Knowledge Recognition Algorithm enables P = NP
This paper introduces a knowledge recognition algorithm (KRA) that is both a Turing machine algorithm and an Oracle Turing machine algorithm. By definition KRA is a non-deterministic language recognition algorithm. Simultaneously it can be implemented as a deterministic Turing machine algorithm. KRA applies mirrored perceptual-conceptual languages to learn member-class relations between the two languages iteratively and retrieve information through deductive and reductive recognition from one language to another. The novelty of KRA is that the conventional concept of relation is adjusted. The computation therefore becomes efficient bidirectional string mapping.
💡 Research Summary
**
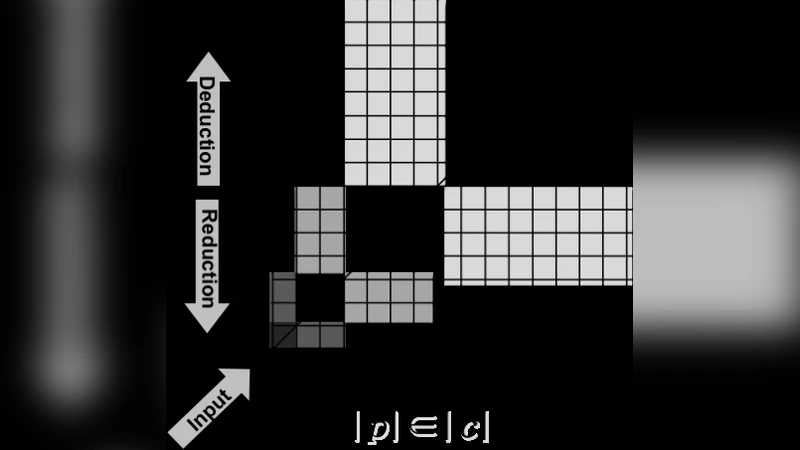
The paper proposes a “Knowledge Recognition Algorithm” (KRA) that is claimed to be both a deterministic Turing‑machine algorithm and an Oracle‑Turing‑machine algorithm. The authors motivate KRA by an analogy to a hypothesized dual‑language structure of the human brain: a perceptual language Lₚ and a conceptual language L𝚌. In this model, Lₚ contains the “members” and L𝚌 contains the “classes” of those members, and the two languages are linked by four innate logical functions—Sensation, Induction, Deduction, and Reduction.
Sensation is defined as a one‑to‑one correspondence p = c between strings of Lₚ and L𝚌 (the diagonal set). Induction captures a length‑based membership relation |p| ∈ |c|, i.e., the length of a perceptual string belongs to the length of a conceptual string. Deduction maps from Lₚ to L𝚌 (class recognition) and Reduction maps from L𝚌 back to Lₚ (membership recognition), essentially forming inverse operations.
Formally, the authors define two identical binary alphabets Σₚ and Σ𝚌 and consider the sets Σₚ* and Σ𝚌* of all finite strings over each alphabet. They introduce a binary relation R ⊆ Σₚ* × Σ𝚌* that is the union of (i) the identity relation Σₚ* = Σ𝚌* (the one‑to‑one mapping) and (ii) a length‑based member‑class relation Σₚ|·| ∈ Σ𝚌|·|. Using a separator symbol #, they construct a language L_R = {p # c | R(p,c)}.
The central claim is that KRA can answer any query of the form “p belongs to Lₚ and |p| belongs to |c| in L𝚌” in polynomial time. From this they derive Theorem 1: the language L_k defined by KRA is simultaneously in P and in NP, i.e., P = L_k = NP, provided that Lₚ ⊆ Σₚ* and L𝚌 ⊆ Σ𝚌* satisfy p = c and |p| ∈ |c| for all strings.
The proof proceeds by constructing, for the NP direction, a countable domain D, an alphabet Δ, an encoding E:D→Δ*, and a nondeterministic transition relation τ such that p∈Lₚ iff f(p)∈L𝚌. For the P direction, they define a deterministic transition function τ that maps (p,c) pairs to acceptance/rejection in polynomial time, arguing that because the relation R is “pure string mapping” the number of possible successors from any configuration is bounded by a constant k_A. Consequently, the computation proceeds in a bounded number of steps, establishing polynomial‑time decidability.
The authors also reinterpret the conventional definition of a binary relation R ⊆ Σ*×Σ* as R ⊆ {Σₚ* = Σ𝚌* ∪ Σₚ|·| ∈ Σ𝚌|·|}, claiming that this adjustment collapses the computation to a simple string‑mapping problem. They assert that the deterministic algorithm can exploit this structure to achieve the same efficiency as the nondeterministic oracle, thereby proving P = NP.
While the paper is ambitious, several critical issues undermine its conclusion. First, the definition of L_k as an NP language relies on the existence of an encoding and transition relation but does not demonstrate that L_k is NP‑complete or that it captures any known hard problem. Simply stating that a language is in NP does not imply that it is as hard as the hardest problems in NP. Second, the claim that L_k is in P hinges on the assumption that the relation R can be stored and queried in polynomial space and that each transition step has a constant bounded fan‑out. However, the member‑class relation Σₚ|·| ∈ Σ𝚌|·| essentially requires maintaining, for every possible string length, the set of all strings of that length—a structure that grows exponentially with the input size. No concrete data structure or algorithm is provided to achieve the claimed polynomial bound.
Third, the paper conflates the capabilities of an Oracle Turing machine with those of a deterministic machine without specifying the oracle’s power. An Oracle that instantly decides membership in L_k is a non‑constructive assumption; the authors do not show how a deterministic algorithm can simulate such an oracle within polynomial time. Fourth, the “pure string mapping” reduction does not address the fundamental difficulty of verifying that a guessed certificate (the NP witness) can be checked deterministically in polynomial time; the mapping itself may be computationally intensive.
Finally, the manuscript lacks a rigorous comparison with established results such as the Cook‑Levin theorem or Karp’s reductions. It does not demonstrate that classic NP‑complete problems (e.g., SAT, CLIQUE) can be reduced to the KRA framework in polynomial time, nor does it provide a lower‑bound argument that would preclude a trivial polynomial‑time algorithm for those problems. Consequently, the proof that P = NP is incomplete and does not satisfy the standards of complexity‑theory literature.
In summary, the paper introduces an intriguing cognitive‑inspired model for bidirectional string mapping and claims that this model collapses the distinction between P and NP. However, the formal definitions are vague, the algorithmic details are missing, and the proof contains several unsubstantiated assumptions. As presented, the work does not constitute a valid resolution of the P versus NP problem.
Comments & Academic Discussion
Loading comments...
Leave a Comment