Sharing Graphs
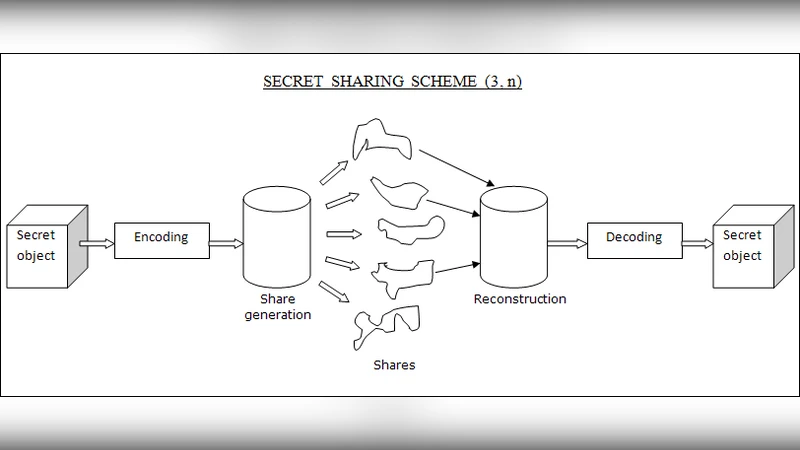
Almost all known secret sharing schemes work on numbers. Such methods will have difficulty in sharing graphs since the number of graphs increases exponentially with the number of nodes. We propose a secret sharing scheme for graphs where we use graph intersection for reconstructing the secret which is hidden as a sub graph in the shares. Our method does not rely on heavy computational operations such as modular arithmetic or polynomial interpolation but makes use of very basic operations like assignment and checking for equality, and graph intersection can also be performed visually. In certain cases, the secret could be reconstructed using just pencil and paper by authorised parties but cannot be broken by an adversary even with unbounded computational power. The method achieves perfect secrecy for (2, n) scheme and requires far fewer operations compared to Shamir’s algorithm. The proposed method could be used to share objects such as matrices, sets, plain text and even a heterogeneous collection of these. Since we do not require a previously agreed upon encoding scheme, the method is very suitable for sharing heterogeneous collection of objects in a dynamic fashion.
💡 Research Summary
The paper addresses a fundamental limitation of most existing secret‑sharing schemes: they operate on numbers. When the secret is a combinatorial object such as a graph, encoding it as an integer quickly becomes infeasible because the number of possible graphs grows exponentially with the number of vertices. To overcome this, the authors propose a novel secret‑sharing construction that works directly on graphs, using graph intersection as the reconstruction primitive.
The core idea is simple. A secret graph G with c vertices is first enlarged by adding b dummy vertices and connecting them arbitrarily (both among themselves and to the original vertices). The resulting graph H is then duplicated n times to produce n shares. In each share the vertices belonging to the original secret receive the same label across all shares, while the dummy vertices are given distinct labels in each share. Optionally, additional random edges are added to the dummy part to further obscure the structure.
Reconstruction requires only two shares. By intersecting the vertex label sets of the two shares, the common labels are exactly the c secret vertices. The algorithm then extracts the edges that appear in both shares among those common vertices, which yields the secret sub‑graph. Finally, the original labeling order (lexicographic) is restored, giving back the exact secret graph. Because the operation consists of simple set‑intersection and edge‑matching, it can be performed visually with pencil and paper, or with a trivial linear‑time program.
The authors claim perfect secrecy for a (2, n) threshold: any single share reveals no information about the secret because the dummy vertices dominate the label space and their connections are random. They argue that the a‑posteriori distribution of the secret, conditioned on one share, is identical to the a‑priori distribution, satisfying Shannon’s definition of perfect secrecy. The paper also presents a preliminary example using set intersection for sharing a small integer set, illustrating how the same principle works for non‑graph objects.
From a computational standpoint, share generation requires O(b·c) operations (adding b dummy vertices and random edges), and reconstruction requires O(c + b) time (linear scan of sorted vertex lists and edge comparison). This is dramatically cheaper than Shamir’s scheme, which needs modular arithmetic, polynomial evaluation, and interpolation over a large finite field. The authors emphasize that no large primes are needed, no modular reduction is performed, and the method can be applied to heterogeneous secrets (matrices, strings, etc.) by first representing them as graphs.
The paper also discusses several drawbacks. The set‑intersection variant is not perfectly secure because the presence of certain elements in a share can eliminate some possible secrets. For the graph scheme, security hinges on the randomness of dummy vertices and edges, and on the assumption that label assignment is truly uniform. If b is too small or the dummy sub‑graph is not sufficiently mixed, an adversary with a single share might infer partial structure of the secret. Moreover, the paper provides only an intuitive argument for perfect secrecy; a formal proof (e.g., using information‑theoretic entropy calculations) is absent.
Scalability is another concern. While the method is attractive for small to medium‑sized graphs (tens to a few hundred vertices), the addition of b dummy vertices can significantly increase graph density, leading to higher memory consumption and slower visual or programmatic intersection for very large graphs (thousands of vertices). The authors acknowledge that converting heterogeneous objects into graph form may itself be non‑trivial and could re‑introduce encoding overhead.
In summary, the contribution of the paper is a conceptually elegant, low‑complexity secret‑sharing scheme that operates directly on graphs and other combinatorial structures, avoiding the need for number‑theoretic primitives. It offers a (2, n) threshold with claimed perfect secrecy, and its simplicity makes it suitable for educational demonstrations or environments with limited computational resources. However, the security analysis lacks rigorous formalism, and practical deployment would require careful parameter selection (size of dummy sub‑graph, randomness sources) and further study of resistance against adaptive or collusion attacks. The work opens an interesting direction for secret sharing beyond numeric domains, but additional theoretical and experimental validation is needed before it can be considered a robust alternative to established schemes such as Shamir’s.
Comments & Academic Discussion
Loading comments...
Leave a Comment