishw anathan, and H. Kriegel. Class prediction from time series gene expression profiles using d ynamical systems ke rn els. In P r o c e e dings of the 11th Pacific Symp osium on Bio c o mputing , pages 547–558, 2006. O. Chap elle, P . Haffner, and V. V apnik. SVMs for histogram based image classification. IEEE T r a nsactions on Ne ur a l N etworks , 10(5):10 55, Sept. 1999. C. Cortes, P . Haffner, and M. Mohri. R ational k ernels: Theory and algorithms. The Journal of Machine L e arning R e se ar ch , 5:1035– 1062, 2004. M. Cu turi and K. F ukum izu. Kernels on stru ctured ob jects through nested histograms. I n B. S c h¨ olk opf, J. Pla tt, and T. Hoffman, editors, A dvanc es in Neur al Information P r o c essing Systems 19 . MIT Press, Cambridge, MA, 2007 . M. Cuturi and J.-P . V ert. The con text-tree k ernel for strin gs. Neu r al Networks , 18(8), 2005. M. Cuturi, K. F ukum izu, and J.-P . V ert. S emigroup kernels on measures. Journal of Machine L e arning R ese ar ch , 6:1169–119 8, 2005. M. Cu turi, J.-P . V ert, Øystein. Birk enes, and T. Matsui. A k ernel for time series based on global alignmen ts. In Pr o c e e dings of the International Confer enc e on A c o ustics, Sp e e ch and Signal Pr o c essing , volume I I, pages 413 – 416, 2007. P . Drineas and M. W. Mahoney . On the Nystr¨ om metho d for appro ximating a gram matrix for impr o v ed k ernel-based learning. Journal of M achine L e arning R ese ar ch , 6:215 3–2175, 2005. ISSN 1532-443 5. N. El Karoui. Th e sp ectrum of k ernel r andom matrices. The Annals of Statistics , 38(1):1–5 0, 2010. ISSN 0090-536 4. S. Fine and K . Schein b erg. Effi cient SVM training u s ing lo w-rank k ernel represen tations. Journal of Machine L e ar ning R ese ar ch , 2:243–264, 2002. A. F rank and A. Asuncion. UCI mac hine learning rep ository , ht tp://arc hiv e.ics.uci.edu/ml, 2010. K. Grauman and T. Darrell. The p yramid matc h k ernel: Discriminativ e classification with sets of image features. In ICCV , p ages 1458–14 65. IE E E Compu ter So ciet y , 2005. 19 B. Haasdonk and C. Bahlmann. Learning w ith distance s ubstitution kernels. Pattern R e c o g- nition, Pr o c. of the 26th DA GM Symp osium , pages 220–227 , 2004 . Z. Harc haoui and F. Bac h. Image classificatio n with segmen tation graph k ernels. In CVPR , 2007. D. Haussler. Conv olutio n kernels on discrete s tructures. T ec hnical rep ort, UC Santa Cruz, 1999. USCS-CRL-99-10. A. Ha y ashi, Y. Mizuhara, and N. Suematsu. Em b edding time series data for classification. Machine L e arning and Data Mining in Pattern R e c o gnition , pages 356–3 65, 2005. M. Hein and O. Bousquet. Hilb ertian metrics and p ositiv e definite ke rnels on p robabilit y mea- sures. In Z. Ghahramani and R . Co w ell, editors, Pr o c e e dings of AIST A TS 2005 , Jan uary 2005. T. Hofmann, B. Sc holk opf, and A. Smola. Kern el metho ds in mac hine learning. Anna ls of Statistics , 36(3):1171, 2008. T. Jaakk ola, M. Diekhaus, and D. Haussler. Using the fis h er k ernel metho d to d etect remote protein homologies. 7th Intel l. Sys. Mol. Biol. , pages 149–158 , 1999. T. Jeb ara, R. Kondor, and A. Ho w ard. Probability pro d uct k ernels. Journal of Machine L e arning R ese ar ch , 5:819–844, 2004. T. Joac hims. L e ar ning to Classify T ext Using Supp ort V e ctor Machines: Metho ds, The o ry, and Algor ithms . Kluw er Academic Publishers, 2002. H. Kashima, K. Tsu da, and A. Inokuchi. Marginalized k ernels b et we en lab eled graph s. In T. F aucett and N. Mishra, editors, Pr o c e e dings of the Twentieth International Confer enc e on Machine L e a rning , pages 321–328 . AAAI Pr ess, 2003. K. Kumara, R. Agraw al, and C . Bhattac haryy a. A large margin approac h for writer in- dep end en t online h andwriting classificatio n. Pattern R e c o gnition L etters , 29(7):9 33–937, 2008. G. Leban on . Metric