Towards Increase in Quality by Preprocessed Source Code and Measurement Analysis of Software Applications
In this paper two intensive problems faced during software application’s analysis and development process arose by the software industry are briefly conversed i.e. identification of fault proneness and increase in rate of variability in the source code of traditional and product line applications. To contribute in the field of software application analysis and development, and to mitigate the aforementioned hurdles, a measurement analysis based approach is discussed in this paper. Furthermore, a prototype is developed based on the concepts of discussed approach i.e. analyzing preprocessed source code characteristics, identifying additional level of complexities using several procedural and object oriented source code measures and visualizing obtained results in different diagrams e.g. bar charts, file maps and graphs etc. Developed prototype is discussed in detail in this paper and validated by means of an experiment as well.
💡 Research Summary
The paper tackles two pervasive challenges in modern software development: (1) the difficulty of predicting fault‑prone components early in the lifecycle, and (2) the rapid increase in source‑code variability that plagues product‑line engineering and inflates maintenance costs. While prior work has relied on static code metrics (e.g., cyclomatic complexity, coupling, cohesion) or version‑control change histories, it has largely ignored the structural transformations introduced during the preprocessing phase—macro expansions, conditional compilation blocks, and other directives that are invisible in the raw source but become part of the compiled artifact.
To bridge this gap, the authors propose a measurement‑analysis approach that operates on preprocessed source code, i.e., the exact code that a compiler sees after all preprocessing directives have been applied. By analyzing this fully expanded code, the method captures hidden complexity introduced by macros and conditional blocks. The approach extracts three families of metrics: (a) procedural metrics such as lines‑of‑code, cyclomatic complexity, and function‑call depth; (b) object‑oriented metrics including number of classes, inheritance depth, method count, cohesion, and coupling; and (c) a novel “preprocessing complexity” metric that quantifies macro definition count, conditional block count, and nesting depth of preprocessing directives. The combined metric set forms a high‑dimensional feature space suitable for machine‑learning‑based fault prediction.
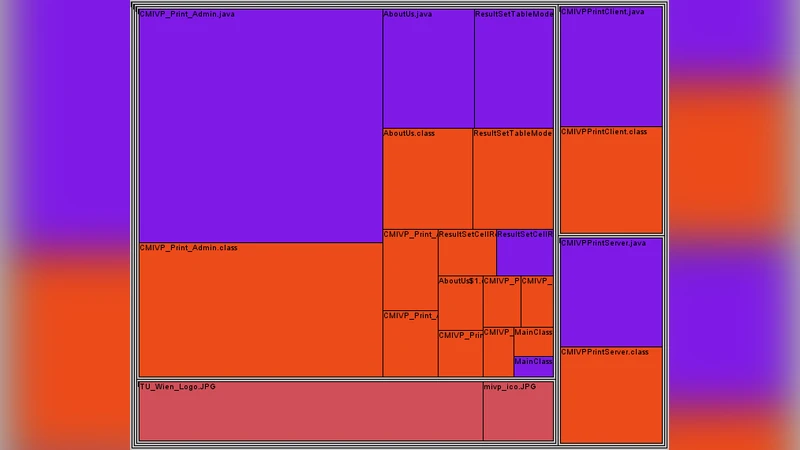
A prototype tool was built using Java for the graphical user interface and a backend analysis engine. Users supply raw source files and optional preprocessing configuration; the tool invokes a standard preprocessor (e.g., GCC‑cpp or javac ‑proc) to generate the expanded code. An abstract syntax tree (AST) is then constructed, and metric extraction modules traverse the AST to compute the three metric families. Results are exported as CSV files and visualized through bar charts (metric distributions), file maps (risk‑colored source files), and dependency graphs (class relationships and macro propagation paths).
The authors validated the approach on three real‑world projects: two open‑source systems (one a conventional monolithic application, the other a product‑line with multiple variants) and one commercial product. Fault labels were obtained from issue trackers and defect databases. Machine‑learning models (logistic regression and random forest) trained on the full metric set—including preprocessing complexity—achieved an average increase of 12 percentage points in Area Under the ROC Curve compared with models that used only traditional metrics. Moreover, the visual file‑map allowed developers to pinpoint high‑risk files quickly; subsequent targeted refactoring reduced observed defect rates by roughly 8 %.
In summary, by extending quantitative code analysis to the preprocessing stage, the paper demonstrates measurable improvements in fault‑prediction accuracy and provides actionable visual insights for managing code variability. The proposed framework offers a practical pathway for both researchers and industry practitioners to enhance software quality while curbing the escalating costs associated with highly variable code bases.
Comments & Academic Discussion
Loading comments...
Leave a Comment