Probabilistic Models over Ordered Partitions with Application in Learning to Rank
This paper addresses the general problem of modelling and learning rank data with ties. We propose a probabilistic generative model, that models the process as permutations over partitions. This resul
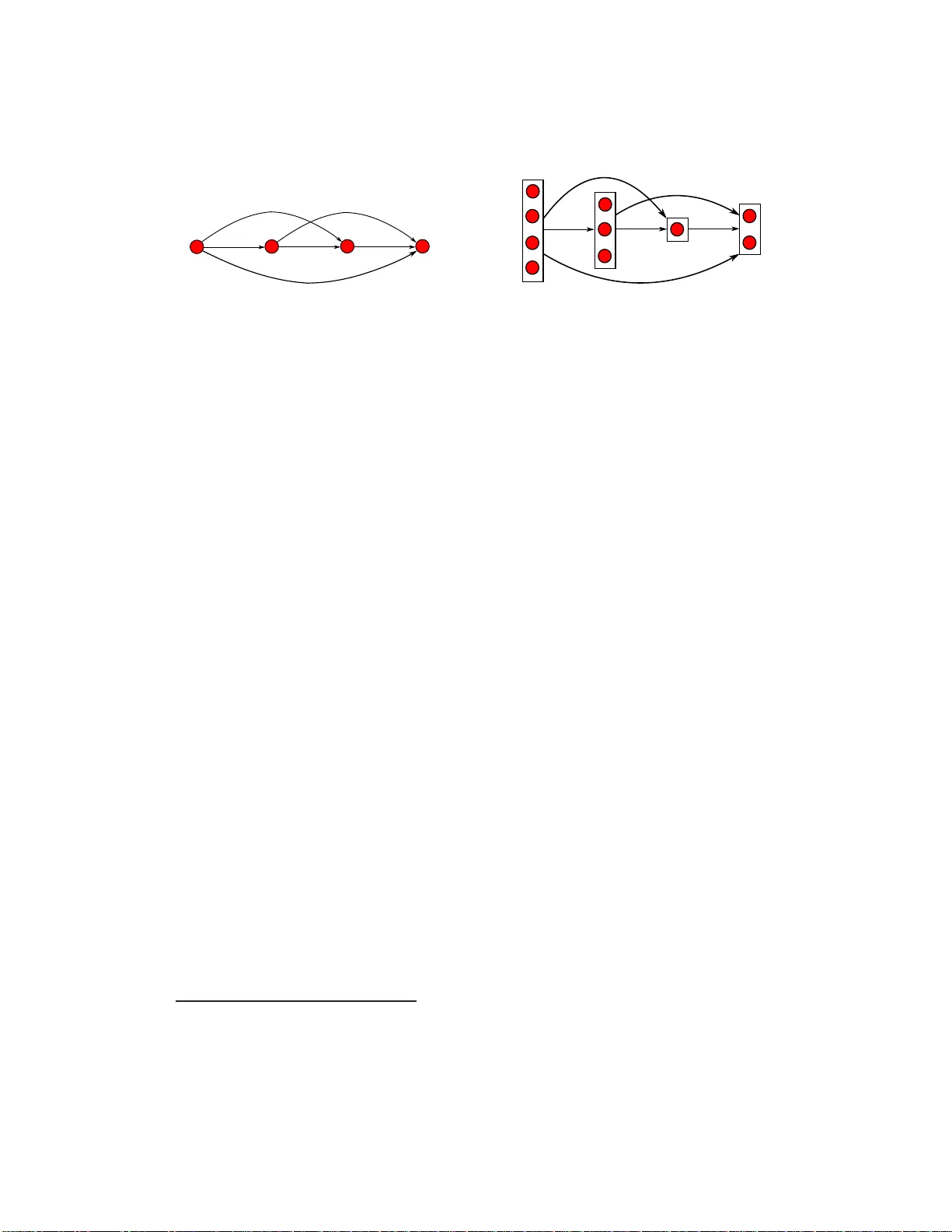
This paper addresses the general problem of modelling and learning rank data with ties. We propose a probabilistic generative model, that models the process as permutations over partitions. This results in super-exponential combinatorial state space with unknown numbers of partitions and unknown ordering among them. We approach the problem from the discrete choice theory, where subsets are chosen in a stagewise manner, reducing the state space per each stage significantly. Further, we show that with suitable parameterisation, we can still learn the models in linear time. We evaluate the proposed models on the problem of learning to rank with the data from the recently held Yahoo! challenge, and demonstrate that the models are competitive against well-known rivals.
💡 Research Summary
**
The paper tackles the long‑standing problem of learning from rank data that contain ties. Traditional probabilistic ranking models either assume a total order (thus ignoring ties) or treat ties by enumerating all possible permutations of tied items, which leads to a combinatorial explosion: the number of ordered partitions grows super‑exponentially with the number of items. To overcome this, the authors introduce a generative model that treats a ranking as a sequence of ordered partitions—each partition groups items that share the same rank, and the partitions themselves are ordered from the highest to the lowest rank.
The generative process is defined stage‑wise: at stage k a subset (P_k) of the remaining items (R_k) is selected and placed as the k‑th partition; the remaining set becomes (R_{k+1}=R_k\setminus P_k). The probability of choosing a particular subset is expressed through a score function (s(P_k)=\sum_{i\in P_k}\mathbf{w}^\top\mathbf{x}_i), where (\mathbf{x}_i) is the feature vector of item i and (\mathbf{w}) are learnable parameters. Formally,
\
📜 Original Paper Content
🚀 Synchronizing high-quality layout from 1TB storage...