Next-generation Astronomy
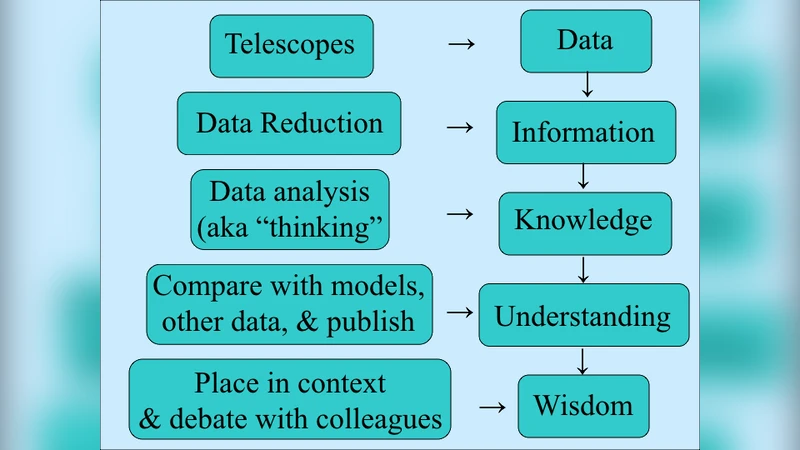
Fundamental changes are taking place in the way we do astronomy. In twenty years time, it is likely that most astronomers will never go near a cutting-edge telescope, which will be much more efficiently operated in service mode. They will rarely analyse data, since all the leading-edge telescopes will have pipeline processors. And rather than competing to observe a particularly interesting object, astronomers will more commonly group together in large consortia to observe massive chunks of the sky in carefully designed surveys, generating petabytes of data daily. We can imagine that astronomical productivity will be higher than at any previous time. PhD students will mine enormous survey databases using sophisticated tools, cross-correlating different wavelength data over vast areas, and producing front-line astronomy results within months of starting their PhD. The expertise that now goes into planning an observation will instead be devoted to planning a foray into the databases. In effect, people will plan observations to use the Virtual Observatory. Here I examine the process of astronomical discovery, take a crystal ball to see how it might change over the next twenty years, and identify further opportunities for the future, as well as identifying pitfalls against which we must remain vigilant.
💡 Research Summary
The paper presents a forward‑looking scenario in which the practice of astronomy undergoes a profound transformation over the next two decades. Today, most astronomers spend a substantial portion of their time planning observations, traveling to telescopes, and manually reducing raw data before scientific interpretation. The author argues that this model will be largely supplanted by fully automated, service‑mode observatories equipped with real‑time data‑reduction pipelines. In the envisioned future, every cutting‑edge ground‑based or space‑based facility will deliver calibrated, quality‑checked, and partially analyzed data products directly to a centralized Virtual Observatory (VO) infrastructure. Standardized metadata, open APIs, and cloud‑based storage will make petabytes of multi‑wavelength observations searchable and interoperable on demand.
Consequently, the primary skill set of astronomers will shift from “how to observe” to “how to mine and integrate massive data sets.” Large, consortium‑driven sky surveys will dominate, generating daily data streams measured in petabytes. To handle this volume, distributed computing, containerized analysis pipelines, and advanced machine‑learning techniques will become essential. Anomalies, transient events, and novel astrophysical phenomena will be flagged automatically by deep‑learning classifiers, allowing researchers to focus on higher‑level scientific questions rather than low‑level data cleaning.
The paper highlights several implications for the research community. First, PhD students will be able to produce publishable results within months by exploiting cross‑matched catalogs across the electromagnetic spectrum, dramatically shortening the time from project inception to scientific output. Second, the planning phase will concentrate on designing database queries, selecting appropriate survey footprints, and optimizing statistical analyses rather than negotiating telescope time. Third, large consortia will share not only raw observations but also curated data products, analysis code, and machine‑learning models, fostering a more collaborative environment.
However, the author cautions against several pitfalls. Automated pipelines, while efficient, can propagate systematic errors across entire data sets if not rigorously validated. The loss of hands‑on observing experience may erode intuition about instrumental effects and limit the community’s ability to recognize truly unexpected phenomena. Moreover, the concentration of high‑performance computing resources in a few institutions could exacerbate inequities in access to data and analysis capabilities. To mitigate these risks, the paper recommends establishing independent “red‑team” audits of pipelines, embedding data‑science training into graduate curricula, and developing international policies for fair resource allocation and open‑access data sharing.
In summary, the author envisions a future where astronomy’s productivity reaches unprecedented levels due to the convergence of automated observatories, massive survey databases, and sophisticated data‑mining tools. Yet, realizing this potential will require deliberate safeguards, continuous human oversight, and a re‑balanced educational focus to ensure that the discipline remains both innovative and scientifically robust.
Comments & Academic Discussion
Loading comments...
Leave a Comment