Teaching Spreadsheets: Curriculum Design Principles
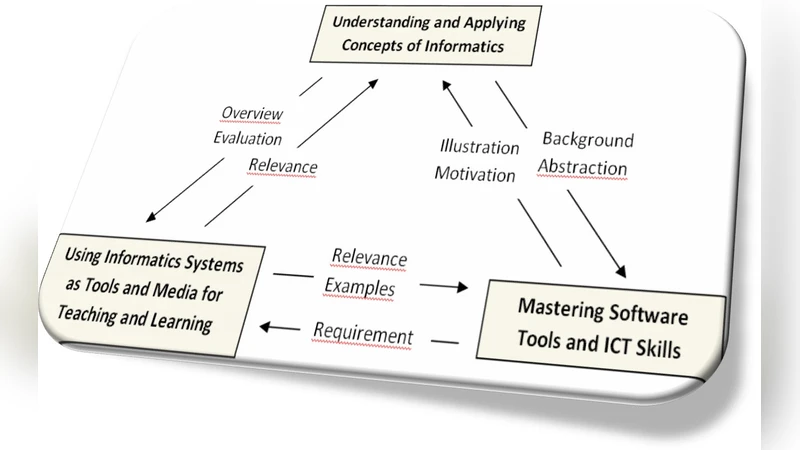
EuSpRIG concerns direct researchers to revisit spreadsheet education, taking into account error auditing tools, checklists, and good practices. This paper aims at elaborating principles to design a spreadsheet curriculum. It mainly focuses on two important issues. Firstly, it is necessary to establish the spreadsheet invariants to be taught, especially those concerning errors and good practices. Secondly, it is important to take into account the learners’ ICT experience, and to encourage them to attitudes that foster self-learning. We suggest key principles for spreadsheet teaching, and we illustrate them with teaching guidelines.
💡 Research Summary
The paper addresses the growing concern within the European Spreadsheet Risks Interest Group (EuSpRIG) that spreadsheet errors continue to cause significant financial and operational damage, and argues that the root of the problem lies in inadequate education. It proposes a comprehensive set of curriculum design principles that shift spreadsheet teaching from a purely functional, “how‑to” approach to a risk‑aware, quality‑focused pedagogy. Central to the authors’ argument is the notion of “spreadsheet invariants” – a core set of concepts that must be taught at every level of instruction. These invariants include a taxonomy of common error types (reference errors, logical inconsistencies, data entry mistakes, hidden cells, etc.), the systematic use of error‑auditing tools (built‑in trace precedents/dependents, third‑party audit add‑ins, visual inspection techniques), and a suite of best‑practice guidelines (consistent naming conventions, cell protection, documentation, version control, modular design). By codifying these invariants, the curriculum gains a stable backbone that ensures learners develop a transferable mental model for error detection and prevention.
The second major principle concerns learner heterogeneity. The authors recommend a diagnostic pre‑assessment to gauge each student’s prior ICT experience, spreadsheet exposure, and familiarity with related concepts such as programming or data analysis. Based on this information, the curriculum should be tiered: beginners focus on basic cell formatting, simple formulas, and interpreting error messages; intermediate learners tackle complex functions, data validation, conditional formatting, and the use of built‑in audit features; advanced participants engage with macro/VBA development, automated testing scripts, and architectural design of large‑scale models. This differentiation prevents frustration among novices while keeping more experienced students challenged, thereby maintaining motivation across the cohort.
A third pillar is the cultivation of self‑directed learning attitudes and collaborative verification practices. The paper advocates the integration of checklists and error‑log journals into personal learning portfolios, encouraging students to treat each mistake as a data point for meta‑cognitive analysis. Regular peer‑review sessions are prescribed, where learners exchange spreadsheets, apply the checklist, and provide constructive feedback. This peer‑review loop not only reinforces the checklist habit but also creates a culture where failure is openly examined rather than concealed, fostering deeper understanding of error causality.
The fourth principle introduces a “repetitive feedback loop” as the structural core of each instructional unit. The cycle proceeds as follows: brief lecture → hands‑on exercise → automated error audit → immediate feedback (from the tool, instructor, and peers) → revised exercise. Automated audit tools are configured to assign severity weights to different error categories and to suggest concrete remediation steps, ensuring feedback is specific and actionable. By embedding this loop, learners experience instant error recognition, practice correction, and internalize the correction process, which promotes long‑term retention and the development of a habit of continuous quality assurance.
Finally, the authors translate these theoretical principles into concrete teaching guidelines. A sample four‑week module is outlined: Week 1 introduces spreadsheet architecture and the taxonomy of errors; Week 2 focuses on hands‑on use of audit tools and visual inspection; Week 3 implements checklist‑driven model verification; Week 4 culminates in a peer‑review workshop and portfolio submission. Each week specifies learning objectives, core content, assessment criteria, and expected outcomes, providing instructors with a ready‑to‑use roadmap.
In sum, the paper delivers a pragmatic, evidence‑based framework for redesigning spreadsheet curricula. By defining immutable error‑prevention concepts, tailoring instruction to learners’ ICT backgrounds, fostering self‑regulated and collaborative learning habits, and embedding iterative feedback cycles, the proposed approach aims to reduce spreadsheet‑related risk at its source and to equip students with durable competencies for high‑quality data modeling and analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment