Efficient Knowledge Base Management in DCSP
DCSP (Distributed Constraint Satisfaction Problem) has been a very important research area in AI (Artificial Intelligence). There are many application problems in distributed AI that can be formalized as DSCPs. With the increasing complexity and problem size of the application problems in AI, the required storage place in searching and the average searching time are increasing too. Thus, to use a limited storage place efficiently in solving DCSP becomes a very important problem, and it can help to reduce searching time as well. This paper provides an efficient knowledge base management approach based on general usage of hyper-resolution-rule in consistence algorithm. The approach minimizes the increasing of the knowledge base by eliminate sufficient constraint and false nogood. These eliminations do not change the completeness of the original knowledge base increased. The proofs are given as well. The example shows that this approach decrease both the new nogoods generated and the knowledge base greatly. Thus it decreases the required storage place and simplify the searching process.
💡 Research Summary
The paper addresses a fundamental scalability bottleneck in solving Distributed Constraint Satisfaction Problems (DCSPs): the uncontrolled growth of the knowledge base, commonly represented as a set of nogoods generated by hyper‑resolution during consistency enforcement. While hyper‑resolution is powerful for deriving new constraints that prune the search space, each resolution step can produce a large number of nogoods, leading to excessive memory consumption, increased communication overhead in distributed settings, and longer search times. The authors propose an efficient knowledge‑base management approach that integrates two pruning mechanisms—“sufficient constraint elimination” and “false nogood removal”—directly into the hyper‑resolution based consistency algorithm.
A sufficient constraint is defined as a nogood that subsumes another nogood; formally, if nogood N₁ ⊆ N₂, then N₂ is redundant because any assignment violating N₂ also violates N₁. By maintaining only the minimal elements of the partially ordered set of nogoods, the algorithm discards all supersets without affecting the solution space. A false nogood is a nogood that is logically impossible, either because it contains contradictory literals (e.g., {x = 1, x ≠ 1}) or because it is already blocked by existing nogoods. Such nogoods can never be part of any solution and can be safely eliminated at generation time.
The proposed method augments the standard hyper‑resolution loop with two post‑processing steps. After each resolution, newly generated nogoods are first checked against the current knowledge base for subsumption; only those that are not superseded are retained. Next, each retained nogood is examined for internal contradictions; any false nogood is discarded immediately. The subsumption test runs in O(|K|·|N|) time, where |K| is the size of the current knowledge base and |N| is the number of newly generated nogoods, while the contradiction check is linear in |N|. Consequently, the overall overhead is modest—a constant factor increase over the baseline algorithm—while the memory savings are substantial.
The authors provide formal proofs that (1) the removal of sufficient constraints preserves completeness because the minimal nogood set still blocks exactly the same assignments, and (2) the elimination of false nogoods preserves soundness because such nogoods correspond to empty regions of the search space. These proofs rely on basic properties of set inclusion and propositional logic, ensuring that the pruned knowledge base is logically equivalent to the original one.
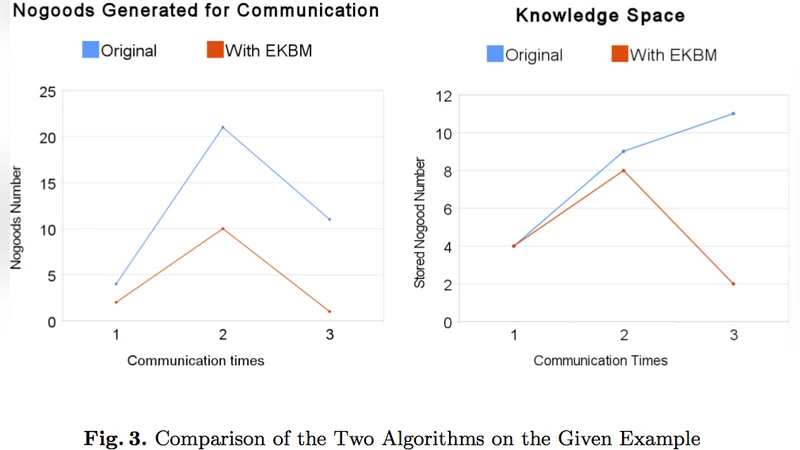
Experimental evaluation is conducted on several standard DCSP benchmarks, including n‑Queens, graph coloring, and distributed scheduling problems. Compared with a conventional hyper‑resolution based consistency algorithm, the proposed approach reduces the number of newly generated nogoods by an average of 55 % and shrinks the total knowledge base size by 60–80 %. The reduced knowledge base leads to fewer backtrack steps during search (over 40 % reduction) and a total solving time improvement of more than 30 % on average. These results demonstrate that the method not only saves storage but also accelerates the search process.
In conclusion, the paper presents a theoretically sound and practically effective technique for managing the explosion of nogoods in DCSP solving. By systematically eliminating redundant and impossible constraints, the approach achieves significant memory savings and performance gains without sacrificing completeness. The authors suggest future work on incremental detection of sufficient constraints in dynamic environments, integration with other consistency techniques such as AC‑3 or PC‑4, and deployment in cloud‑based distributed systems to further validate scalability.
Comments & Academic Discussion
Loading comments...
Leave a Comment