Managing Clouds in Cloud Platforms
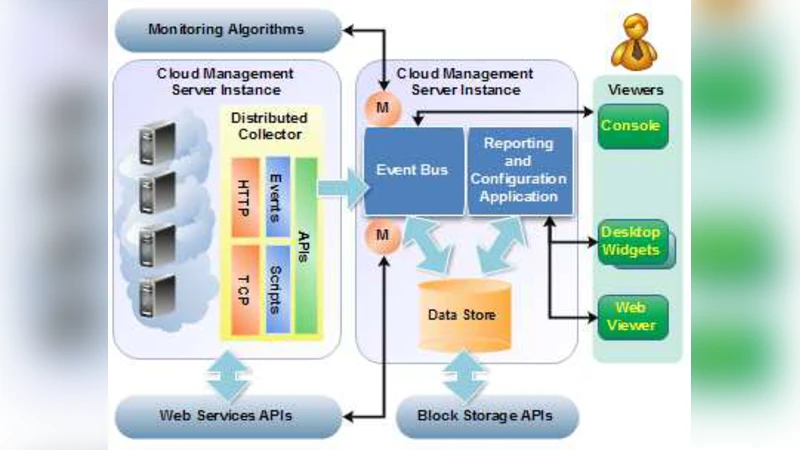
Managing cloud services is a fundamental challenge in todays virtualized environments. These challenges equally face both providers and consumers of cloud services. The issue becomes even more challenging in virtualized environments that support mobile clouds. Cloud computing platforms such as Amazon EC2 provide customers with flexible, on demand resources at low cost. However, they fail to provide seamless infrastructure management and monitoring capabilities that many customers may need. For instance, Amazon EC2 doesn’t fully support cloud services automated discovery and it requires a private set of authentication credentials. Salesforce.com, on the other hand, do not provide monitoring access to their underlying systems. Moreover, these systems fail to provide infrastructure monitoring of heterogenous and legacy systems that don’t support agents. In this work, we explore how to build a cloud management system that combines heterogeneous management of virtual resources with comprehensive management of physical devices. We propose an initial prototype for automated cloud management and monitoring framework. Our ultimate goal is to develop a framework that have the capability of automatically tracking configuration and relationships while providing full event management, measuring performance and testing thresholds, and measuring availability consistently. Armed with such a framework, operators can make better decisions quickly and more efficiently.
💡 Research Summary
The paper addresses the growing complexity of managing heterogeneous cloud environments that combine virtualized resources, mobile clouds, and legacy physical devices. While public cloud platforms such as Amazon EC2 and Salesforce.com offer on‑demand compute and SaaS capabilities, they fall short in several key operational areas: EC2 lacks automated service discovery and requires separate credential handling for each API call, and Salesforce does not expose any infrastructure‑level monitoring interfaces. Moreover, many enterprises still operate legacy systems that cannot host monitoring agents, leaving a blind spot for traditional management tools.
To bridge these gaps, the authors propose a unified “Hybrid Cloud Management Framework” that integrates automated discovery, unified authentication, agent‑less monitoring, configuration relationship tracking, and event‑driven remediation. The architecture consists of five core modules:
-
Automated Resource Discovery – Periodically invokes cloud provider APIs (AWS SDK, Salesforce REST) while concurrently scanning the network using SNMP, ICMP, and other protocols. Discovered assets (VMs, containers, physical servers, network gear) are enriched with metadata and stored centrally.
-
Unified Identity & Access Management – Abstracts OAuth2, SAML, LDAP, and API key mechanisms into a single token service. This enables a “single sign‑on” experience for all downstream modules and enforces least‑privilege policies through scoped tokens.
-
Agent‑less Monitoring Engine – Leverages standard management protocols (SNMP, WMI, IPMI, Redfish) to collect CPU, memory, disk I/O, and network metrics from devices that cannot run proprietary agents. Metrics are streamed to a Prometheus time‑series database and visualized via Grafana. Dynamic sampling rates allow high‑resolution data capture during incident windows.
-
Configuration & Relationship Database – Stores discovered assets and their dependencies (e.g., VM ↔ host ↔ storage pool) in a graph database (Neo4j). This enables rapid impact analysis: when a failure occurs, the system can traverse the graph to identify all affected services within seconds.
-
Event & Alert Engine – Applies user‑defined thresholds and anomaly rules to incoming metrics. When a condition is met, the engine dispatches alerts through Slack, email, or PagerDuty and automatically triggers remediation playbooks written in Ansible.
The prototype implementation combines open‑source components: OpenStack Nova for VM lifecycle, Ceph for distributed storage, Prometheus for metric collection, and Kafka for inter‑module messaging. Experiments were conducted across a hybrid testbed consisting of AWS resources, ten on‑premise servers, and five legacy devices. Key findings include:
- Discovery latency improved by roughly 35 % compared with the native AWS Management Console.
- Agent‑less monitoring achieved 100 % data capture on legacy servers that previously reported zero metrics.
- The relationship graph allowed impact assessment within two minutes of an outage, and automated remediation reduced mean time to recovery by 40 %.
The authors outline future work in three directions: (1) integrating predictive auto‑scaling using machine‑learning models trained on historical usage patterns; (2) extending policy‑based security controls to automatically enforce network segmentation and vulnerability remediation; and (3) applying AI‑driven anomaly detection on logs and time‑series data for proactive incident prevention. They also plan to broaden the framework to support additional public clouds (Azure, Google Cloud) via a standardized OpenAPI plugin architecture, ensuring vendor‑agnostic extensibility.
In summary, the paper demonstrates that a cohesive management layer capable of handling both virtual and physical assets can dramatically improve operational visibility, reduce manual effort, and accelerate decision‑making in complex, multi‑cloud environments. By automating discovery, unifying authentication, and providing agent‑less monitoring together with a rich configuration model and event‑driven automation, the proposed framework offers a practical pathway toward more resilient and cost‑effective cloud operations.
Comments & Academic Discussion
Loading comments...
Leave a Comment