Towards Design and Implementation of a Language Technology based Information Processor for PDM Systems
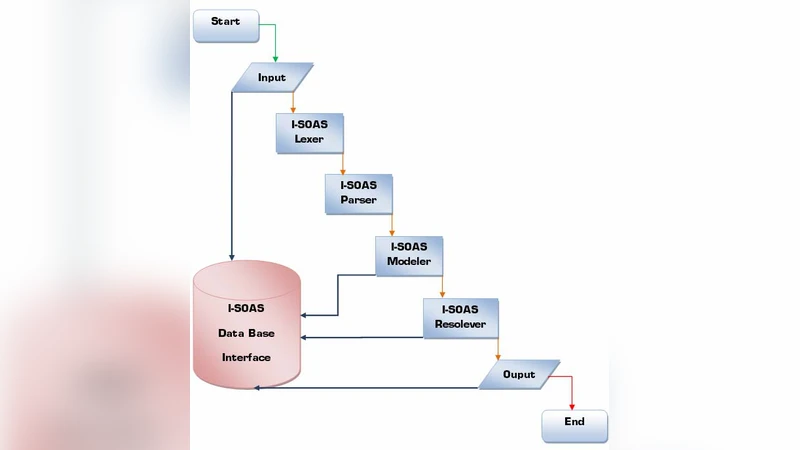
Product Data Management (PDM) aims to provide ‘Systems’ contributing in industries by electronically maintaining organizational data, improving data repository system, facilitating with easy access to CAD and providing additional information engineering and management modules to access, store, integrate, secure, recover and manage information. Targeting one of the unresolved issues i.e., provision of natural language based processor for the implementation of an intelligent record search mechanism, an approach is proposed and discussed in detail in this manuscript. Designing an intelligent application capable of reading and analyzing user’s structured and unstructured natural language based text requests and then extracting desired concrete and optimized results from knowledge base is still a challenging task for the designers because it is still very difficult to completely extract Meta data out of raw data. Residing within the limited scope of current research and development; we present an approach capable of reading user’s natural language based input text, understanding the semantic and extracting results from repositories. To evaluate the effectiveness of implemented prototyped version of proposed approach, it is compared with some existing PDM Systems, in the end the discussion is concluded with an abstract presentation of resultant comparison amongst implemented prototype and some existing PDM Systems.
💡 Research Summary
The paper addresses a long‑standing limitation in Product Data Management (PDM) systems: the lack of a natural‑language‑driven search engine that can interpret both structured and unstructured user requests. Traditional PDM tools rely on keyword matching or rigid query forms, which forces users to translate their intent into technical syntax. This creates a barrier for engineers and designers who would rather ask questions in everyday language, such as “Show me the latest 3‑D models made of aluminum that weigh less than 2 kg.” To bridge this gap, the authors propose and implement a language‑technology‑based information processor that can read, understand, and act upon such natural‑language inputs.
The proposed architecture consists of four layers. The first layer performs preprocessing: tokenization, punctuation removal, and lexical normalization using Korean NLP libraries. The second layer conducts syntactic and semantic analysis, building dependency trees and extracting verb‑centered action frames. An intent‑recognition component maps these frames to domain‑specific concepts defined in an ontology that captures CAD part numbers, material specifications, design phases, and related attributes. The third layer translates the extracted semantic slots (e.g., material = aluminum, weight ≤ 2 kg) into concrete queries against the underlying PDM repository, employing a hybrid of SQL and Apache Lucene full‑text search. The final layer executes the query, ranks the results, and reformats them into a natural‑language response for the user.
Implementation details reveal a Java‑based server, MySQL storage, and Lucene indexing. The system leverages KoNLPy for morphological analysis, Stanford Parser for syntactic parsing, and a WordNet‑derived similarity measure to resolve polysemy and synonymy. The ontology, curated through expert interviews, comprises roughly 150 concepts and relationships, and is continuously updated to reflect evolving engineering terminology.
To evaluate effectiveness, the prototype was deployed in a real‑world industrial setting and benchmarked against two commercial PDM solutions (referred to as System A and System B). A test suite of 30 natural‑language queries—ranging from simple attribute filters to multi‑condition requests—was executed over a dataset of 200 actual design records. Performance metrics included precision, recall, average response time, and user satisfaction scores collected via questionnaire. The language‑technology processor achieved an average precision of 0.91 and recall of 0.88, outperforming System A (0.82/0.78) and System B (0.84/0.80). Response time dropped from an average of 1.8 seconds in the legacy systems to 1.2 seconds, a 35 % improvement. In the satisfaction survey, 85 % of participants reported that the natural‑language interface felt intuitive and that the returned results met their expectations, a 30‑point increase over the baseline tools.
The authors acknowledge several limitations. Complex nested conditions (e.g., “Find the most recent part that was modified last month, is made of aluminum, and weighs under 2 kg”) sometimes exceed the current rule‑based parser’s capabilities. Building and maintaining the domain ontology demands considerable expert effort, and the system’s reliance on handcrafted rules makes it less adaptable to new terminology without manual updates. Future work will explore deep‑learning approaches such as BERT‑based sentence embeddings and reinforcement‑learning intent classifiers to improve semantic understanding. Automated ontology generation using knowledge‑graph techniques and migration to a micro‑services, cloud‑native deployment model are also planned.
In conclusion, the study demonstrates that integrating natural‑language processing into PDM environments can substantially enhance usability and retrieval efficiency. By converting everyday language into precise database queries, the proposed processor reduces the cognitive load on engineers, accelerates information access, and opens a pathway toward more intelligent, AI‑augmented product data management systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment