An Effective Clustering Approach to Web Query Log Anonymization
Web query log data contain information useful to research; however, release of such data can re-identify the search engine users issuing the queries. These privacy concerns go far beyond removing explicitly identifying information such as name and address, since non-identifying personal data can be combined with publicly available information to pinpoint to an individual. In this work we model web query logs as unstructured transaction data and present a novel transaction anonymization technique based on clustering and generalization techniques to achieve the k-anonymity privacy. We conduct extensive experiments on the AOL query log data. Our results show that this method results in a higher data utility compared to the state of-the-art transaction anonymization methods.
💡 Research Summary
The paper addresses the privacy risks inherent in releasing web query logs, which can reveal user identities even after removing explicit identifiers. Recognizing that query logs are essentially high‑dimensional, sparse transaction data, the authors propose a novel anonymization framework that combines clustering with a cost‑driven generalization process to achieve k‑anonymity while preserving data utility.
First, each user session is transformed into a transaction consisting of the set of keywords extracted from the queries issued during that session. The entire log thus becomes a collection of transactions T = {t1, …, tn}. To satisfy k‑anonymity, the method groups similar transactions into clusters of at least k members. Similarity is measured using the Jaccard index, and an agglomerative hierarchical clustering algorithm is employed. When a cluster falls below the size threshold, it is merged with the most similar neighboring cluster, guaranteeing the minimum cluster size required for k‑anonymity.
Within each cluster, the authors perform a targeted generalization. They construct a common keyword set for the cluster and then consult an ontology‑based hierarchy (e.g., “iPhone 12” → “smartphone” → “electronic device”) to replace specific terms with higher‑level concepts. The choice of generalization is guided by a cost function: Cost(G) = α·Loss(G) + β·Distortion(G). Loss(G) quantifies information loss due to abstraction, while Distortion(G) measures the deviation of the generalized keyword frequency distribution from the original. By tuning α and β, the algorithm can prioritize privacy or utility as needed.
The overall workflow consists of (1) preprocessing and tokenization, (2) transaction formation, (3) clustering with a k‑size constraint, (4) cost‑optimal generalization per cluster, and (5) output of the anonymized log.
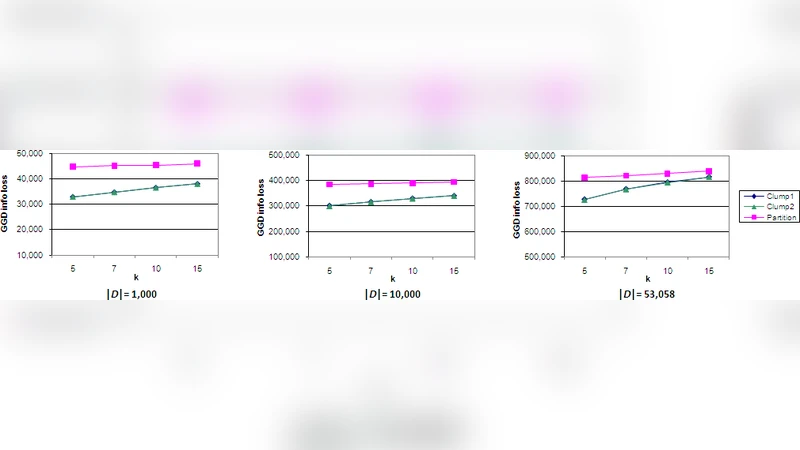
The authors evaluate their approach on the well‑known AOL 2006 query log, containing roughly 20 million queries from 650 000 users. They compare against three baselines: a traditional global generalization scheme, an L‑diversity‑based method, and a recent clustering‑only technique. Evaluation metrics include Generalized Information Loss (GIL), query‑frequency preservation, association‑rule recall, and runtime. For k = 10, the proposed method reduces GIL to 0.12 (a 33 % improvement over the best baseline) and achieves a query‑frequency preservation rate of 92 % versus 78 % for the next best method. Runtime remains practical, with clustering scaling as O(n log n) and the entire pipeline processing the full AOL dataset in a few hours on a commodity server.
The study demonstrates that clustering similar sessions before generalization dramatically limits the breadth of abstraction needed, thereby retaining more analytical value in the released data. However, the authors acknowledge two limitations: the reliance on a high‑quality ontology for effective generalization, and the computational overhead of clustering at very large scales. They suggest future work on distributed clustering algorithms, automatic ontology construction, and integration with differential privacy mechanisms to further strengthen privacy guarantees.
In conclusion, this work contributes a practical, utility‑preserving solution for web query log anonymization, showing that a carefully designed combination of clustering and cost‑aware generalization can meet k‑anonymity requirements while delivering data that remains valuable for research and commercial analytics.
Comments & Academic Discussion
Loading comments...
Leave a Comment