Simplifying Complex Software Assembly: The Component Retrieval Language and Implementation
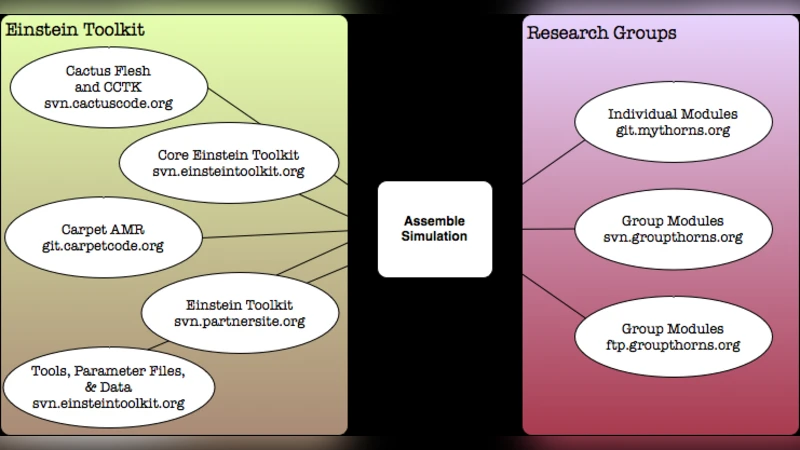
Assembling simulation software along with the associated tools and utilities is a challenging endeavor, particularly when the components are distributed across multiple source code versioning systems. It is problematic for researchers compiling and running the software across many different supercomputers, as well as for novices in a field who are often presented with a bewildering list of software to collect and install. In this paper, we describe a language (CRL) for specifying software components with the details needed to obtain them from source code repositories. The language supports public and private access. We describe a tool called GetComponents which implements CRL and can be used to assemble software. We demonstrate the tool for application scenarios with the Cactus Framework on the NSF TeraGrid resources. The tool itself is distributed with an open source license and freely available from our web page.
💡 Research Summary
The paper addresses a pervasive problem in scientific computing: assembling large, modular software stacks whose components are scattered across multiple version‑control repositories. Researchers who need to run simulations on diverse supercomputing platforms often spend hours manually cloning dozens of repositories, checking out the correct branches or tags, handling authentication for private sources, and resolving inter‑component dependencies. This process is error‑prone, hampers reproducibility, and creates a steep learning curve for newcomers. To streamline this workflow, the authors introduce two tightly coupled contributions: the Component Retrieval Language (CRL) and an implementation tool called GetComponents.
CRL is a lightweight, declarative scripting language designed to describe every piece of information required to retrieve a software component. Its syntax consists of clearly named blocks such as component, repository, type, url, branch, tag, auth, and private. The type field selects the version‑control system (Git, SVN, CVS, or plain HTTP), while url points to the repository location. Version selection is expressed with branch or tag, and optional commit identifiers allow precise pinning. Authentication details—user/password, SSH keys, OAuth tokens—are encapsulated in an auth block, and a separate private block can hide sensitive credentials from the main script, encouraging secure handling via environment variables. Crucially, CRL also supports a depends_on directive, enabling the author to declare explicit dependency relationships among components. This information is later used to construct a directed acyclic graph (DAG) that guarantees a correct retrieval order and detects circular dependencies before any network activity begins. The language’s design emphasizes readability, extensibility (new VCS types or auth mechanisms can be added by extending the parser), and security (no hard‑coded secrets, optional encryption of private sections).
GetComponents is a Python‑3 command‑line utility that parses a CRL file, builds the dependency graph, and orchestrates the download, checkout, verification, and optional build steps for each component. Its execution pipeline can be summarized as follows:
- Parsing – The CRL file is tokenized and transformed into an internal representation; syntax errors are reported with line numbers for easy debugging.
- Dependency analysis –
depends_onrelationships are resolved into a DAG; topological sorting determines a safe execution order, and any cycles trigger an early abort with a clear diagnostic. - Scheduling – Independent components are fetched in parallel using a thread pool, while respecting user‑specified limits on concurrent network connections.
- Retrieval – For each node, GetComponents invokes the appropriate VCS client (git, svn, cvs) or HTTP downloader, applies the authentication method defined in the CRL, and checks out the exact revision.
- Integrity check – Optional SHA‑256 or MD5 checksums can be supplied; the tool verifies them after download to guard against corruption.
- Post‑processing – If the CRL includes a
buildorruncommand, GetComponents executes it in the component’s directory, allowing seamless integration with existing build systems such as CMake, Autotools, or custom scripts.
The tool also provides robust error handling: failed downloads trigger exponential back‑off retries, and all actions are logged in JSON format for downstream analysis or CI integration. A --dry-run flag lets users preview the dependency graph and planned actions without touching the network, which is valuable for large deployments.
To validate the approach, the authors applied CRL and GetComponents to the Cactus Framework, a widely used modular infrastructure for astrophysics and geophysics simulations. Cactus consists of a core engine plus dozens of “thorns” (plugins) and external libraries, each hosted in separate repositories, some of which are private. Traditionally, setting up a full Cactus installation on a new supercomputer required manual cloning of each thorn, careful version alignment, and bespoke build scripts—often taking several hours. By authoring a single CRL file that enumerated all required thorns, their repositories, and version tags, the researchers were able to invoke GetComponents on NSF TeraGrid resources (e.g., Stampede, Kraken, Ranger) and obtain a complete, reproducible Cactus stack in under ten minutes. The automated process eliminated version mismatches, reduced human error, and dramatically shortened the time‑to‑science.
The paper contrasts CRL/GetComponents with existing package managers such as Spack and EasyBuild. While those systems excel at binary package handling and provide sophisticated dependency resolution, they are less suited for scenarios where researchers need to pull source code directly from a mixture of public and private VCS endpoints, or when they must work with the latest development branches that are not yet packaged. CRL fills this niche by allowing fine‑grained control over source retrieval while still offering automated dependency management.
Limitations are acknowledged. Currently supported VCS types are limited to Git, SVN, CVS, and HTTP; extending to Mercurial, Perforce, or newer cloud‑native services would require additional adapters. Complex build dependencies that span multiple languages or require environment modules are not fully automated; the user must still provide appropriate post‑processing commands. Security-wise, although CRL encourages external credential injection, storing authentication data in plain files remains a risk for highly regulated institutions. The authors suggest future integration with secret‑management tools (e.g., HashiCorp Vault) to mitigate this.
Future work outlined includes:
- Container integration – coupling CRL with Docker or Singularity to produce fully reproducible container images that encapsulate both source code and runtime environment.
- CI/CD pipelines – embedding GetComponents in continuous integration workflows so that each code change automatically triggers a fresh assembly of the entire stack, enabling rapid regression testing across multiple architectures.
- Web‑based GUI – developing a browser interface that assists users in constructing CRL files through drag‑and‑drop component selection, visualizing the dependency graph, and monitoring retrieval progress.
- Extended VCS support – adding plugins for emerging version‑control platforms (e.g., GitLab, Azure DevOps) and for large‑scale data repositories accessed via Globus or S3.
In conclusion, the paper delivers a practical, open‑source solution that significantly lowers the barrier to assembling complex scientific software ecosystems. By formalizing component retrieval in a concise language and providing a robust execution engine, the authors demonstrate measurable gains in installation speed, reproducibility, and error reduction on real supercomputing resources. The approach is poised to benefit a broad range of disciplines that rely on modular, source‑driven software stacks, and the open‑source nature invites community contributions to broaden its applicability and maturity.
Comments & Academic Discussion
Loading comments...
Leave a Comment