Parallel Sparse Matrix Solver on the GPU Applied to Simulation of Electrical Machines
Nowadays, several industrial applications are being ported to parallel architectures. In fact, these platforms allow acquire more performance for system modelling and simulation. In the electric machines area, there are many problems which need speed-up on their solution. This paper examines the parallelism of sparse matrix solver on the graphics processors. More specifically, we implement the conjugate gradient technique with input matrix stored in CSR, and Symmetric CSR and CSC formats. This method is one of the most efficient iterative methods available for solving the finite-element basis functions of Maxwell’s equations. The GPU (Graphics Processing Unit), which is used for its implementation, provides mechanisms to parallel the algorithm. Thus, it increases significantly the computation speed in relation to serial code on CPU based systems.
💡 Research Summary
The paper investigates the use of modern graphics processing units (GPUs) to accelerate the solution of large, sparse, symmetric positive‑definite linear systems that arise in finite‑element simulations of electrical machines. The authors focus on the Conjugate Gradient (CG) method, which is well‑suited to such systems, and they implement the algorithm entirely on the GPU using NVIDIA’s CUDA platform. Three sparse matrix storage formats are examined: standard compressed sparse row (CSR), symmetric CSR (SCSR), and compressed sparse column (CSC). The matrix used in the experiments is a 30 880 × 30 880 symmetric matrix containing 449 798 non‑zero double‑precision entries, derived from a Maxwell‑equation based simulation of an electric machine.
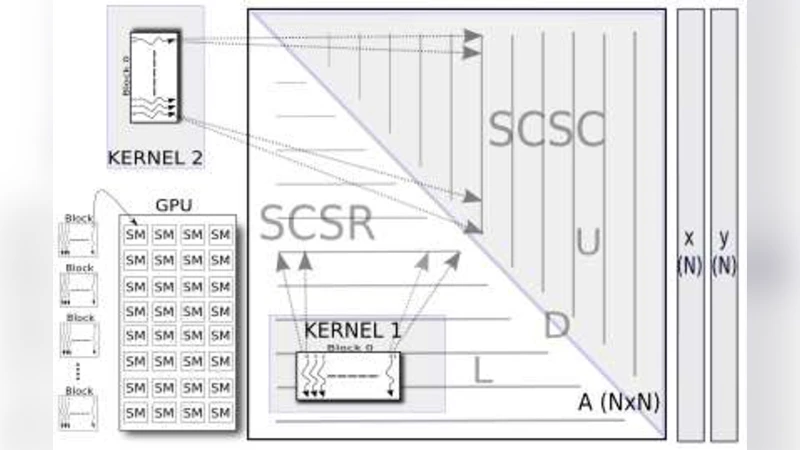
The GPU architecture is described in detail: each streaming multiprocessor (SM) contains 8 scalar cores, 1 683 32‑bit registers, and 16 KB of shared memory, supporting up to 1 024 concurrent threads. The authors explain the CUDA programming model, emphasizing the distinction between host code, device kernels, and the availability of high‑performance libraries such as cuBLAS for dense BLAS operations. Since cuBLAS does not support sparse matrix‑vector multiplication (SpMV), the authors write custom CUDA kernels for this critical operation.
The CG iteration consists of the usual steps: compute α = (rᵀr)/(pᵀAp), update the solution x ← x + αp, update the residual r ← r − αAp, compute β = (rᵀr)/(rᵀr)₍prev₎, and update the search direction p ← r + βp. All scalar products and AXPY updates are performed with cuBLAS calls, while the sparse matrix‑vector product Ap is carried out by the custom SpMV kernels. Three kernel variants are implemented: (1) a straightforward CSR kernel where each thread processes one row, (2) an SCSR kernel that processes the lower‑triangular part L + D, and (3) an SC‑C kernel that processes the upper‑triangular part U. Because the upper‑triangular kernel writes to the same output vector as the lower‑triangular kernel, atomicAdd operations are used to avoid race conditions. This design reduces memory consumption by roughly 50 % when using symmetric storage, but the atomic operations introduce serialization that degrades performance.
Performance is evaluated on two GPU devices: an older Tesla C870 (single‑precision) and a GeForce GTX 280 (double‑precision). The CPU reference implementation runs in 2 392 ms for the full CG solve. On the GTX 280, the double‑precision CG completes in 370 ms, yielding a speed‑up of 6.4×; the single‑precision version on the C870 achieves a 5.8× speed‑up (400 ms). The most time‑consuming operation is SpMV: on the CPU it takes 5.966 ms per multiplication, while on the GTX 280 it drops to 0.005 ms (double) and 0.013 ms (single). The authors also report that reading the matrix from disk takes about 6 ms, a negligible overhead for the overall experiment.
The conclusions highlight two main findings. First, GPU acceleration dramatically reduces the time required for CG‑based finite‑element solves of Maxwell’s equations, making it attractive for industrial electric‑machine simulations. Second, while symmetric storage halves the memory footprint, the current implementation’s reliance on atomic writes to the result vector offsets much of the performance gain. The paper suggests that future work should explore alternative strategies to eliminate atomic contention (e.g., graph coloring, warp‑level reductions) and investigate multi‑GPU scaling and integration with full simulation pipelines. Overall, the study demonstrates the feasibility and benefits of porting sparse linear solvers to modern GPUs, while also identifying concrete avenues for further optimization.
Comments & Academic Discussion
Loading comments...
Leave a Comment