An Architecture of Active Learning SVMs with Relevance Feedback for Classifying E-mail
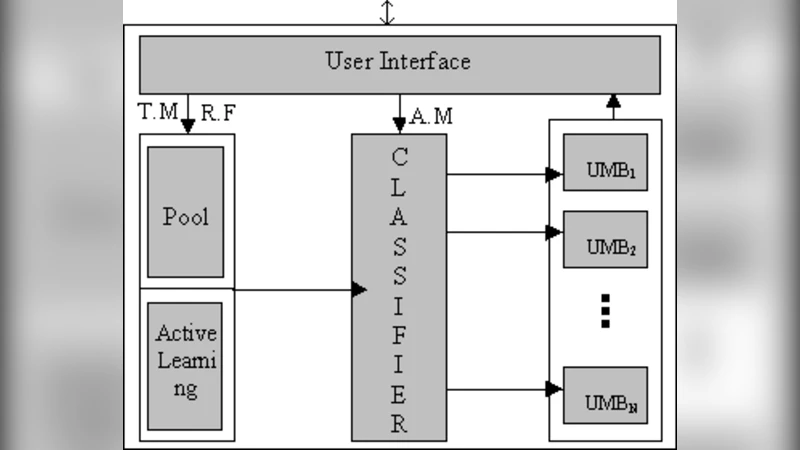
In this paper, we have proposed an architecture of active learning SVMs with relevance feedback (RF)for classifying e-mail. This architecture combines both active learning strategies where instead of using a randomly selected training set, the learner has access to a pool of unlabeled instances and can request the labels of some number of them and relevance feedback where if any mail misclassified then the next set of support vectors will be different from the present set otherwise the next set will not change. Our proposed architecture will ensure that a legitimate e-mail will not be dropped in the event of overflowing mailbox. The proposed architecture also exhibits dynamic updating characteristics making life as difficult for the spammer as possible.
💡 Research Summary
The paper proposes a novel architecture for e‑mail classification that integrates two complementary mechanisms: active learning (AL) for Support Vector Machines (SVMs) and relevance feedback (RF). Traditional spam filters either rely on a randomly chosen training set or on static models that are updated only periodically. In contrast, the proposed system continuously interacts with a pool of unlabeled e‑mails, selectively queries the most informative messages for user labeling (active learning), and immediately adjusts its decision boundary whenever a user corrects a mis‑classified message (relevance feedback).
Active Learning Component
Instead of training the SVM on a pre‑selected corpus, the learner maintains a large repository of unlabeled e‑mails. At each iteration it evaluates a utility measure—typically uncertainty (e.g., distance to the hyperplane) or representativeness (e.g., cluster centroids)—and requests labels for the top‑k most informative instances. This strategy dramatically reduces the number of human‑provided labels required to achieve a given accuracy, because each queried example yields maximal information about the current decision surface. The authors imply that the AL loop runs continuously, allowing the model to adapt to emerging spam patterns without waiting for a batch retraining phase.
Relevance Feedback Component
When a user discovers that a legitimate message has been marked as spam (or vice‑versa), the system records this correction as a relevance‑feedback instance. The corrected e‑mail is added to the training set, and the SVM’s support‑vector set is recomputed. If the newly added example lies on the opposite side of the margin, the set of support vectors changes; otherwise, the existing support vectors remain unchanged. This incremental update can be implemented with online or incremental SVM algorithms, ensuring that the model evolves in real time without a full retraining from scratch.
Practical Goals and Claims
- Preventing loss of legitimate e‑mail during mailbox overflow. In an overflow scenario, a legitimate message mistakenly classified as spam could be discarded. The RF mechanism guarantees that such an error is immediately corrected, thereby preserving the message.
- Dynamic resistance to spammers. Spammers constantly modify content (new keywords, obfuscation, image‑based spam) to evade static filters. By continuously selecting uncertain messages for labeling and instantly incorporating user corrections, the architecture forces spammers to constantly reinvent their tactics, raising the cost of successful attacks.
Implementation Details (inferred)
The paper does not provide exhaustive algorithmic specifics, but it is reasonable to assume:
- A linear or kernel‑based SVM with fixed hyperparameters (C, kernel type).
- An uncertainty‑sampling criterion such as margin‑sampling or entropy.
- Incremental SVM updates (e.g., LASVM or online SMO) to handle RF without full retraining.
Evaluation Gaps
The abstract lacks any empirical evaluation. Critical questions remain unanswered:
- How many labeled instances are required to reach a target false‑positive/false‑negative rate compared with a baseline random‑sampling approach?
- What is the computational overhead of evaluating uncertainty over a large mail pool in real time?
- How does the system behave under concept drift when spam characteristics evolve over weeks or months?
- What is the user burden associated with providing relevance feedback, and how does it affect overall usability?
Limitations and Challenges
- Scalability: Active learning requires scoring the entire unlabeled pool at each iteration, which may be prohibitive for high‑volume mail servers. Approximate methods (e.g., batch sampling, clustering) would be needed.
- User Dependency: RF assumes users will consistently flag misclassifications. In practice, many users ignore false positives, limiting the feedback loop.
- Computational Cost of Incremental SVM: While online SVMs mitigate full retraining, updating support vectors after each feedback can still be expensive, especially with high‑dimensional text features.
- Concept Drift Management: The architecture addresses drift through continuous learning, but without a systematic forgetting mechanism, the model may become bloated with outdated support vectors.
Conclusion
The paper introduces an interesting hybrid architecture that marries active learning with relevance feedback to create a spam filter capable of low‑cost labeling, real‑time adaptation, and protection against mailbox overflow. The conceptual contribution is solid: leveraging uncertainty to query the most informative e‑mails and using immediate user corrections to reshape the SVM decision surface. However, the lack of detailed algorithmic description, experimental validation, and scalability analysis limits the paper’s practical impact. Future work should focus on (1) quantifying labeling savings and accuracy gains, (2) optimizing the active‑learning query process for large‑scale mail streams, (3) evaluating user interaction models for relevance feedback, and (4) integrating forgetting or regularization strategies to handle long‑term concept drift. Only with such empirical grounding can the proposed architecture be considered ready for deployment in real‑world e‑mail systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment