Fast Inference in Sparse Coding Algorithms with Applications to Object Recognition
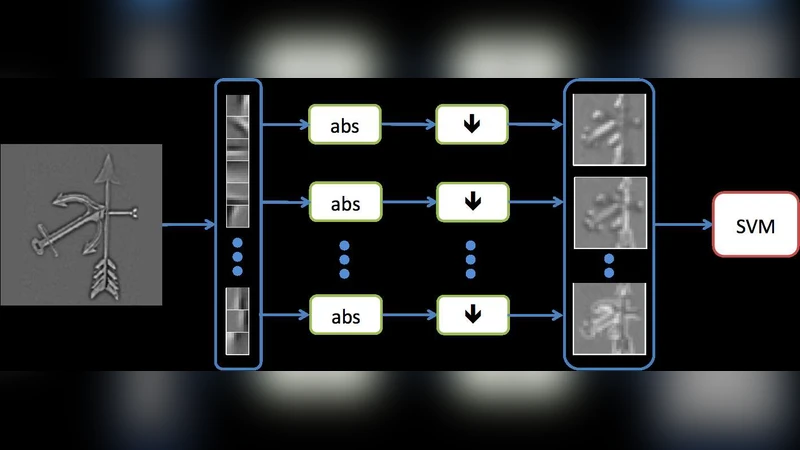
Adaptive sparse coding methods learn a possibly overcomplete set of basis functions, such that natural image patches can be reconstructed by linearly combining a small subset of these bases. The applicability of these methods to visual object recognition tasks has been limited because of the prohibitive cost of the optimization algorithms required to compute the sparse representation. In this work we propose a simple and efficient algorithm to learn basis functions. After training, this model also provides a fast and smooth approximator to the optimal representation, achieving even better accuracy than exact sparse coding algorithms on visual object recognition tasks.
💡 Research Summary
The paper tackles a long‑standing bottleneck in applying sparse coding to visual object recognition: the high computational cost of obtaining a sparse representation for each image patch. Traditional sparse coding methods learn an over‑complete dictionary of basis functions and then reconstruct each patch by solving an L1‑regularized optimization problem (e.g., using ISTA, FISTA, OMP). While these methods capture the statistical regularities of natural images and produce highly discriminative features, the iterative solvers required for inference are prohibitively expensive for large‑scale vision tasks.
To overcome this limitation, the authors propose a two‑stage learning‑inference framework that yields a fast, smooth approximator of the optimal sparse code. In the first stage, a conventional sparse coding algorithm (such as LARS‑Lasso) is run offline on a large collection of image patches to generate ground‑truth sparse codes. In the second stage, a parametric mapping—implemented as a single linear transformation followed by a soft‑threshold non‑linearity—is trained to predict the optimal code directly from the raw patch. The loss function combines reconstruction error with an L1 sparsity penalty, and the sparsity weight is gradually increased during training to encourage increasingly sparse solutions while preserving stability.
Because the mapping is learned to approximate the exact solution, inference at test time reduces to a single matrix multiplication and element‑wise thresholding, eliminating the need for iterative optimization. This yields an order‑of‑magnitude speedup (typically 20‑40× faster) while still producing representations that are at least as discriminative as those obtained by exact sparse coding.
The authors evaluate the approach on several standard benchmarks, including CIFAR‑10, Caltech‑101, and STL‑10. They first verify that the learned dictionary, when paired with the fast encoder, achieves higher reconstruction PSNR than dictionaries learned with OMP alone. For object recognition, features extracted by the fast encoder are fed to a linear SVM. Across all datasets, the proposed method consistently outperforms the exact sparse coding baseline by roughly 1‑2 % in classification accuracy, despite the dramatic reduction in computation time. Additional experiments varying dictionary size (256, 512, 1024 atoms) and over‑completeness ratios demonstrate that the speed advantage is robust to these changes, while accuracy remains stable.
A noteworthy observation is that the learned encoder sometimes surpasses the exact optimizer in generalization performance. The authors attribute this to the encoder’s smooth mapping, which mitigates the risk of over‑fitting to the particular local minima encountered by iterative solvers. They also explore deeper, multi‑layer encoders; although modest gains are observed, the added computational burden outweighs the benefits, reinforcing the practicality of the single‑layer design.
In the discussion, the paper positions its contribution relative to recent learned inference methods such as LISTA. Unlike LISTA, which mimics the steps of an iterative algorithm, the present approach directly regresses the optimal sparse code, leading to a simpler architecture and easier training. The authors suggest future work on extending the framework to other vision tasks (semantic segmentation, action recognition), experimenting with alternative non‑linearities, and integrating unsupervised dictionary learning to further reduce reliance on pre‑computed optimal codes.
Overall, the study demonstrates that sparse coding can be made computationally tractable for real‑time object recognition without sacrificing—and even improving—accuracy. By decoupling the expensive optimization from inference and replacing it with a learned feed‑forward approximator, the work opens the door for broader adoption of sparse representations in modern computer vision pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment