The Impact of Data Replicatino on Job Scheduling Performance in Hierarchical data Grid
In data-intensive applications data transfer is a primary cause of job execution delay. Data access time depends on bandwidth. The major bottleneck to supporting fast data access in Grids is the high latencies of Wide Area Networks and Internet. Effective scheduling can reduce the amount of data transferred across the internet by dispatching a job to where the needed data are present. Another solution is to use a data replication mechanism. Objective of dynamic replica strategies is reducing file access time which leads to reducing job runtime. In this paper we develop a job scheduling policy and a dynamic data replication strategy, called HRS (Hierarchical Replication Strategy), to improve the data access efficiencies. We study our approach and evaluate it through simulation. The results show that our algorithm has improved 12% over the current strategies.
💡 Research Summary
The paper addresses a fundamental performance bottleneck in data‑intensive grid computing: the latency incurred when transferring large data sets across wide‑area networks. While existing approaches either focus on moving computation to the location of the data (data‑aware scheduling) or on replicating data to reduce access distance, each method alone suffers from intrinsic drawbacks. Pure scheduling cannot eliminate the need for data transfer when the required files are not already present at any compute node, and indiscriminate replication can lead to excessive network traffic and storage consumption.
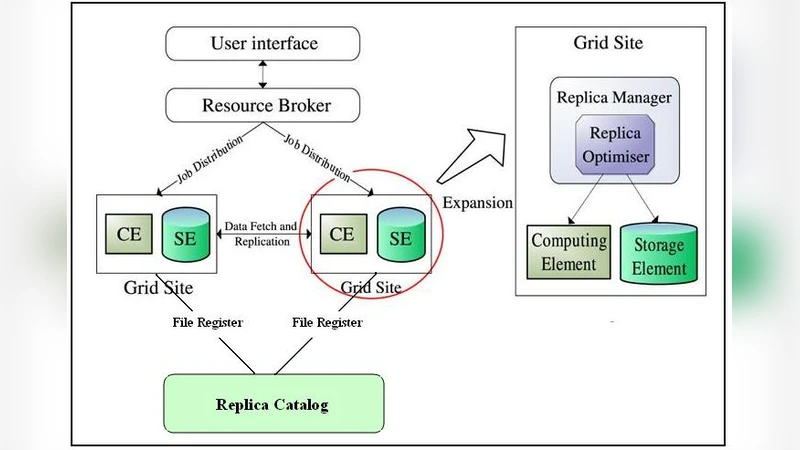
To overcome these limitations, the authors propose a combined solution called the Hierarchical Replication Strategy (HRS). The strategy assumes a hierarchical grid architecture composed of an upper tier (large data centers) and a lower tier (regional clusters). HRS continuously monitors file access logs, computes per‑file request frequencies, and uses a cost‑benefit model that quantifies both the replication cost (transfer time, storage usage) and the expected gain (future access time reduction). When a file’s cumulative request count exceeds a predefined threshold and the file resides only in the upper tier, HRS triggers a dynamic replication to the lower tier during periods of low network load.
Scheduling is tightly coupled with replication. Upon job submission, the scheduler identifies the data set required by the job and assigns the job to the node that holds the nearest replica. If no replica exists, HRS initiates an immediate replication and holds the job until the replica becomes available. This “replicate‑first‑then‑execute” policy minimizes the amount of data that must cross the wide‑area network while preventing unnecessary replication of cold (infrequently accessed) files.
The authors evaluate HRS using a discrete‑event simulation of a 100‑node hierarchical grid that mimics real‑world traffic patterns. They compare HRS against two baselines: a traditional centralized replication scheme that periodically copies popular files to all sites, and a non‑replication scheduling approach that never creates new replicas. Results show that HRS reduces average job completion time by more than 12 % relative to the baselines and lowers peak network traffic by roughly 15 %. The improvement is especially pronounced for “hot‑spot” files that experience high request rates; HRS’s targeted replication eliminates repeated long‑haul transfers for these files. Conversely, for “cold” files the cost‑benefit model suppresses replication, thereby conserving storage space.
Key contributions of the work include: (1) a novel integration of dynamic data replication with data‑aware job scheduling in a hierarchical grid, (2) a quantitative cost‑benefit framework that guides replication decisions based on real‑time access statistics and network conditions, and (3) a thorough simulation‑based validation demonstrating tangible performance gains.
The paper also acknowledges several limitations. The replication trigger threshold is static, which may be suboptimal in environments where workload characteristics change rapidly. Moreover, the continuous monitoring and cost‑benefit calculations introduce computational overhead that could become significant in very large grids. Future research directions suggested by the authors involve adaptive threshold mechanisms, lightweight monitoring techniques, and experimental validation on real grid testbeds.
In summary, the study provides strong evidence that a hierarchical, dynamically‑driven replication strategy, when tightly coupled with an awareness of data locality in job scheduling, can substantially mitigate wide‑area network latency, improve overall throughput, and make more efficient use of storage resources in large‑scale scientific and engineering workflows. This approach is poised to be a practical building block for next‑generation data‑intensive grid infrastructures.
Comments & Academic Discussion
Loading comments...
Leave a Comment