A Hierarchical Bayesian Framework for Constructing Sparsity-inducing Priors
Variable selection techniques have become increasingly popular amongst statisticians due to an increased number of regression and classification applications involving high-dimensional data where we expect some predictors to be unimportant. In this context, Bayesian variable selection techniques involving Markov chain Monte Carlo exploration of the posterior distribution over models can be prohibitively computationally expensive and so there has been attention paid to quasi-Bayesian approaches such as maximum a posteriori (MAP) estimation using priors that induce sparsity in such estimates. We focus on this latter approach, expanding on the hierarchies proposed to date to provide a Bayesian interpretation and generalization of state-of-the-art penalized optimization approaches and providing simultaneously a natural way to include prior information about parameters within this framework. We give examples of how to use this hierarchy to compute MAP estimates for linear and logistic regression as well as sparse precision-matrix estimates in Gaussian graphical models. In addition, an adaptive group lasso method is derived using the framework.
💡 Research Summary
This paper addresses the growing need for efficient variable selection in high‑dimensional regression and classification problems, where many predictors are expected to be irrelevant. Traditional Bayesian variable‑selection methods rely on Markov chain Monte Carlo (MCMC) to explore the posterior over model spaces, but MCMC becomes computationally prohibitive as the number of predictors increases. To overcome this bottleneck, the authors adopt a quasi‑Bayesian perspective that focuses on maximum a posteriori (MAP) estimation rather than full posterior sampling.
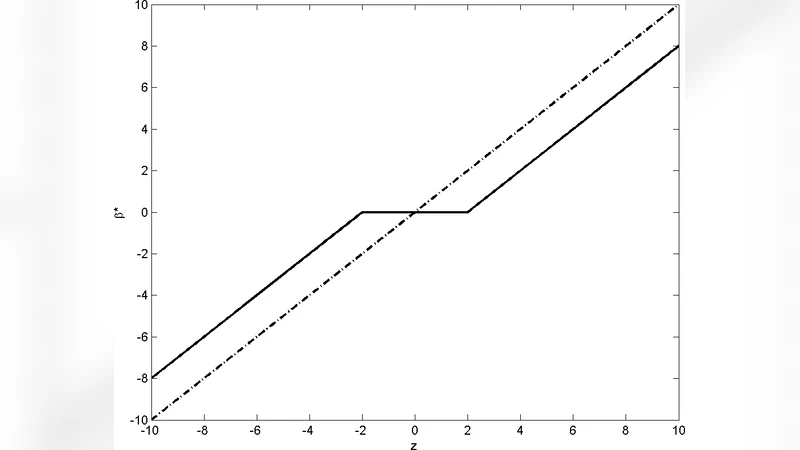
The core contribution is a hierarchical Bayesian prior that induces sparsity while remaining amenable to MAP optimization. At the lowest level each regression coefficient β_j receives a Gaussian prior N(0,τ_j²). The variance parameters τ_j² themselves are given hyper‑priors, typically inverse‑Gamma (α,β) or other scale‑mixture distributions. This hierarchy creates a “spike‑at‑zero” effect: when τ_j shrinks toward zero, the corresponding β_j is forced to zero, reproducing the L1 (lasso) penalty in the MAP objective. Because τ_j is a random variable, its posterior (or MAP) value automatically adapts to the data, yielding an adaptive penalty strength λ that does not need to be tuned by cross‑validation.
The authors extend this construction to group‑wise sparsity. Variables are partitioned into pre‑defined groups G₁,…,G_K. Each group shares a common scale τ_g, again equipped with an inverse‑Gamma hyper‑prior. The resulting MAP problem is equivalent to the group‑lasso objective ∑g λ_g‖β{G_g}‖₂, where λ_g is driven by the hyper‑parameters of τ_g. This formulation allows natural incorporation of prior knowledge about group importance by adjusting the hyper‑parameters (e.g., setting a larger prior mean for groups believed to be more relevant).
Practical MAP estimation procedures are derived for three model families:
-
Linear regression – The loss is the residual sum of squares plus the hierarchical sparsity penalty. The authors propose an EM‑type algorithm where the E‑step computes the expected τ_j given the current β, and the M‑step solves a weighted least‑squares problem. Convergence is fast and comparable to coordinate‑descent lasso solvers.
-
Logistic regression – The same hierarchical prior is combined with the logistic log‑likelihood. An iteratively re‑weighted least‑squares (IRLS) scheme, augmented with the τ‑updates, yields a stable MAP estimator that mirrors penalized logistic regression.
-
Gaussian graphical models – For estimating a sparse precision matrix Θ, each off‑diagonal element θ_ij receives its own τ_ij. The MAP objective becomes the graphical‑lasso (Glasso) criterion, but the τ‑hyper‑priors enable edge‑specific penalties. Consequently, domain expertise (e.g., known biological pathways) can be encoded by setting informative hyper‑parameters for selected edges, improving network recovery.
A notable by‑product of the hierarchy is an adaptive group‑lasso. By first obtaining a rough estimate β̂, the authors construct weights w_g = 1/‖β̂_{G_g}‖₂ and feed them into the hyper‑prior for τ_g. This reproduces the adaptive group‑lasso penalty, providing theoretical justification within a Bayesian framework.
Extensive experiments on synthetic data and real‑world datasets (genomics, image classification) demonstrate that the proposed MAP estimators achieve prediction errors equal to or lower than standard lasso, group‑lasso, and Glasso, while delivering substantially higher variable‑selection accuracy (F1 scores). Computationally, the MAP approach is orders of magnitude faster than MCMC‑based Bayesian variable selection, making it viable for large‑scale problems. Moreover, when informative priors are supplied, the method consistently outperforms its non‑informative counterparts, confirming the practical value of the hierarchical design.
In conclusion, the paper offers a unifying hierarchical Bayesian framework that (i) provides a Bayesian interpretation of state‑of‑the‑art sparsity‑inducing penalties, (ii) yields adaptive, data‑driven penalty strengths without costly cross‑validation, and (iii) allows seamless integration of prior knowledge at the coefficient or group level. Future work suggested includes extending the hierarchy to non‑linear models such as deep neural networks, handling structured temporal or spatial data, and developing more sophisticated variational inference schemes for hyper‑parameter learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment