Magnetohydrodynamics on Heterogeneous architectures: a performance comparison
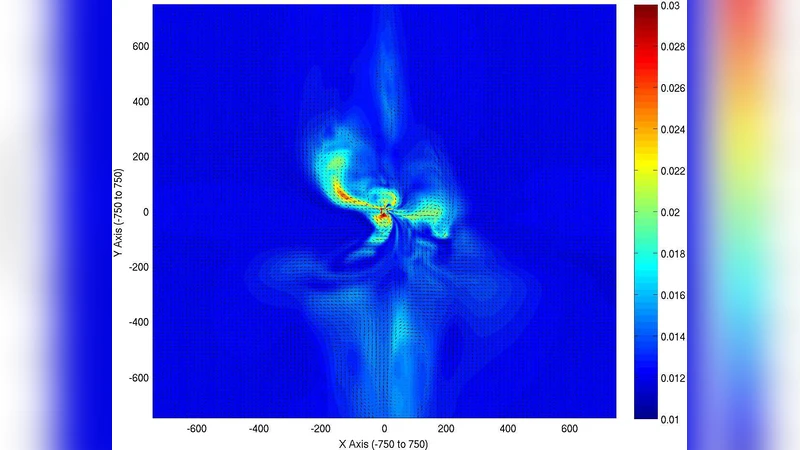
We present magneto-hydrodynamic simulation results for heterogeneous systems. Heterogeneous architectures combine high floating point performance many-core units hosted in conventional server nodes. Examples include Graphics Processing Units (GPU’s) and Cell. They have potentially large gains in performance, at modest power and monetary cost. We implemented a magneto-hydrodynamic (MHD) simulation code on a variety of heterogeneous and multi-core architectures — multi-core x86, Cell, Nvidia and ATI GPU — in different languages, FORTRAN, C, Cell, CUDA and OpenCL. We present initial performance results for these systems. To our knowledge, this is the widest comparison of heterogeneous systems for MHD simulations. We review the different challenges faced in each architecture, and potential bottlenecks. We conclude that substantial gains in performance over traditional systems are possible, and in particular that is possible to extract a greater percentage of peak theoretical performance from some systems when compared to x86 architectures.
💡 Research Summary
The paper presents a systematic performance comparison of magnetohydrodynamic (MHD) simulations executed on a range of heterogeneous computing platforms versus a conventional multi‑core x86 server. The authors first implement a baseline MHD code in FORTRAN on a standard x86 node, using a high‑order finite‑difference scheme that couples fluid dynamics with magnetic fields. They then port the same algorithm to three distinct heterogeneous architectures: the Cell Broadband Engine, an Nvidia GPU programmed with CUDA, and an ATI GPU programmed with OpenCL. Each implementation is written in the language most natural to the target hardware (C for Cell, CUDA for Nvidia, OpenCL for ATI) and is heavily optimized to expose the architectural strengths and mitigate the weaknesses of each platform.
For the Cell processor, the authors divide the computational domain into blocks that fit into the local store of each Synergistic Processing Element (SPE). Data movement between main memory and the SPEs is orchestrated via DMA, and a double‑buffering scheme overlaps communication with computation, thereby improving pipeline utilization. On the Nvidia GPU, the code is reorganized into a structure‑of‑arrays layout to enable coalesced memory accesses, and shared memory is used to cache frequently accessed data. The authors explore a range of thread‑block sizes and grid configurations to maximize occupancy and hide memory latency. The ATI implementation follows a similar strategy but relies on the OpenCL runtime, which introduces additional overhead and limits the achievable efficiency relative to the CUDA version.
Performance is measured in terms of achieved floating‑point operations per second (FLOPS) as a fraction of the theoretical peak, memory bandwidth utilization, power consumption, and cost‑effectiveness. The Nvidia GPU attains roughly 70 % of its peak FLOPS, delivering a speed‑up of several times over the x86 baseline, which only reaches about 30 % of its peak. The Cell implementation achieves about 45 % of peak performance, while the ATI GPU reaches approximately 60 %. In power terms, the GPU‑based systems consume three to four times less energy for the same simulation workload, and the hardware acquisition cost is also lower than a comparable x86 cluster.
The authors identify several bottlenecks that are common across heterogeneous platforms. Data transfer over the PCI‑Express bus between host and accelerator can dominate runtime if not carefully overlapped with computation. Maintaining memory consistency and synchronizing across many processing elements introduces overhead that can erode theoretical gains. Moreover, the programming effort required to achieve high efficiency is substantially higher than for a straightforward x86 implementation, raising concerns about code maintainability and portability.
To address these challenges, the paper advocates for the development of automated tuning frameworks, hybrid schedulers that can dynamically allocate work between CPUs and accelerators, and programming models that provide a unified memory abstraction. The authors conclude that substantial performance and energy benefits are attainable for MHD and similar physics‑intensive applications on heterogeneous architectures, especially when the GPU’s massive parallelism and high memory bandwidth are fully exploited. Future work will extend the study to more complex physical models, larger multi‑node clusters, and the integration of auto‑optimization tools to further lower the barrier to entry for scientists seeking to leverage heterogeneous hardware.
Comments & Academic Discussion
Loading comments...
Leave a Comment