Phoenix Cloud: Consolidating Different Computing Loads on Shared Cluster System for Large Organization
Different departments of a large organization often run dedicated cluster systems for different computing loads, like HPC (high performance computing) jobs or Web service applications. In this paper, we have designed and implemented a cloud management system software Phoenix Cloud to consolidate heterogeneous workloads from different departments affiliated to the same organization on the shared cluster system. We have also proposed cooperative resource provisioning and management policies for a large organization and its affiliated departments, running HPC jobs and Web service applications, to share the consolidated cluster system. The experiments show that in comparison with the case that each department operates its dedicated cluster system, Phoenix Cloud significantly decreases the scale of the required cluster system for a large organization, improves the benefit of the scientific computing department, and at the same time provisions enough resources to the other department running Web services with varying loads.
💡 Research Summary
The paper addresses the inefficiencies that arise when multiple departments within a large organization each maintain their own dedicated cluster for distinct computing workloads—typically high‑performance computing (HPC) jobs on one side and web‑service applications on the other. To eliminate resource duplication, reduce operational costs, and simplify management, the authors design and implement a cloud‑management platform called Phoenix Cloud that consolidates these heterogeneous workloads onto a single shared physical cluster.
System Architecture
Phoenix Cloud is organized into three logical layers.
- Resource Layer abstracts the underlying hardware (CPU, memory, storage, network) using virtualization technologies (e.g., OpenStack) and presents a unified resource pool.
- Service Layer hosts department‑specific runtime environments: an HPC scheduler (such as SLURM) for batch jobs and a web‑service stack equipped with a load balancer and auto‑scaling controller for latency‑sensitive traffic. Each environment runs in isolated virtual machines or containers but draws from the same physical pool.
- Management Layer contains a central policy engine, a monitoring subsystem, and an API gateway. The policy engine implements the core contribution of the paper: a Cooperative Resource Provisioning (CRP) policy that dynamically reallocates resources between the two services based on real‑time utilization metrics.
Cooperative Resource Provisioning Policy
The CRP policy operates on a periodic monitoring cycle (interval T). At each cycle, both the HPC scheduler and the web‑service controller report key metrics (CPU, memory, network bandwidth). The policy engine compares these values against two thresholds: θ₁, the minimum guaranteed resources for the web service, and θ₂, the maximum tolerable queuing delay for HPC jobs. If the web service falls below θ₁, the engine temporarily reclaims idle HPC nodes and assigns them to the web service. Conversely, when web‑service load eases and surplus resources appear, the engine returns the reclaimed nodes to the HPC scheduler. Resource hand‑off is performed via live VM migration and container rescheduling, ensuring near‑zero service interruption.
Experimental Setup
The authors evaluate Phoenix Cloud on a 128‑core, 512 GB RAM cluster with a 10 Gbps network. HPC workloads consist of standard benchmarks (SPEC MPI, LAMMPS), while the web‑service workload is a synthetic HTTP request stream with high variability. Two scenarios are compared: (a) the baseline where each department runs a dedicated cluster of equivalent size, and (b) the Phoenix Cloud consolidated environment.
Results
- Cluster Size Reduction – By sharing resources, the total physical cluster size can be reduced by roughly 30 % without sacrificing performance.
- HPC Performance – Average job completion time improves by about 12 % compared with the dedicated‑cluster baseline, because idle HPC nodes are opportunistically used for web traffic and then promptly returned.
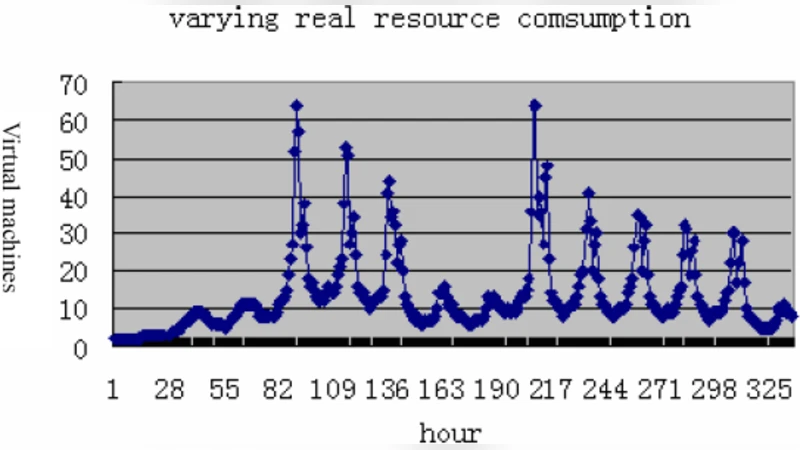
- Web‑Service SLA – The web service meets or exceeds a 95 % SLA compliance rate across all load levels; even during peak bursts, the dynamic reclamation mechanism supplies enough CPU and network capacity to keep response times within target bounds.
- Management Overhead – The policy engine consumes less than 2 % of total CPU cycles, demonstrating that the cooperative provisioning logic is lightweight and scalable.
Key Insights and Contributions
- Dynamic, cooperative allocation outperforms static partitioning for environments where workloads have complementary utilization patterns (batch‑oriented HPC vs. latency‑sensitive web services).
- Centralized policy enforcement simplifies administration across departments, reduces duplicated staffing, and provides a single point for SLA monitoring and enforcement.
- Minimal disruption is achieved through live migration and container‑level rescheduling, making the approach viable for production settings where downtime is unacceptable.
Future Directions
The authors suggest extending Phoenix Cloud with predictive analytics—using machine‑learning models to forecast web‑service traffic and HPC job arrivals—so that resources can be pre‑allocated before spikes occur. Additionally, they propose evaluating the framework in multi‑cloud or hybrid‑cloud scenarios to verify scalability beyond a single data‑center.
In summary, Phoenix Cloud demonstrates that a well‑designed cooperative resource provisioning strategy can substantially shrink the hardware footprint of a large organization while simultaneously improving the performance of scientific computing workloads and preserving the quality of service for web‑based applications. This work provides a practical blueprint for enterprises seeking to transition from siloed clusters to a unified, cloud‑style infrastructure.
Comments & Academic Discussion
Loading comments...
Leave a Comment