Parallel Sorted Neighborhood Blocking with MapReduce
Cloud infrastructures enable the efficient parallel execution of data-intensive tasks such as entity resolution on large datasets. We investigate challenges and possible solutions of using the MapReduce programming model for parallel entity resolution. In particular, we propose and evaluate two MapReduce-based implementations for Sorted Neighborhood blocking that either use multiple MapReduce jobs or apply a tailored data replication.
💡 Research Summary
The paper addresses the scalability challenge of entity resolution (ER) on massive datasets by focusing on the blocking phase, specifically the Sorted Neighborhood (SN) method, and adapting it to the MapReduce programming model. SN reduces the quadratic comparison cost by sorting records on a blocking key and only comparing records that fall within a sliding window of fixed size. While effective on modest data volumes, traditional SN implementations run on a single machine and become a bottleneck when the number of records reaches millions or more. To overcome this limitation, the authors propose two distinct MapReduce‑based designs that enable parallel execution of the blocking step on cloud infrastructures.
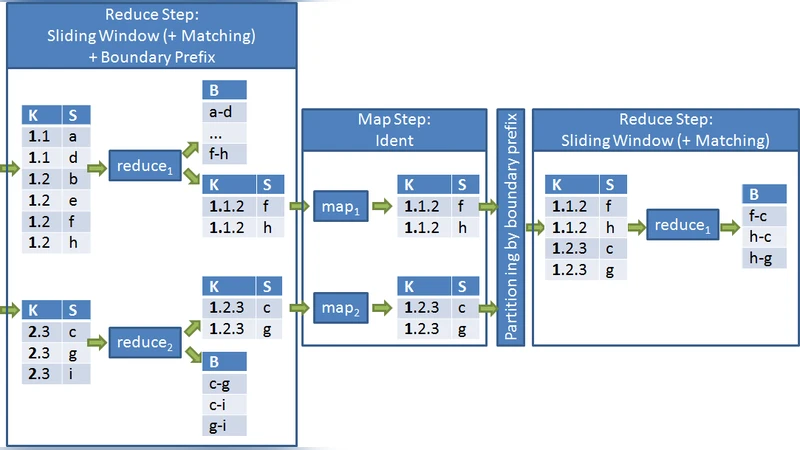
The first design, called the “multi‑job approach,” decomposes the SN workflow into two consecutive MapReduce jobs. In the first job, the mapper emits each record keyed by its blocking value; the reducer receives a sorted stream of records for each key, constructs the sliding windows, and emits window identifiers together with the records that lie on the window boundaries. A second MapReduce job then takes these boundary records as input, re‑partitions them, and performs the actual pairwise comparisons inside each window. This separation isolates the memory‑intensive window construction from the comparison phase, allowing each reducer to operate on a bounded subset of data. The trade‑off is the additional shuffle between jobs, which increases network traffic and job‑scheduling complexity, especially when the number of reducers (partitions) is large.
The second design, termed the “custom replication approach,” collapses the entire SN pipeline into a single MapReduce job by deliberately replicating records across reducers. Each mapper not only emits the record under its own blocking key but also under keys that fall within the window radius on either side. Consequently, a record may be sent to multiple reducers, guaranteeing that every possible window pair is co‑located for comparison. The reducer then receives all records that belong to its assigned window and directly computes the candidate pairs. This method eliminates the inter‑job shuffle, dramatically reducing round‑trip latency, but at the cost of increased storage and memory consumption due to the replicated records. The replication factor is a function of the window size and the number of partitions; the authors provide a heuristic to keep this factor low while preserving completeness.
Experimental evaluation was carried out on an Amazon EC2 Hadoop cluster with configurations ranging from 4 to 32 nodes. Datasets of 100 K to 5 M records were generated, and the authors varied three key parameters: window size (5–25), number of reducers (10–100), and cluster size. Performance metrics included total execution time, amount of data shuffled, peak memory usage per reducer, and blocking quality measured by recall and precision. Results show that the multi‑job approach scales well with a large number of reducers because each reducer handles a smaller in‑memory window, but the extra shuffle introduces noticeable overhead when the reducer count exceeds 50. Conversely, the custom‑replication approach achieves the lowest execution times for moderate cluster sizes (≤16 nodes) and window sizes up to 15, with negligible impact on recall/precision because the replication guarantees full coverage of all candidate pairs. Both approaches outperform a baseline single‑machine SN implementation by factors of 3× to 8×, with the gap widening as the dataset grows beyond one million records.
Beyond raw performance, the authors distill several design insights for practitioners. First, leveraging the MapReduce key‑value abstraction for blocking‑key partitioning eliminates the need for an explicit global sort; the framework’s shuffle already provides a sorted input to each reducer. Second, handling window boundaries is the primary source of data duplication; careful selection between explicit boundary buffers (multi‑job) and key replication (single‑job) should be guided by the available network bandwidth versus memory capacity. Third, the number of MapReduce stages directly influences latency; a single stage reduces coordination overhead but may increase memory pressure due to replication. Finally, the techniques are not Hadoop‑specific; they can be translated to Spark, Flink, or other data‑flow engines that support keyed shuffles and user‑defined partitioning.
In conclusion, the paper demonstrates that the Sorted Neighborhood blocking technique can be effectively parallelized using MapReduce, offering two viable pathways: a multi‑stage pipeline that minimizes memory usage at the expense of extra shuffles, and a single‑stage replicated pipeline that minimizes latency but requires more storage. Both solutions achieve substantial speed‑ups while preserving blocking quality, thereby enabling large‑scale entity resolution workloads to run efficiently on modern cloud platforms. Future work suggested includes adaptive partitioning, dynamic window sizing, and integration with machine‑learning‑driven similarity functions to further enhance scalability and accuracy.
Comments & Academic Discussion
Loading comments...
Leave a Comment