learning for text d o cument s. IEEE T r ansactions on Pattern Analysis and Machine Intel ligenc e , 28(4):497–5 08, 2006. ISSN 0162-882 8. C. Leslie, E. Eskin, and W. S. Noble. Th e sp ectrum k ernel: a string k ernel for s v m protein classific ation. In P r o c. of PSB 2002 , pages 564–5 75, 2002. P . L ´ evy . The arithmetical c haracter of the Wishart distrib ution. In Mathematic al Pr o c e e dings of the Cambridge Philosop hic al So ciety , vo lume 44, pages 295–29 7. Cambridge Univ Press, 1948. T. Lin, N. K aminski, and Z . Bar-Joseph. Alignmen t and classification of time series gene expression in clinical stud ies. Bioinforma tics , 24(13):i147 , 2008. H. L ¨ utk ep ohl. New Intr o duction to Multiple Time Series Ana lysis . Spr inger, 2005. P . Mahe, N. Ueda, Aku tsu, J.-L. T., P erret, and J.-P . V ert. Graph ke rnels for molecular structure-activit y relationship analysis w ith sup p ort vec tor machines. Journal of Chemic al Information and Mo deling , 45(4):939–9 51, 2005. 20 A. Mosc hitti and F. Zanzotto. F ast and effectiv e kernels f or r elational learning from texts. In Pr o c e e dings of the 24th i nternational c onfer enc e on Machine le ar ning , pages 649–656 . A CM, 2007. L. Rabiner and B. Juang. F undamentals of sp e e ch r e c o gnition , vo lume 103. Prent ice hall Englew o o d Cliffs, New Jersey , 1993. H. Sak o ei and S. Chiba. Dynamic p r ogramming algo rithm optimization for sp oken word recognition. IEEE T r ans actions on A c oustics, Sp e e ch, and Signal Pr o c essing , 26:43–49, 1978. T. Schreib er and A. Sc hmitz. Classification of time series d ata with n onlinear similarit y measures. Physic al R eview L e tters , 79(8):1 475–147 8, 1997. M. Seeger. Cov ariance kernels f rom ba y esian generativ e mo d els. I n A dvanc es in Neu r a l Information Pr o c essing Systems 14 , pages 905– 912. MIT Pr ess, 2002. H. Shen, S. J egelk a, and A. Gretton. F ast k ernel-based indep endent comp onent analysis. IEEE T r a nsactions on Signal Pr o c essing , 57(9):3498– 3511, 2009. N. Sherv ashidze and K. Borgw ardt. F ast subtree k ernels on graphs. A d vanc es in N eur al Information Pr o c essing Systems 22 , 2009. H. Shimo d aira, K.-I. Noma, M. Nak ai, and S. Saga y ama. Dynamic time-alignmen t k ernel in su pp ort ve ctor mac hine. In T. G. Dietteric h, S. Bec k er, and Z. Ghahramani, ed itors, A dvan c es in Neur al Information Pr o c essing Systems 14 , C am bridge, MA, 2002. MIT Press. S. Sonnenburg, K. Riec k, F. F. Ida, and G. Rtsch. Large scale learning with string k ernels. In L ar ge Sc a le Kernel Machines , p ages 73–103. MIT Press, 2007 . J.-P . V ert, H. Saigo, and T. Akutsu . Lo cal alignment k ernels for protein sequences. In B. Sch¨ olk opf, K. Tsuda, and J.-P . V ert, editors, Kernel M etho ds in Computationa l Biolo gy . MIT Press, 2004 . S. Vishw anathan and A. S mola. Binet-ca uch y kernels. A dvanc es in Neur al Information Pr o c essing Systems , 17, 2004. S. Vish w anathan, A. Smola, and R. Vidal. Binet-cauc h y kernels on dyn amical systems an d its application to the analysis of dynamic s cenes. International Journal of Computer Vision , 73(1): 95–119, 2007 . S. Vishw anathan, K. Borgwardt, I. Kondor, and N. Sc hraud olph. Graph k ernels. Journal of Machine L e arning R ese ar ch , 9:1–37, 2008. M. W est and J. Harrison. Bayesian for e c asting and dynamic mo dels . Sp ringer V er lag, 1997. C. Williams and M. Seege r. Using the Nystr ¨ om m etho d to sp eed up k ernel mac hines. In A dvan c es in N e ur a l Information Pr o c essing Systems 13 , pages 682–688. MIT Press, 2001 . F. Zhou, F. De la T orre, and J. Cohn. Unsu p ervised disco v ery of facial ev en ts. In Computer Vision and Pattern R e c o gnition (CVPR), 2010 IEEE Confer enc e on , pages 2574–25 81. IEEE, 2010. 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment