An Alternative Prior Process for Nonparametric Bayesian Clustering
Prior distributions play a crucial role in Bayesian approaches to clustering. Two commonly-used prior distributions are the Dirichlet and Pitman-Yor processes. In this paper, we investigate the predictive probabilities that underlie these processes, …
Authors: Hanna M. Wallach, Shane T. Jensen, Lee Dicker
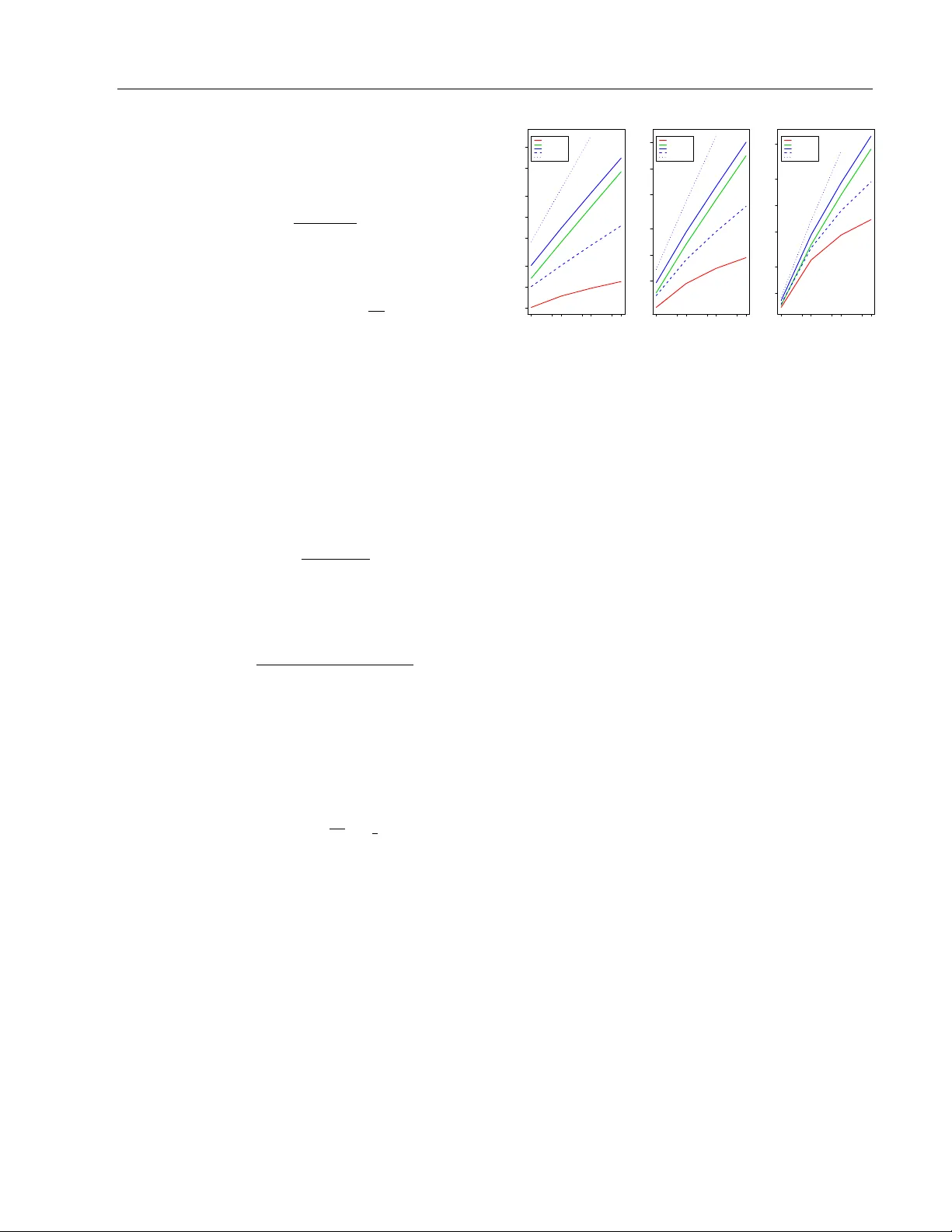
An Alternativ e Prior Pro cess for Nonparametric Ba y esian Clustering Hanna M. W allac h Shane T. Jensen Departmen t of Computer Science Univ ersity of Massach usetts Amherst Departmen t of Statistics The Wharton Sc ho ol, Universit y of Pennsylv ania Lee Dic ker Katherine A. Heller Departmen t of Biostatistics Harv ard School of Public Health Engineering Department Univ ersity of Cambridge Abstract Prior distributions pla y a crucial role in Ba yesian approac hes to clustering. Tw o commonly-used prior distributions are the Diric hlet and Pitman-Y or pro cesses. In this pap er, w e in vestigate the predictive prob- abilities that underlie these pro cesses, and the implicit “ric h-get-richer” characteristic of the resulting partitions. W e explore an al- ternativ e prior for nonparametric Ba y esian clustering—the uniform process—for appli- cations where the “rich-get-ric her” property is undesirable. W e also explore the cost of this pro cess: partitions are no longer ex- c hangeable with resp ect to the ordering of v ariables. W e presen t new asymptotic and sim ulation-based results for the clustering c haracteristics of the uniform pro cess and compare these with kno wn results for the Diric hlet and Pitman-Y or pro cesses. W e compare p erformance on a real do cumen t clustering task, demonstrating the practical adv an tage of the uniform pro cess despite its lac k of exchangeabilit y ov er orderings. 1 In tro duction Nonparametric Bay esian models pro vide a p o werful and p opular approac h to many difficult statistical problems, including document clustering (Zhang et al. , 2005), topic mo deling (T eh et al. , 2006b), and clus- tering motifs in DNA sequences (Jensen and Liu, App earing in Proceedings of the 13 th In ternational Con- ference on Artificial Intelligence and Statistics (AIST A TS) 2010, Chia Laguna Resort, Sardinia, Italy . V olume 9 of JMLR: W&CP 9. Copyrigh t 2010 b y the authors. 2008). The key assumption underlying nonparamet- ric Bay esian mo dels is the existence of a set of random v ariables dra wn from some unkno wn probabilit y distri- bution. This unknown probabilit y distribution is itself dra wn from some prior distribution. The Dirichlet pro- cess is one suc h prior for unknown probability distri- butions that has b ecome ubiquitous in Ba yesian non- parametric modeling, as review ed by Muller and Quin- tana (2004). More recently , Pitman and Y or (1997) in tro duced the Pitman-Y or pro cess, a tw o-parameter generalization of the Dirichlet pro cess. These pro- cesses can also b e nested within a hierarc hical struc- ture (T eh et al. , 2006a; T eh, 2006). A key prop ert y of an y mo del based on Dirichlet or Pitman-Y or pro cesses is that the p osterior distribution provides a partition of the data in to c lusters, without requiring that the n umber of clusters b e pre-sp ecified in adv ance. How- ev er, previous w ork on nonparametric Ba yesian clus- tering has paid little attention to the implicit a priori “ric h-get-richer” prop ert y imposed b y both the Dirich- let and Pitman-Y or process. As we explore in sec- tion 2, this prop erty is a fundamen tal c haracteristic of partitions generated b y these pro cesses, and leads to partitions consisting of a small num b er of large clus- ters, with “rich-get-ric her” usage. Although “rich-get- ric her” cluster usage is appropriate for some clustering applications, there are others for which it is undesir- able. As pointed out by W elling (2006), there exists a need for alternativ e priors in clustering mo dels. In this pap er, we explore one suc h alternativ e prior— the uniform pr o c ess —which exhibits a very different set of clustering characteristics to either the Dirich- let pro cess or the Pitman-Y or pro cess. The uniform pro cess w as originally introduced b y Qin et al. (2003) (page 438) as an ad ho c prior for DNA motif clustering. Ho wev er, it has received little attention in the subse- quen t statistics and mac hine learning literature and its clustering c haracteristics hav e remained largely unex- An Alternative Prior Pro cess for Nonparametric Bay esian Clustering plored. W e therefore compare the uniform pro cess to the Dirichlet and Pitman-Y or pro cesses in terms of asymptotic characteristics (section 3) as well as c har- acteristics for sample sizes typical of those found in real clustering applications (section 4). One fundamen tal difference betw een the uniform pro cess and the Diric h- let and Pitman-Y or pro cesses is the uniform pro cess’s lac k of exchangeabilit y ov er cluster assignments—the probabilit y P ( c ) of a particular set of cluster assign- men ts c is not in v ariant under p erm utations of those assignmen ts. Previous work on the uniform pro cess has not ac knowledged this issue with resp ect to either inference or probabilit y calculations. W e demonstrate that this lack of exchangeabilit y is not a significant problem for applications where a more balanced prior assumption ab out cluster sizes is desired. W e present a new Gibbs sampling algorithm for the uniform pro- cess that is correct for a fixed ordering of the cluster assignmen ts, and sho w that while P ( c ) is not in v arian t to p erm uted orderings, it can b e highly robust. W e also consider the uniform pro cess in the context of a real text pro cessing application: unsup ervised clus- tering of a set of do cuments into natural, thematic groupings. An extensive and diverse arra y of mo d- els and pro cedures ha ve been dev elop ed for this task, as reviewed b y Andrews and F ox (2007). These ap- proac hes include nonparametric Bay esian clustering using the Dirichlet process (Zhang et al. , 2005) and the hierarchical Diric hlet pro cess (T eh et al. , 2006a). Suc h nonparametric mo dels are p opular for do cument clustering since the n umber of clusters is rarely known a priori , and these mo dels allow the n umber of clus- ters to b e inferred along with the assignmen ts of doc- umen ts to clusters. How ever, as w e illustrate b elo w, the Diric hlet pro cess still places prior assumptions on the clustering structure: partitions will t ypically b e dominated by a few v ery large clusters, with ov erall “ric h-get-richer” cluster usage. F or man y applications, there is no a priori reason to exp ect that this kind of partition is preferable to other kinds of partitions, and in these cases the uniform pro cess can b e a better rep- resen tation of prior b eliefs than the Diric hlet pro cess. W e demonstrate that the uniform pro cess leads to su- p erior do cumen t clustering p erformance (quantified by the probability of unseen held-out do cumen ts under the mo del) o ver the Dirichlet pro cess using a collec- tion of carb on nanotec hnology paten ts (section 6). 2 Predictiv e Probabilities for Clustering Priors Clustering inv olves partitioning random v ariables X = ( X 1 , . . . , X N ) into clusters. This pro cedure is often p erformed using a mixture model, which assumes that eac h v ariable was generated b y one of K mixture com- p onen ts characterized by parameters Φ = { φ k } K k =1 : P ( X n | Φ) = K X k =1 P ( c n = k ) P ( X n | φ k , c n = k ) , (1) where c n is an indicator v ariable such that c n = k if and only if data p oin t X n w as generated by comp onent k with parameters φ k . Clustering can then b e charac- terized as iden tifying the set of parameters responsible for generating eac h observ ation. The observ ations as- so ciated with parameters φ k are those X n for whic h c n = k . T ogether, these observ ations form cluster k . Ba yesian mixture mo dels assume that the parameters Φ come from some prior distribution P (Φ). Nonpara- metric Bay esian mixture mo dels further assume that the probabilit y that c n = k is w ell-defined in the limit as K → ∞ . This allows for more flexible mixture mo deling, while av oiding costly mo del comparisons in order to determine the “righ t” n umber of clusters or comp onen ts K . F rom a generative p erspective, in non- parametric Ba yesian mixture mo deling, each observ a- tion is assumed to hav e been generated by first select- ing a set of comp onen t parameters φ k from the prior and then generating the observ ation itself from the corresp onding component. Clusters are therefore con- structed sequentially . The comp onen t parameters re- sp onsible for generating a new observ ation are selected using the pr e dictive pr ob abilities —the conditional dis- tribution ov er comp onen t parameters implied by a par- ticular choice of priors ov er Φ and c n . W e next describ e three priors—the Diric hlet, Pitman-Y or, and uniform pro cesses—using their predictive probabilities. F or no- tational conv enience we define ψ n to b e the component parameters for the mixture comp onen t responsible for observ ation X n , such that ψ n = φ k when c n = k . 2.1 Diric hlet Pro cess The Diric hlet process prior has tw o parameters: a c on- c entr ation p ar ameter θ , which controls the formation of new clusters, and a b ase distribution G 0 . Under a Diric hlet pro cess prior, the conditional probabilit y of the mixture comp onen t parameters ψ N +1 asso ciated with a new observ ation X N +1 giv en the comp onen t parameters ψ 1 , . . . , ψ N asso ciated with previous obser- v ations X 1 , . . . , X N is a mixture of p oin t masses at the lo cations of ψ 1 , . . . , ψ N and the base distribution G 0 . V ariables X n and X m are said to to belong to the same cluster if and only if ψ n = ψ m . 1 This predictive prob- abilit y formulation therefore sequentially constructs a partition, since observ ation X N +1 b elongs to an exist- ing cluster if ψ N +1 = ψ n for some n ≤ N or a new cluster consisting only of X N +1 if ψ N +1 is drawn di- rectly from G 0 . If φ 1 , . . . , φ K are the K distinct v alues 1 Assuming a contin uous G 0 . H.M. W allach, S.T. Jensen, L. Dic ker, and K.A. Heller in ψ 1 , . . . , ψ N and N 1 , . . . , N K are the corresp onding cluster sizes ( i.e. , N k = P N n =1 I ( ψ n = φ k ), then P ( ψ N +1 | ψ 1 , . . . , ψ N , θ , G 0 ) = ( N k N + θ ψ N +1 = φ k ∈ { φ 1 , . . . , φ K } θ N + θ ψ N +1 ∼ G 0 . (2) New observ ation X N +1 joins existing cluster k with probabilit y prop ortional to N k (the num b er of previous observ ations in that cluster) and joins a new cluster, consisting of X N +1 only , with probabilit y prop ortional to θ . This predictive probability is eviden t in the Chi- nese r estaur ant pr o c ess metaphor (Aldous, 1985). The most ob vious characteristic of the Diric hlet pro- cess predictiv e probability (giv en by (2)) is the “ric h- get-ric her” prop ert y: the probabilit y of joining an ex- isting cluster is prop ortional to the size of that clus- ter. New observ ations are therefore more likely to join already-large clusters. The “rich-get-ric her” charac- teristic is also evident in the stick-br e aking construc- tion of the Dirichlet process (Seth uraman, 1994; Ish- w aran and James, 2001), where eac h unique p oin t mass is assigned a random weigh t. These weigh ts are gener- ated as a product of Beta random v ariables, whic h can b e visualized as breaks of a unit-length stic k. Earlier breaks of the stick will tend to lead to larger weigh ts, whic h again gives rise to the “rich-get-ric her” prop ert y . 2.2 Pitman-Y or Pro cess The Pitman-Y or process (Pitman and Y or, 1997) has three parameters: a concen tration parameter θ , a base distribution G 0 , and a disc ount p ar ameter 0 ≤ α < 1. T ogether, θ and α con trol the formation of new clusters. The Pitman-Y or predictiv e probabilit y is P ( ψ N +1 | ψ 1 , . . . , ψ N , θ , α, G 0 ) = ( N k − α N + θ ψ N +1 = φ k ∈ { φ 1 , . . . , φ K } θ + K α N + θ ψ N +1 ∼ G 0 . (3) The Pitman-Y or pro cess also exhibits the “rich-get- ric her” prop ert y . Ho wev er, the discoun t parameter α serv es to reduce the probabilit y of adding a new obser- v ation to an existing cluster. This prior is particularly w ell-suited to natural language processing applications (T eh, 2006; W allac h et al. , 2008) because it yields p o w er-law b eha vior (cluster usage) when 0 < α < 1. 2.3 Uniform Pro cess Predictiv e probabilities (2) and (3) result in partitions that are dominated b y a few large clusters, since new observ ations are more lik ely to b e assigned to larger clusters. F or many tasks, how ever, a prior ov er parti- tions that induces more uniformly-sized clusters is de- sirable. The uniform pro cess (Qin et al. , 2003; Jensen and Liu, 2008) is one such prior. The predictiv e prob- abilit y for the uniform pro cess is giv en b y P ( ψ N +1 | ψ 1 , . . . , ψ N , θ , G 0 ) = ( 1 K + θ ψ N +1 = φ k ∈ { φ 1 , . . . , φ K } θ K + θ ψ N +1 ∼ G 0 . (4) The probability that new observ ation X N +1 joins one of the existing K clusters is uniform o ver these clus- ters, and is unrelated to the cluster sizes. Although the uniform pro cess has b een used previously for clus- tering DNA motifs (Qin et al. , 2003; Jensen and Liu, 2008), its usage has otherwise b een extremely limited in the statistics and mac hine learning literature and its theoretical prop erties ha ve th us-far not b een explored. Constructing prior pro cesses using predictiv e proba- bilities can imply that the underlying prior results in nonexc hangeability . If c denotes a partition or set of cluster assignmen ts for observ ations X , then the par- tition is exchangeable if the calculation of the full prior densit y of the partition P ( c ) via the predictiv e prob- abilities is unaffected by the ordering of the cluster assignmen ts. As discussed by Pitman (1996) and Pit- man (2002), most sequen tial pro cesses will fail to pro- duce a partition that is exchangeable. The Dirichlet pro cess and Pitman-Y or pro cess predictive probabili- ties ((2) and (3)) both lead to exc hangeable partitions. In fact, their densities are special cases of “exc hange- able partition probability functions” given by Ish waran and James (2003). Green and Ric hardson (2001) and W elling (2006) discuss the relaxation of exchangeabil- it y in order to consider alternative prior pro cesses. The uniform pro cess do es not ensure exc hangeability: the prior probability P ( c ) of a particular set of cluster assignmen ts c is not inv arian t under p erm utation of those cluster assignmen ts. How ever, in section 5, we demonstrate that the nonexchangeabilit y implied b y the uniform pro cess is not a significant problem for real data by showing that P ( c ) is robust to p ermutations of the observ ations and hence cluster assignmen ts. 3 Asymptotic Behavior In this section, w e compare the three priors implied b y predictiv e probabilities (2), (3) and (4) in terms of the asymptotic b eha vior of t wo partition characteris- tics: the num b er of clusters K N and the distribution of cluster sizes H N = ( H 1 ,N , H 2 ,N , . . . , H N ,N ) where H M ,N is the num b er of clusters of size M in a partition of N observ ations. W e b egin b y reviewing previous re- sults for the Dirichlet and Pitman-Y or pro cesses, and then present new results for the uniform process. An Alternative Prior Pro cess for Nonparametric Bay esian Clustering 3.1 Diric hlet Pro cess As the n umber of observ ations N → ∞ , the exp ected n umber of unique clusters K N in a partition is E ( K N | DP) = N X n =1 θ n − 1 + θ ' θ log N . (5) The exp ected num b er of clusters of size M is lim N →∞ E ( H M ,N | DP) = θ M . (6) This well-kno wn result (Arratia et al. , 2003) implies that as N → ∞ , the exp ected n umber of clusters of size M is inv ersely prop ortional to M regardless of the v alue of θ . In other words, in exp ectation, there will b e a small n umber of large clusters and vic e versa . 3.2 Pitman-Y or Pro cess Pitman (2002) sho wed that as N → ∞ , the expected n umber of unique clusters K N in a partition is E ( K N | PY) ≈ Γ(1 + θ ) α Γ( α + θ ) N α . (7) Pitman’s result can also be used to deriv e the exp ected n umber of clusters of size M in a partition: E ( H M ,N | PY) ≈ Γ(1 + θ ) Q M − 1 m =1 ( m − α ) Γ( α + θ ) M ! N α . (8) 3.3 Uniform Pro cess Previous literature on the uniform pro cess do es not con tain any asymptotic results. W e therefore present the following nov el result for the exp ected n umber of unique clusters K N in a partition as N → ∞ : E ( K N | UP) ≈ √ 2 θ · N 1 2 . (9) A complete proof is given in the supplementary ma- terials. In section 4, we also present simulation-based results that suggest the following conjecture for the exp ected n umber of clusters of size M in a partition: E ( H M ,N | UP) ≈ θ . (10) This result corresp onds well to the intuition underlying the uniform process: observ ations are a priori equally lik ely to join an y existing cluster, regardless of size. 3.4 Summary of Asymptotic Results The distribution of cluster sizes for the uniform pro cess is dramatically different to that of either the Pitman- Y or or Dirichlet pro cess, as evidenced by the results 1e+02 5e+02 5e+03 5e+04 5 10 20 50 100 200 500 1000 θ θ = = 1 N = Number of Observations Expected Number of Clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● DP UN PY ( α α = = 0.5) PY ( α α = = 0.25) PY ( α α = = 0.75) 1e+02 5e+02 5e+03 5e+04 50 100 200 500 1000 2000 θ θ = = 10 N = Number of Observations Expected Number of Clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● DP UN PY ( α α = = 0.5) PY ( α α = = 0.25) PY ( α α = = 0.75) 1e+02 5e+02 5e+03 5e+04 100 200 500 1000 2000 5000 θ θ = = 100 N = Number of Observations Expected Number of Clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● DP UN PY ( α α = = 0.5) PY ( α α = = 0.25) PY ( α α = = 0.75) Figure 1: Exp ected num ber of clusters ˆ K N v ersus sam- ple size N for different θ . Axes are on a log scale. ab o v e, as w ell as the sim ulation-based results in sec- tion 4. The uniform pro cess exhibits a uniform distri- bution of cluster sizes. Although the Pitman-Y or pro- cess can b e made to b eha v e similarly to the uniform pro cess in terms of the expected num b er of clusters (b y v arying α , as describ ed below), it cannot b e con- figured to exhibit a uniform distribution ov er cluster sizes, which is a unique asp ect of the uniform process. Under the Dirichlet process, the exp ected num b er of clusters grows logarithmically with the n umber of ob- serv ations N . In contrast, under the uniform pro cess, the exp ected n um b er of clusters grows with the square ro ot of the num b er of observ ations N . The Pitman- Y or pro cess implies that the exp ected n umber of clus- ters grows at a rate of N α . In other words, the Pitman- Y or pro cess can lead to a slow er or faster gro wth rate than the uniform pro cess, depending on the v alue of the discount parameter α . F or α = 0 . 5, the exp ected n umber of clusters grows at the same rate for b oth the Pitman-Y or process and the uniform pro cess. 4 Sim ulation Comparisons: Finite N The asymptotic results presented in the previous sec- tion are not necessarily applicable to real data where the finite n um b er of observ ations N constrains the dis- tribution of cluster sizes, P M M · H M ,N = N . In this section, we appraise the finite sample consequences for the Diric hlet, Pitman-Y or, and uniform pro cesses via a simulation study . F or eac h of the three processes, w e simulated 1000 indep endent partitions for v arious v alues of sample size N and concen tration parameter θ , and calculated the num b er of clusters K N and dis- tribution of cluster sizes H N for eac h of the partitions. 4.1 Num b er of Clusters K N In figure 1, we examine the relationship b etw een the n umber of observ ations N and the av erage n umber of H.M. W allach, S.T. Jensen, L. Dic ker, and K.A. Heller ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 5 10 20 50 100 200 500 1e−03 1e−01 1e+01 Dirichlet Process: N=1000 cluster size mean number of clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 5 10 50 500 5000 1e−03 1e−01 1e+01 Dirichlet Process: N=10000 cluster size mean number of clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 10 100 1000 10000 1e−03 1e−01 1e+01 Dirichlet Process: N=100000 cluster size mean number of clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 5 10 20 50 100 200 500 1e−03 1e−01 1e+01 Pitman−Y or ( α α = = 0.5) : N=1000 cluster size mean number of clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 5 10 50 500 5000 1e−03 1e+01 Pitman−Y or ( α α = = 0.5) : N=10000 cluster size mean number of clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 10 100 1000 10000 1e−03 1e+01 Pitman−Y or ( α α = = 0.5) : N=100000 cluster size mean number of clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 5 10 20 1e−03 1e−01 1e+01 Uniform: N=1000 cluster size mean number of clusters ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 5 10 20 50 1e−03 1e−01 1e+01 Uniform: N=10000 cluster size mean number of clusters ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 5 10 20 50 100 200 1e−03 1e−01 1e+01 Uniform: N=100000 cluster size mean number of clusters Figure 2: Cluster sizes H M ,N as a function of M for different v alues of N for the Dirichlet, Pitman-Y or, and uniform processes. Data are plotted on a log-log scale and the red lines indicate the asymptotic relationships. Eac h p oin t is the av erage num b er of clusters (across 1000 simulated partitions) of a particular cluster size. clusters ˆ K N (a veraged ov er the 1000 sim ulated parti- tions). F or α = 0 . 5, the Pitman-Y or pro cess exhibits the same rate of growth of ˆ K N as the uniform pro cess, confirming the equalit y suggested b y (7) and (9) when α = 0 . 5. As p ostulated in section 3.2, the Pitman-Y or pro cess can exhibit either slo wer ( e.g. , α = 0 . 25) or faster ( e.g. , α = 0 . 75) rates of gro wth of ˆ K N than the uniform process. The rate of gro wth of ˆ K N for the Diric hlet pro cess is the slo west, as suggested by (5). 4.2 Distribution of Cluster Sizes In this section, we examine the exp ected distribution of cluster sizes under each pro cess. F or brevit y , w e fo cus only on concen tration parameter θ = 10, though the same trends are observ ed for other v alues of θ . Figure 2 is a plot of ˆ H M ,N (the av erage num be r of clusters of size M ) as a function of M . F or each process, ˆ H M ,N w as calculated as the av erage ov er the 1000 simulated indep enden t partitions of H M ,N under that process. The red lines indicate the asymptotic relationships, i.e. , (6) for the Dirichlet process, (8) for the Pitman- Y or process, and (10) for the uniform pro cess. The results in figure 2 demonstrate that the simulated distribution of cluster sizes for the uniform pro cess is quite different to the simulated distributions of clusters sizes for either the Dirichlet or Pitman-Y or processes. It is also in teresting to observ e the div ergence from the asymptotic relationships due to the finite sample sizes, esp ecially in the case of small N ( e.g. , N = 1000). 5 Exc hangeabilit y As men tioned in section 2, the uniform pro cess does not lead to exc hangeable partitions. Although the exc hangeability of the Diric hlet and Pitman-Y or pro- cesses is desirable, these clustering models also exhibit the “ric h-get-richer” property . Applied researchers are routinely forced to mak e assumptions when mo deling real data. Even though the use of exchangeable priors can provide man y practical adv an tages for clustering tasks, exchangeabilit y itself is one particular mo del- ing assumption, and there are situations in whic h the “ric h-get-richer” property is disadv an tageous. In real- it y , many data generating pro cesses are not exchange- able, e.g. , news stories are published at different times and therefore ha ve an associated temp oral ordering. If one is willing to make an exchangeabilit y assumption, then the Dirichlet pro cess prior is a natural choice. Ho wev er, it comes with additional assumptions about the size distribution of clusters. These assumptions will be reasonable in certain situations, but less rea- sonable in others. It should not b e necessary to restrict applied researc hers to exc hangeable models, which can imp ose other undesired assumptions, when alterna- tiv es do exist. The uniform pro cess sacrifices the ex- c hangeability assumption in order to mak e a more bal- anced prior assumption ab out cluster sizes. In this section, w e explore the lack of exc hangeabil- it y of the uniform pro cess b y first examining, for real data, the extent to which P ( c ) is affected by p erm ut- ing the observ ations. F or an y particular ordering of observ ations X = ( X 1 , . . . , X N ), the join t probability of the corresp onding cluster assignments c is P ( c | ordering 1 , . . . , N ) = N Y n =1 P ( c n | c
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment