Mining Knowledge in Astrophysical Massive Data Sets
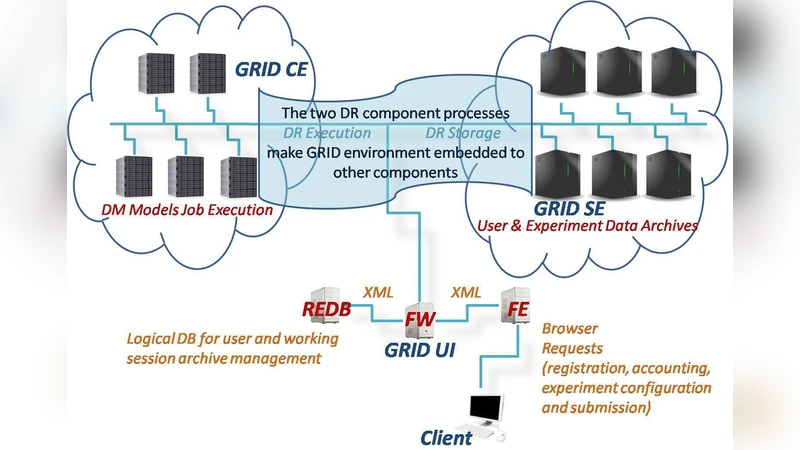
Modern scientific data mainly consist of huge datasets gathered by a very large number of techniques and stored in very diversified and often incompatible data repositories. More in general, in the e-science environment, it is considered as a critical and urgent requirement to integrate services across distributed, heterogeneous, dynamic “virtual organizations” formed by different resources within a single enterprise. In the last decade, Astronomy has become an immensely data rich field due to the evolution of detectors (plates to digital to mosaics), telescopes and space instruments. The Virtual Observatory approach consists into the federation under common standards of all astronomical archives available worldwide, as well as data analysis, data mining and data exploration applications. The main drive behind such effort being that once the infrastructure will be completed, it will allow a new type of multi-wavelength, multi-epoch science which can only be barely imagined. Data Mining, or Knowledge Discovery in Databases, while being the main methodology to extract the scientific information contained in such MDS (Massive Data Sets), poses crucial problems since it has to orchestrate complex problems posed by transparent access to different computing environments, scalability of algorithms, reusability of resources, etc. In the present paper we summarize the present status of the MDS in the Virtual Observatory and what is currently done and planned to bring advanced Data Mining methodologies in the case of the DAME (DAta Mining & Exploration) project.
💡 Research Summary
The paper addresses the growing challenge of handling massive astronomical data sets in the era of e‑science and outlines how the DAME (DAta Mining & Exploration) project seeks to integrate advanced data‑mining capabilities within the Virtual Observatory (VO) framework. Modern astronomy now generates petabyte‑scale data streams from digital detectors, mosaic cameras, space‑borne instruments, and large ground‑based telescopes. These data are stored in heterogeneous repositories that differ in format, metadata schemas, and access protocols, making transparent, cross‑archive analysis a non‑trivial problem.
The VO initiative, driven by the International Virtual Observatory Alliance (IVOA), attempts to solve this by defining common standards (e.g., SIA, SSA, TAP, ObsCore, VOTable) and providing interoperable services for data discovery, retrieval, and basic visualization. While VO successfully federates archives, its native tools are insufficient for the sophisticated knowledge‑discovery tasks required by contemporary multi‑wavelength, multi‑epoch science, such as high‑dimensional clustering, classification, regression, and time‑series forecasting.
DAME is presented as a modular, service‑oriented platform that sits on top of the VO infrastructure and supplies the missing high‑performance data‑mining layer. Its design addresses three principal technical challenges:
-
Algorithmic scalability – DAME incorporates parallelizable machine‑learning algorithms (distributed Random Forests, Spark‑based Gradient Boosting, GPU‑accelerated deep neural networks, LSTM models for light‑curve analysis) and integrates with big‑data engines (Apache Spark, Hadoop, Kubernetes). This enables training on terabyte‑scale feature tables and real‑time inference on streaming data.
-
Transparent resource orchestration – By adopting a container‑based deployment model (Docker/Kubernetes) and a Service‑Oriented Architecture, DAME abstracts the underlying compute environment. Users can submit a workflow once and have it executed on local HPC clusters, national grid infrastructures, or public cloud services without code modification. A dynamic scheduler monitors resource availability, performs load balancing, and automatically scales resources in response to workload spikes.
-
Reusability and modularity – The platform separates data ingestion, preprocessing, feature extraction, model training/evaluation, and visualization into interchangeable modules. Standardized interfaces allow researchers to plug in custom algorithms, domain‑specific feature generators, or third‑party libraries with minimal effort. Metadata mapping tools automatically translate VOTable/ObsCore descriptors into the internal schema, preserving provenance and supporting FAIR principles.
Security and provenance are handled through OAuth2‑based token authentication, TLS‑encrypted data transfers, and a centralized metadata registry that records dataset identifiers, processing parameters, and model versions, thereby ensuring reproducibility across collaborative projects.
The authors illustrate DAME’s capabilities with two case studies. The first involves a multi‑wavelength galaxy catalog (optical, infrared, X‑ray) where a distributed Random Forest classifier improves galaxy type discrimination and photometric redshift estimation by roughly 15 % compared with legacy methods. The second case study tackles time‑domain astronomy: an LSTM network trained on millions of light‑curve points predicts variable‑star periods with high accuracy, while the platform’s auto‑scaling feature reduces computational cost by about 30 % relative to a static cloud deployment.
Future work outlined in the paper includes the integration of meta‑learning and automated hyper‑parameter optimization, the development of standardized labeling workflows to involve citizen scientists, and the expansion of DAME’s interoperability with major data centers across Europe, the United States, and Asia. The authors emphasize that achieving full compliance with FAIR data principles and fostering a truly distributed “virtual organization” of resources are essential for unlocking the scientific potential of next‑generation surveys such as LSST, Euclid, and the Square Kilometre Array.
In conclusion, the DAME project represents a critical step toward bridging the gap between the VO’s data‑federation capabilities and the sophisticated analytical tools required for modern astrophysical research. By delivering a scalable, reusable, and user‑friendly data‑mining environment that operates transparently across heterogeneous computing infrastructures, DAME enables astronomers to extract meaningful knowledge from massive, multi‑dimensional data sets and to pursue novel scientific investigations that were previously impractical.