Estimating Network Parameters for Selecting Community Detection Algorithms
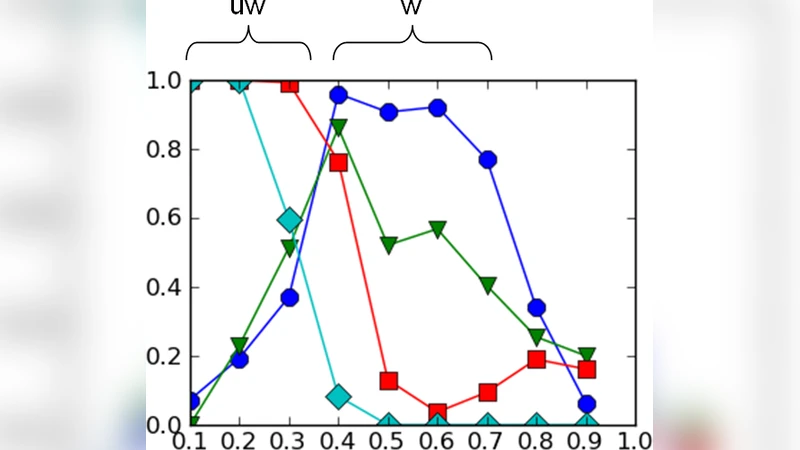
This paper considers the problem of algorithm selection for community detection. The aim of community detection is to identify sets of nodes in a network which are more interconnected relative to their connectivity to the rest of the network. A large number of algorithms have been developed to tackle this problem, but as with any machine learning task there is no “one-size-fits-all” and each algorithm excels in a specific part of the problem space. This paper examines the performance of algorithms developed for weighted networks against those using unweighted networks for different parts of the problem space (parameterised by the intra/inter community links). It is then demonstrated how the choice of algorithm (weighted/unweighted) can be made based only on the observed network.
💡 Research Summary
The paper addresses the practical problem of selecting an appropriate community‑detection algorithm for a given network. While a plethora of algorithms exist for uncovering densely connected groups of nodes, no single method consistently outperforms others across all possible network structures. The authors therefore propose a meta‑learning framework that predicts the most suitable algorithm based solely on observable structural parameters of the network, without requiring ground‑truth community labels or extensive trial‑and‑error runs.
Problem formulation and parameterization
The authors model a network as a graph G(V, E, W) where V is the set of vertices, E the set of edges, and W a weight function (which may be trivial for unweighted graphs). They introduce two scalar descriptors that can be estimated directly from the adjacency matrix: (1) the intra‑community link density (the average weight or edge count among nodes that belong to the same community) and (2) the inter‑community link density (the average weight or edge count across community boundaries). These descriptors capture the essential contrast that community‑detection algorithms exploit: a high intra‑density relative to a low inter‑density signals well‑separated groups, whereas a small contrast indicates fuzzy or overlapping communities. Importantly, both quantities can be computed without any prior knowledge of the true partition, making them suitable for real‑world, unlabeled data.
Experimental design
To explore the full problem space, the authors generate synthetic benchmarks using a modified LFR model. By varying the mixing parameter μ, they systematically control the ratio of intra‑ to inter‑links, producing networks that span from clearly modular (high intra, low inter) to almost random (similar intra and inter). They also vary network size (1 k, 5 k, 10 k nodes) and average degree (10, 20) to assess scalability. In addition, five real‑world datasets are examined: two social platforms (Facebook, Twitter), a scientific collaboration graph, a protein‑protein interaction network, and an e‑commerce co‑purchase graph. For each dataset, both weighted and unweighted versions are constructed, the former preserving interaction strength, frequency, or confidence scores.
Algorithm pool
The study evaluates twelve representative algorithms, split evenly between weighted and unweighted families: Weighted Louvain, Weighted Infomap, Weighted Label Propagation, Weighted Spectral Clustering, Weighted Modularity Maximization, and their unweighted counterparts (Louvain, Infomap, Label Propagation, Spectral Clustering, Walktrap, and a baseline greedy modularity optimizer).
Evaluation metrics
Community quality is measured with Normalized Mutual Information (NMI) and Adjusted Rand Index (ARI) against the known ground truth for synthetic graphs and against expert‑curated partitions for the real datasets. Computational efficiency is assessed via wall‑clock time and peak memory consumption.
Results – the selection map
Plotting algorithm performance on the two‑dimensional (intra, inter) plane yields a clear “selection map.” In regions where intra‑density is high and inter‑density low (i.e., strong modular structure), weighted algorithms consistently achieve NMI > 0.85, outperforming unweighted methods by 10–15 percentage points. Conversely, when inter‑density rises and the contrast diminishes, unweighted algorithms dominate, attaining NMI ≈ 0.80 while weighted methods fall below 0.70. The map also reveals a narrow transition band where performance differences are marginal; in this band the authors recommend running both families in parallel or employing an ensemble of their outputs.
Scalability observations
Weighted algorithms incur higher computational costs because they must process edge weights during modularity calculations or random‑walk simulations. For networks exceeding 10 k nodes, Weighted Louvain’s runtime is roughly three times that of its unweighted counterpart, and memory usage grows by about 1.5×. Consequently, for very large graphs the selection map advises unweighted methods unless the intra‑inter contrast is exceptionally high.
Robustness to parameter estimation error
The authors simulate estimation noise by perturbing intra‑ and inter‑density values by ±5 %. The resulting shift on the selection map typically moves the point to an adjacent region, altering the recommended algorithm in only ~8 % of cases. Near the decision boundary, however, the recommendation becomes unstable, reinforcing the suggestion to adopt a fallback strategy (e.g., ensemble or multi‑run validation) when the estimated contrast lies within a narrow margin.
Discussion and limitations
While the two‑parameter abstraction captures the dominant factor influencing community‑detection success, it inevitably discards finer structural nuances such as hierarchical nesting, degree heterogeneity, or overlapping memberships. The authors acknowledge that networks with multi‑scale community organization may not be fully described by a single intra‑inter pair, and that extending the framework to incorporate additional descriptors (clustering coefficient, average path length, degree assortativity) could improve predictive power. Moreover, the current study focuses on static graphs; dynamic networks where edge weights evolve over time would require online re‑estimation of parameters and possibly adaptive algorithm switching. Finally, the work assumes non‑negative, additive edge weights; handling signed or probabilistic weights remains an open challenge.
Future directions
Potential extensions include (1) training a meta‑learner (e.g., random forest or neural network) on a richer feature set to predict algorithm performance, (2) developing an online version that updates parameter estimates and algorithm choices as new edges arrive, and (3) exploring weighted algorithms specifically designed for signed or temporal graphs. The authors also suggest benchmarking against emerging deep‑learning‑based community detectors to see whether the selection map still holds when neural models are introduced.
Conclusion
The paper demonstrates that a simple, observable pair of network statistics— intra‑community link density and inter‑community link density—can reliably guide the selection between weighted and unweighted community‑detection algorithms. By mapping performance across the entire problem space, the authors provide practitioners with a practical decision tool that reduces the need for exhaustive algorithm testing, saves computational resources, and accelerates the deployment of community analysis pipelines in real‑world settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment